
spaCy Internals: Spancat architecture walkthrough
As you already know, I’m a big fan of spaCy’s configuration and project system. It’s a seamless way to integrate your model’s configration into your overall project workflow. So this time, let’s dive deeper and understand what happens under the hood whenever we initialize a pipeline.
This blog post will walk you through how to initialize a span categorizer
(spancat) pipeline manually. By that, I
mean taking advantage of spaCy’s registry system. If you’re a spaCy user, I find
no practical application in this—I only use this method for debugging
purposes as a spaCy developer (for curiosity’s sake). But I decided to write
about this topic to
appreciate the neatness of spaCy’s API design, and maybe you can use this
pattern in your tools too!
Note: after publishing I noticed that the diagrams are too small when you view them in mobile, sorry about that! It might take some time for me to update them so no promises! The illustrations are high-res though, so you can open them in a new tab as we go along.
The catalogue library
First things first, spaCy’s registry system is managed by the catalogue library. It allows us to create serializable function callbacks. So let’s say we’re writing a module that loads different types of data (e.g., PDF, PNG, JEPG) for a document processing workflow. One way to do that is to write a handler for every data type:
from pathlib import Path
def handle_pdf(path: Path):
# pdf specific logic
return something
def handle_png(path: Path):
# png specific logic
return something
def handle_jpeg(path: Path):
# jpg specific logic
return something
Then you might have a function that takes an arbitrary data type and a specific handler:
from pathlib import Path
from typing import Callable
def load_data(path: Path, handler: Callable):
something = handler(path)
return something
# Usage: load_data("path/to/file.pdf", handler=handle_pdf)
This design is neat and acceptable, but we cannot create serializable
records (read: something you can log into a file, save into JSON,
pickle or
joblib,
etc.) for these functions because Callable objects are not so straightforward
to serialize.1 This becomes important when you want to “save” the settings for a particular function and reuse them later.
The catalogue library solves this by registering your function so that you can
just use strings as your handler parameter.
import catalogue
loaders = catalogue.create("my_project", "loaders")
The loaders Registry
acts as an intermediate object for registering and retrieving functions. You can
use it as a decorator for your custom loaders:
from pathlib import Path
from my_scripts import loaders # type: Registry
@loaders.register("pdf")
def handle_pdf(path: Path):
# pdf specific logic
return something
@loaders.register("png")
def handle_png(path: Path):
# png specific logic
return something
@loaders.register("jpg")
def handle_jpeg(path: Path):
# jpg specific logic
return something
We can then rewrite the main handler to use strings (str ) instead
of functions:
from pathlib import Path
from my_script import loaders
def load_data(path: Path, handler_id: str):
# We're now using the handler_id to retrieve the correct handler
handler = loaders.get(handler_id)
something = handler(path)
return something
# Usage: load_data("path/to/file.pdf", handler_id="pdf")
Factory design pattern
The factory design pattern takes advantage of this setup. For example, if you have a function that takes additional parameters, then you can use them to set up a factory so that the resulting function behaves in a certain way:
@loaders.register("pdf")
def build_pdf_handler(page_num: int, n_jobs: int) -> Callable:
def _pdf_handler(path: Path):
pages = load_pages(path, n_jobs=n_jobs)
page_to_load = pages[page_num]
# other pdf specific logic
return something
return _pdf_handler
# Usage:
# > pdf_handler_factory = loaders.get("pdf")
# > pdf_handler = pdf_handler_factory(page_num=1, n_jobs=3)
# > pdf_handler("path/to/file.pdf")
This design pattern makes up the bulk of spaCy’s pipeline initialization process. In the next section, we’ll look into the spancat architecture and build the pipeline manually using the registry system.
Spancat architecture walkthrough
Now we’ll see catalogue in action in spancat. If this is the first time you
heard about spaCy’s SpanCategorizer,
then head over to this blogpost for a brief
overview.2 In summary, spancat is
a highly-configurable component that performs span labelling à la
NER. It does more than NER though because it can handle overlapping, long, and
fragmented spans. Its architecture looks like this:
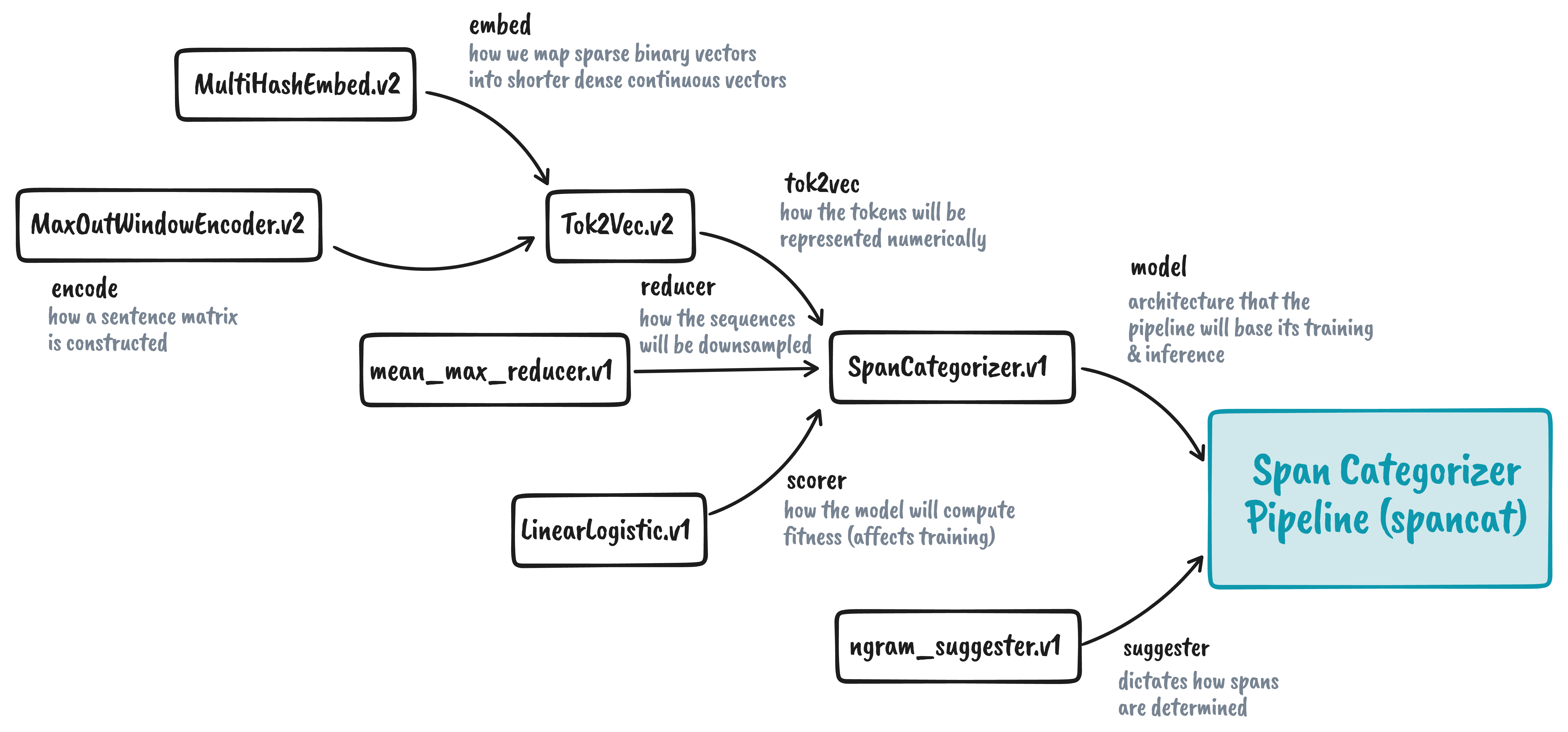
It looks complex now, but if we start from the very right, we see our end goal,
i.e., to initialize the Span Categorizer (spancat)
pipeline.
Doing so requires a suggester and a model, with the latter requiring a
tok2vec, reducer, and so on. We’ll go through the whole dependency chain as
we go.
Let’s first load the registry, and create example
Doc objects:
import spacy # as of writing, I'm using v3.3.1
reg = spacy.registry # shorthand
For the texts, let’s have two sentences:
from typing import List
from spacy.tokens import Doc
import spacy
nlp = spacy.blank("en")
texts = ["A short sentence.", "Welcome to the Bank of China."]
docs: List[Doc] = list(nlp.pipe(texts))
Suggester function
Let’s start with the suggester function because it has no dependencies. In
spancat, the suggester function suggests candidate spans that we will feed
later on into a multilabel classifier for labelling. The simplest way to suggest
spans is to sweep with a window of a fixed n-gram length (ngram_suggester.v1).
suggester_factory = reg.get("misc", "spacy.ngram_suggester.v1")
suggester: Callable = suggester_factory(sizes=[1, 2, 3])
The factory approach is similar to our earlier example in build_pdf_handler.
However, this time, we now have access to the suggester function, and we can
pass any Doc objects (Iterable[Doc]) to see their candidate spans. Let’s do
that now:
candidates = suggester(docs)
print(candidates)
# > Ragged(
# > data=array([
# > [0, 1], [1, 2], [2, 3], [3, 4], [0, 2], [1, 3], [2, 4], [0, 3], [1, 4],
# > [0, 1], [1, 2], [2, 3], [3, 4], [4, 5], [5, 6], [6, 7], [0, 2], [1, 3],
# > [2, 4], [3, 5], [4, 6], [5, 7], [0, 3], [1, 4], [2, 5], [3, 6], [4, 7]], dtype=int32),
# > lengths=array([ 9, 18], dtype=int32),
# > data_shape=(-1, 2),
# > starts_ends=None
# > )
The suggester function gave us a list of start and end indices in the
candidates.data attribute and the number of candidates per document in
candidates.lengths. We can view the spans by indexing through the document:
## View the spans for the first document: 'A short sentence.'
RELEVANT_DOC_IDX = 0 # because 'A short sentence is the 0th element in the list
doc = docs[RELEVANT_DOC_IDX]
print(doc.text)
num_candidates: int = candidates.lengths[RELEVANT_DOC_IDX]
window_idxs: Iterable[Tuple[int, int]] = candidates.data[:num_candidates].tolist()
for span_idx, (start, end) in enumerate(window_idxs):
print(f"Span {span_idx}: {doc[start:end]}")
# > A short sentence.
# > Span 0: A
# > Span 1: short
# > Span 2: sentence
# > Span 3: .
# > Span 4: A short
# > Span 5: short sentence
# > Span 6: sentence.
# > Span 7: A short sentence
# > Span 8: short sentence.
As expected, the candidate spans are simply the n-gram sweeps of the document. In spacy-experimental, you can access other suggesters based on a text’s linguistic attributes. There’s also the SpanFinder that learns span boundaries and suggests fewer but more precise candidates.
Model
So far, we already have a suggester. This box is now grayed out in the
illustration below. The next step is to create our model. However, its
parameters also require us to initialize other components, namely the
tok2vec, reducer, and scorer. Let’s start with tok2vec.
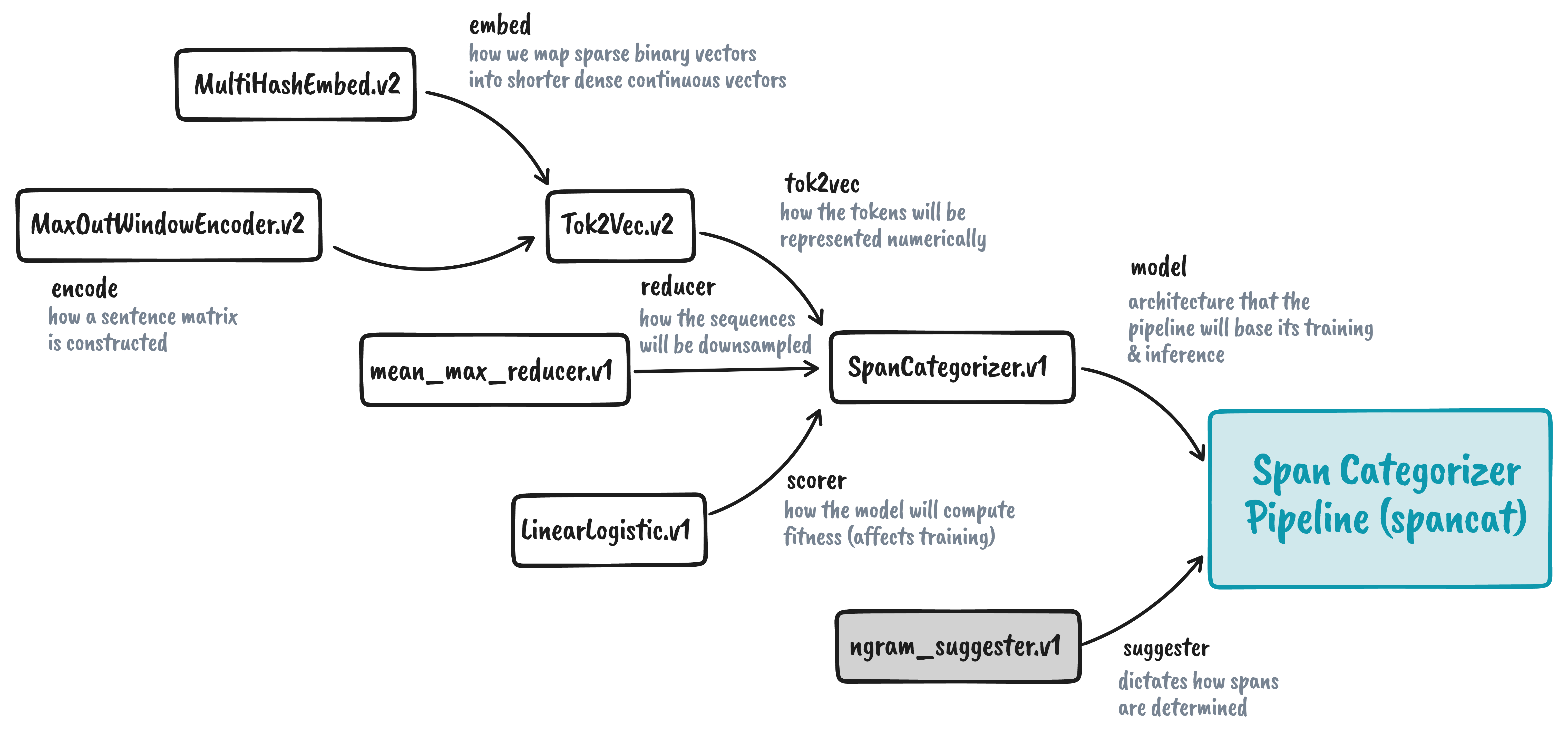
For spancat, we will use the built-in spacy.Tok2Vec.v2
architecture for the tok2vec
parameter. However, it also requires us to pass something in its embed and
encode parameters. For embed we will be using
spacy.MultiHashEmbed.v2
and for encode we will be using
spacy.MaxoutWindowEncoder.v2.3
# Get factories
tok2vec_factory = reg.get("architectures", "spacy.Tok2Vec.v2")
embed_factory = reg.get("architectures", "spacy.MultiHashEmbed.v2")
encode_factory = reg.get("architectures", "spacy.MaxoutWindowEncoder.v2")
# Construct components
embed = embed_factory(
width=96,
rows=[5000, 2000, 1000, 1000],
attrs=["ORTH", "PREFIX", "SUFFIX", "SHAPE"],
include_static_vectors=False,
)
encode = encode_factory(
width=96,
window_size=1,
maxout_pieces=3,
depth=4,
)
# Assemble
tok2vec = tok2vec_factory(embed=embed, encode=encode)
With this, we now have a tok2vec network to pass to the
spacy.SpanCategorizer.v1 model. The remaining parameters are the reducer
and the scorer.
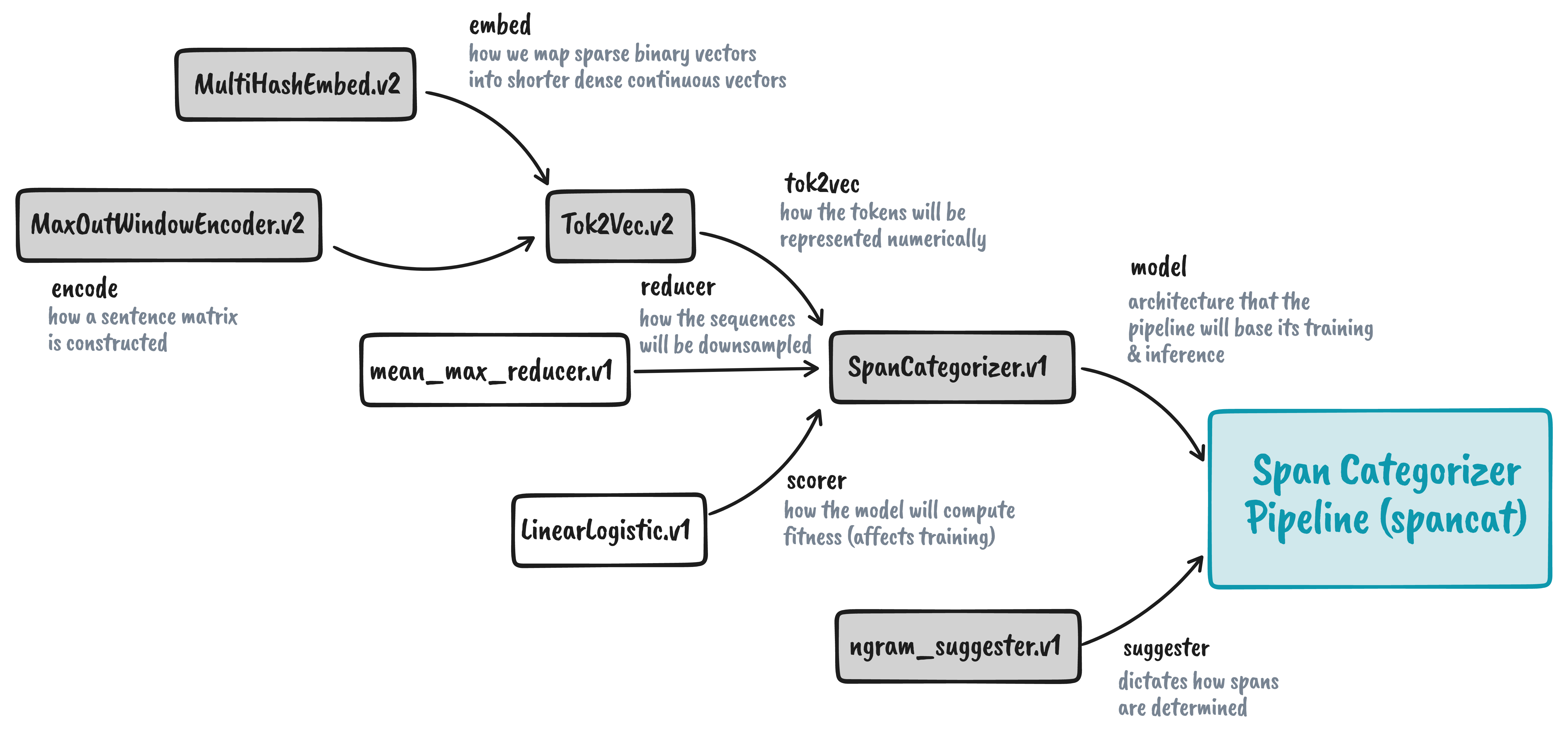
We will follow the same process for the last two: we get the factories and then construct the components:
# Get factories
reducer_factory = reg.get("layers", "spacy.mean_max_reducer.v1")
scorer_factory = reg.get("layers", "spacy.LinearLogistic.v1")
# Construct components
reducer = reducer_factory(hidden_size=128)
scorer = scorer_factory()
And because we now have the tok2vec, reducer, and scorer, we can assemble
them together for the spancat model:
model_factory = reg.get("architectures", "spacy.SpanCategorizer.v1")
model = model_factory(tok2vec=tok2vec, reducer=reducer, scorer=scorer)
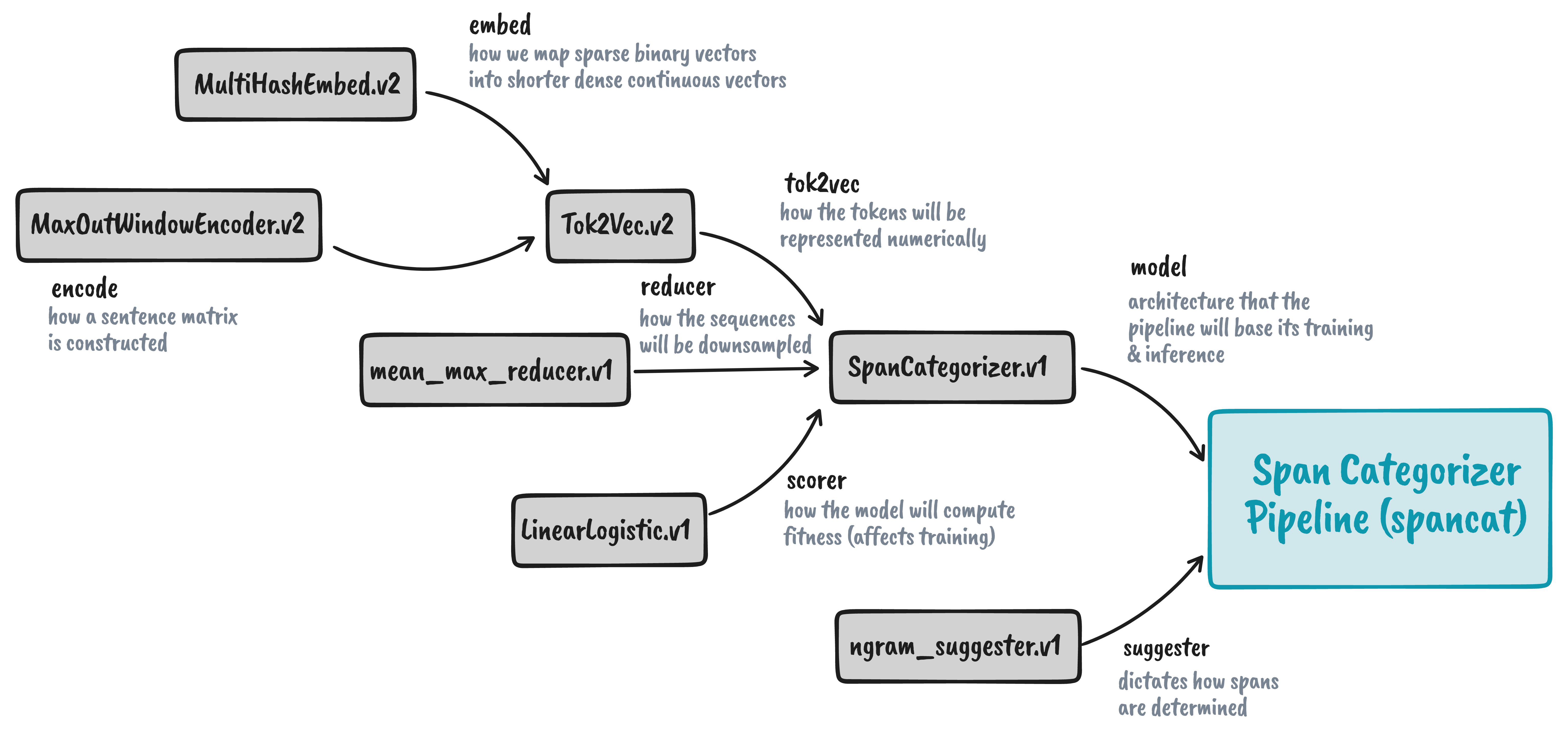
Pipeline
Now that we have the model and suggester, we can finally assemble the
spancat pipeline. There are other parameters we need to provide like nlp,
but we don’t need to construct any of them unlike the previous components.
Optionally, we can also add a Scorer to store our results. We need to construct from
a factory again but this should be quick and easy:
spacy_scorer_factory = reg.get("scorers", "spacy.spancat_scorer.v1")
spacy_scorer = spacy_scorer_factory()
What spacy.spancat_scorer.v1 does is that it adds the spans_sc_{} values in
the spacy.Scorer so that it gets reported
during training and evaluation. The component itself does not affect the model,
it only reports what the original scorer, i.e., spacy.LinearLogistic.v1, has
computed.
With that out of the way, let’s create our pipeline:
pipeline_factory = reg.get("factories", "spancat")
pipeline = pipeline_factory(
nlp=nlp, # a blank:en pipeline
name="spancat",
threshold=0.5,
spans_key="sc",
max_positive=None,
# These are the two that we constructed earlier
model=model,
suggester=suggester,
# The optional spaCy scorer
scorer=spacy_scorer
)
# Initialize the pipeline for training
pipeline.initialize(lambda: [], nlp=nlp)
From here, we can now access anything in the SpanCategorizer
pipeline. For example, we can train our
model by calling the pipeline.update function. However, it’s more ideal to use
the training and config system for that
purpose.
Final thoughts
In this blog post, we went through spaCy’s internals by initializing the
spancat pipeline through the registry system. We also learned about the
catalogue library that handles this
process and the factory design pattern it enables.
Perhaps the question you’re asking is: so what? These processes happen under the hood, so there’s no need to bother ourselves with it, right? Personally, I find it a fun exercise to go through the library’s intricacies. As a developer, being able to access the components through the registry allows me to:
- Debug components by piecemeal: if I’m writing a suggester function, I don’t
need to spawn a spaCy project just to see how it works. I will just call
reg.get("misc", "my_custom_suggester.v1")for testing. - Understand that I can substitute any component in the spancat pipeline for
another. For example, I can change the scorer function to
Softmaxinstead ofLinearLogistic. - Appreciate how custom components in spaCy work. The registry API design is quite neat because it allows extensibility not only for library developers but also for users. It’s another design pattern I can add to my toolbelt when writing libraries!
I hope you enjoyed reading this blog post as much as I enjoyed writing it. If you have any questions, feel free to post a comment below.
-
You can probably use dill for serialization, or serialize the function’s bytecode. However, these things are tricky as compared to just using strings. ↩
-
While you’re there, why not check out this awesome video that applies span categorization in a practical use case. ↩
-
I encourage you to read the “Embed, encode, attend, predict” blog post from Explosion to see the theoretical background behind the
embedandencodedesign. ↩