
A framework for designing document processing solutions
Extracting information from PDFs and scanned documents may not be the hottest problem of the century. You don’t generate paintings nor control robots to play games. It’s pure busywork, something that “AI” has promised to automate but failed to achieve. That’s why I’m interested in document processing, the task of converting analog data into digital format, as it evokes a subtle challenge—a problem statement so simple yet tough to solve.
Document processing, the task of converting analog data into a digital format—a problem statement so simple yet tough to solve.
After working with different organizations, I realized that document processing is ubiquitous—from corporations to NGOs, small organizations to large conglomerates— there’s always a PDF that needs to be digitized! Solving this problem even has significant ramifications: archival climate data that can help scientists understand the growing global crisis is locked in paper documents. So document processing is not just hard; it may also be urgent.
Anyone with experience in OCR or AI/ML looking for a challenge to solve which would help climate science?
— Ed Hawkins (@ed_hawkins) August 31, 2019
We have thousands of pages of historical weather observations which need numerical values extracting efficiently & accurately so we can better understand extreme weather. pic.twitter.com/QKcCwPCxWm
This blog post describes a framework for designing document processing solutions. It has three principles:
-
Annotation is king: there is no silver bullet. Even in the presence of a good model, you still need to finetune with your data. Ideally, you’d want an annotation tool with finetuning built-in or flexible enough to incorporate this mechanism.
-
Make multimodal models: we don’t just rely on text whenever we analyze a document. Instead, we take all information (position, text size, etc.) as context. Being able to use all these features is vital. A pure OCR (optical character recognition) or a pure text-based approach is suboptimal to solve this task.
-
Always be correcting: OCR and document layout models aren’t always perfect, so it’s essential to keep the human-in-the-loop to correct your system’s outputs. You can use correction to retrain your model or as the penultimate step before saving the results in a database.
We’ll see this framework in action as we go through my sample implementation using Prodigy and Hugging Face in the next section.
Framework in action: form understanding
We’ll focus on the task of form layout analysis. Unlike tables, forms vary in their template, confusing even the most complex business rules. We will be using the FUNSD (Form Understanding in Noisy Scanned Documents) dataset for this task. It consists of noisy scanned documents where the challenge is to determine the header, question, answer, and other relevant information.
FUNSD: Form Understanding in Nosy Scanned Documents is a dataset for text detection, optical character recognition, spatial layout analysis, and form understanding.

Figure: An example of the FUNSD dataset by Guillaume et al.
If I were to design a solution that incorporates all the principles above, then it would look like the figure below. It’s a diagram of how I envision a typical document processing workflow:
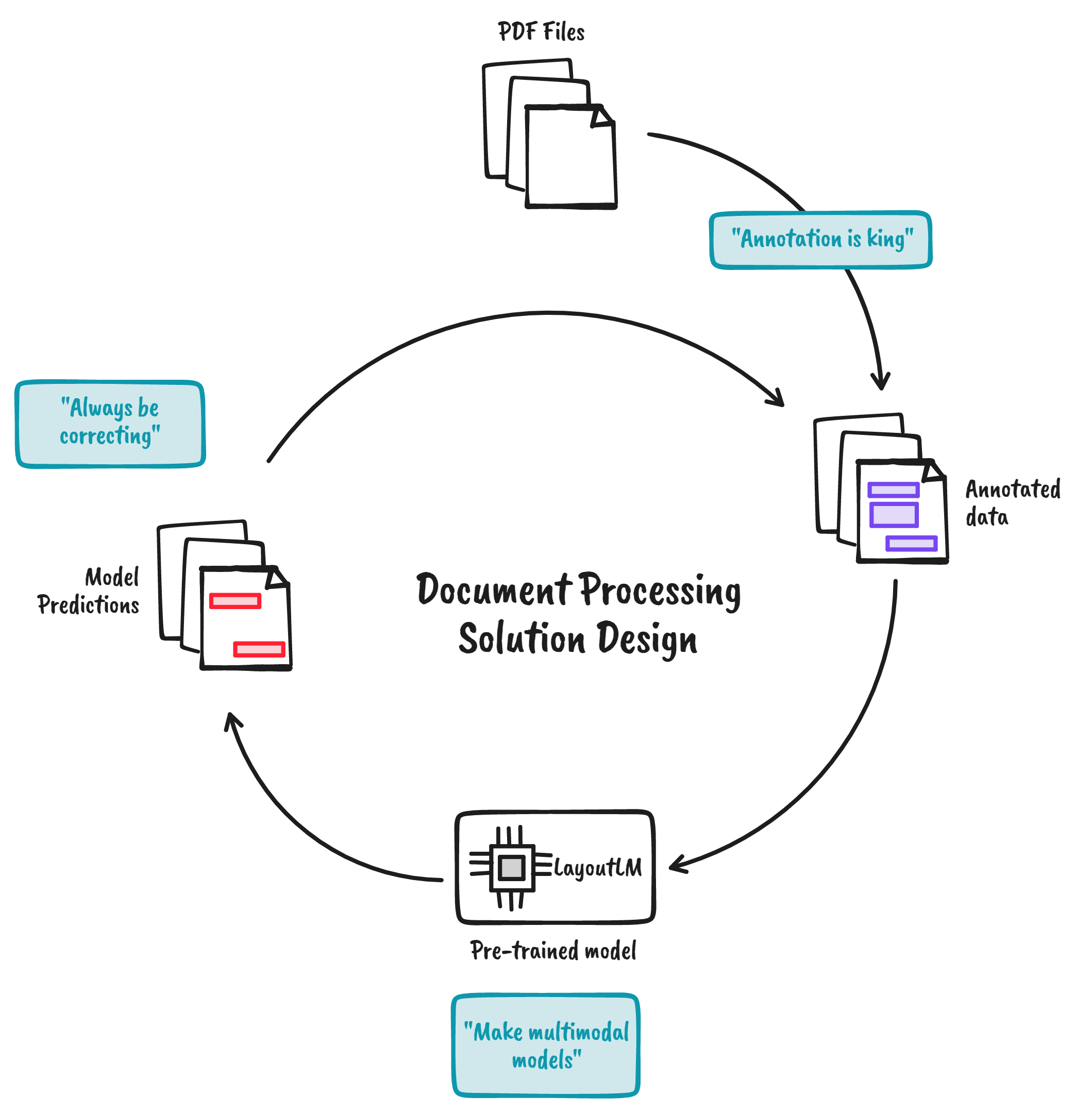
Figure: Document processing solution design principles
Notice how each step corresponds to a particular design principle. To implement this solution, I will be using Prodigy and the LayoutLMv3 model from Hugging Face. Prodigy is an annotation tool that allows us to write custom scripts tailor-fit to my problem (for full disclosure, I currently work at Explosion). By translating the principles above into Prodigy recipes, I can come up with the following figure:
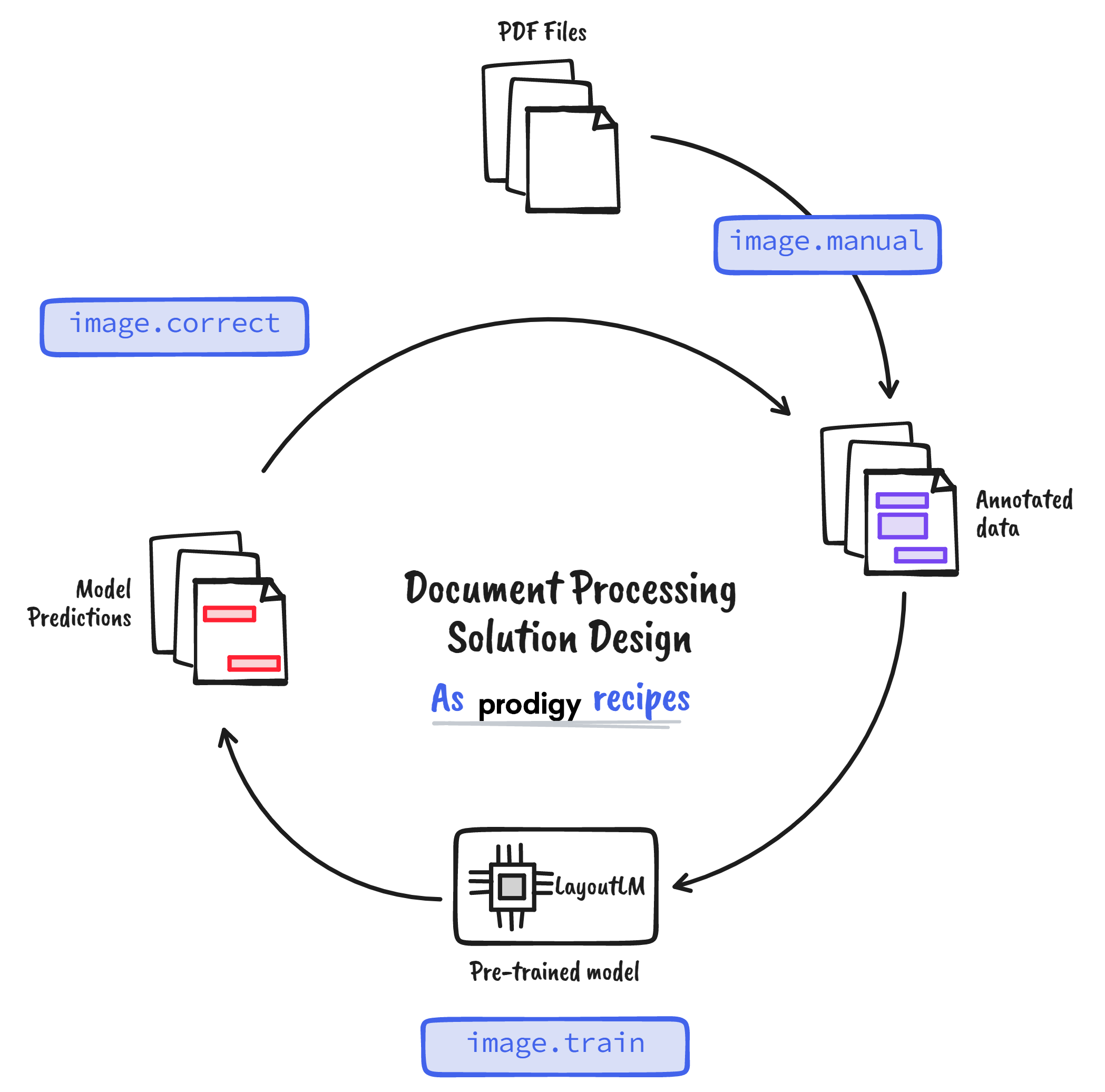
Figure: Document processing solution design principles as Prodigy recipes
Here are the Prodigy recipes we will use:
image.manual: is a built-in recipe that allows us to load images from a directory and add bounding box annotations.image.train: is a custom recipe that finetunes a LayoutLMv3 model given an annotated dataset.image.correct: is a custom recipe that takes in a finetuned LayoutLMv3 model and a directory of test images for correction and quality assurance.
You can find a sample implementation of these recipes in this Github repository:
Annotation is king
Annotation is always a given in any document processing solution. Documents tend to vary wildly in appearance, even if they have distinguishable patterns. So you’d want an annotation tool that allows you to label documents reliably.
In Prodigy, this functionality is already built-in using the image.manual
recipe. Given a directory of images, we can draw bounding boxes or freeform
polygons to label specific regions. For FUNSD, it looks like this:
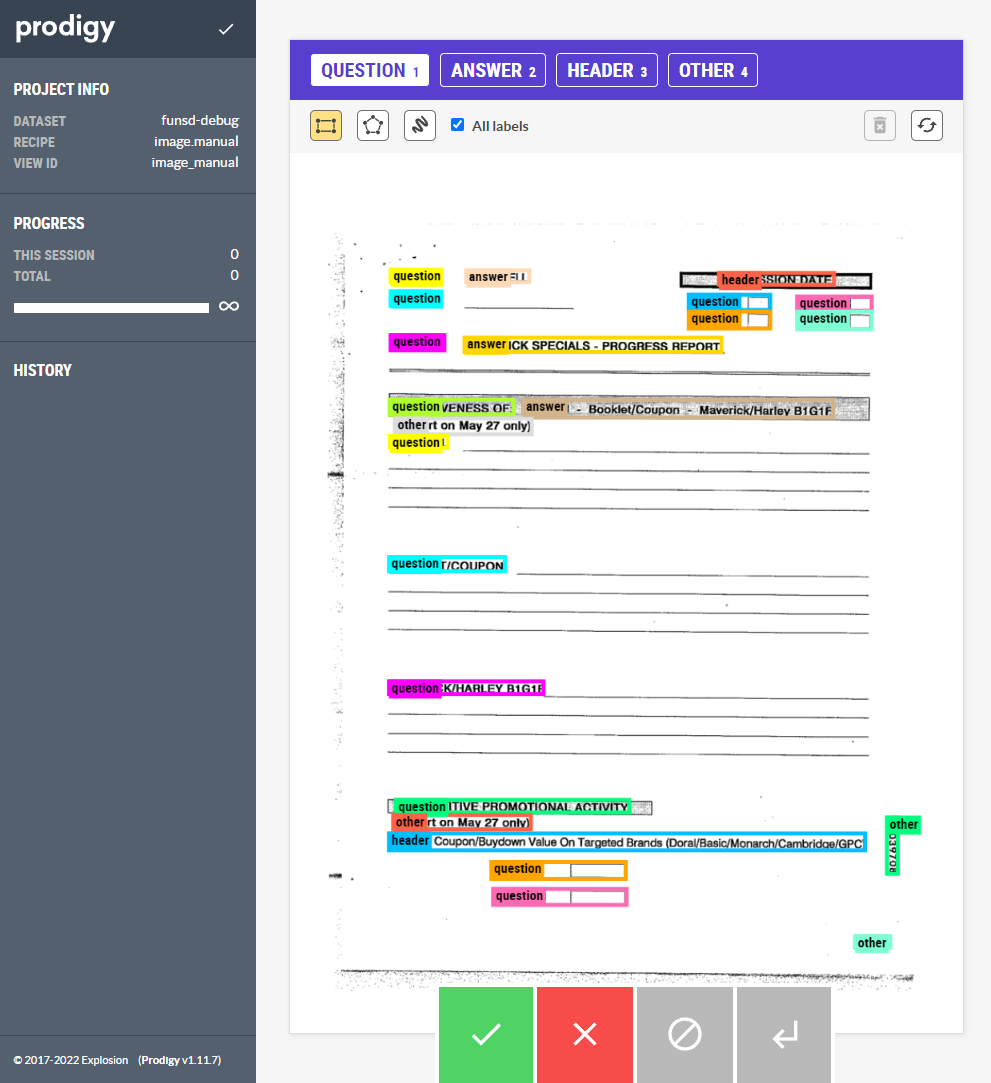
Figure: The image.manual annotation interface in Prodigy.
Whenever we label, Prodigy stores the annotations in a
database. Because FUNSD already has
annotations, we don’t need to label anymore. So instead, I will hydrate the
database with the annotated values to recreate the scenario. The hydrate-db
command
from the project
repo illustrates
this process.
One limitation of this approach is that we didn’t do OCR because the text data
is already available. The image.manual recipe only stores the bounding boxes
and the labels. However, we can solve this by creating a custom recipe that
performs OCR to give us bounding boxes and an interface that allows us to label
each bounding box with a corresponding value. I’ll be creating a sample project
that demonstrates this in the future.
Make multimodal models
Another reason why document processing is such an appealing problem is that it is inherently multimodal—textual and visual information is readily available for us to use. But unfortunately, crude document processing solutions tend to take advantage of only one type:
- Image-centric approaches involve a lot of complex business rules surrounding bounding boxes and text placement to get the required info. They often end up relying on templates that may not be scaleable.
- Text-centric approaches run on NLP pipelines on OCR’d text. However, blobs of text are incompatible with the domain these models were initially trained from, causing suboptimal performance.
Fortunately, multimodal models like LayoutLMv3 (Huang, et al., 2022) can learn from textual and visual information. For a given document, it embeds not only the word and image themselves, but also their positions. Then, it learns the interactions across them using multiple pre-training objectives.
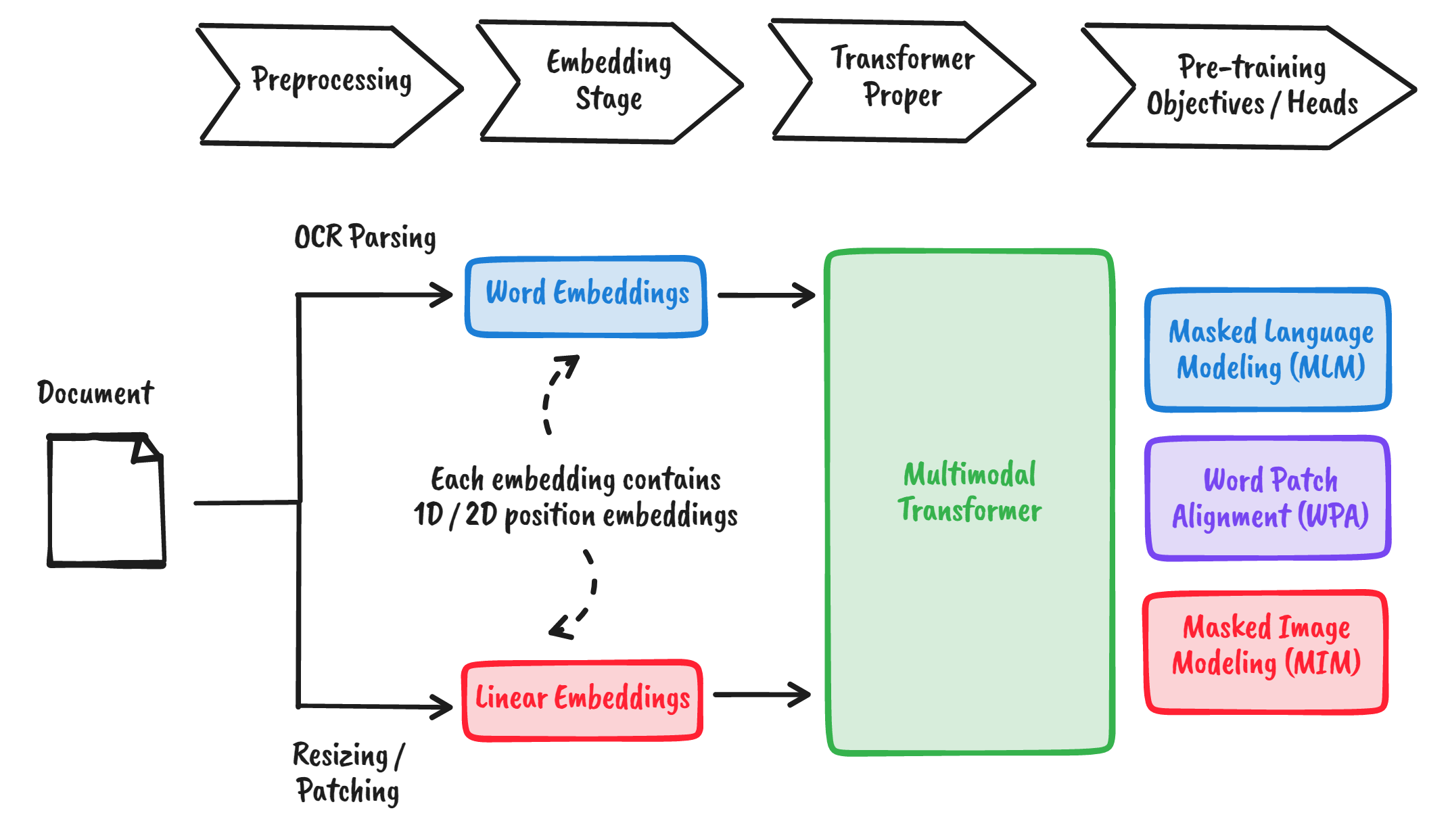
Figure: The LayoutLMv3 model learns from both textual and visual information and learns the interactions between them
The Hugging Face transformers
library allows us to finetune a
LayoutLMv3 model without fuss. In the Github project, I included the training
script as a Prodigy recipe
(image.train).
The only challenging part was to convert the data from the Prodigy format into
Hugging Face’s
Dataset
class. Once done, training is quite a breeze.
Before wrapping up this section, note that LayoutLMv3 is just one of the many models that can parse document layout. For example, you have DocFormer (Appalaraju, et al., 2021), SelfDoc (Li et al., 2021), and many others. This means that you can switch out any architecture you want without affecting the general flow.
Always be correcting
I still believe that even with the best-performing document processing system, you still need to integrate human knowledge and experience for correction and evaluation. Human-in-the-loop can serve as the final check for a model’s output. We can reuse the corrected annotations to finetune the model further, thus closing the loop.
Prodigy implements this approach in most NLP-based recipes. For example, the
ner.correct recipe for named
entity recognition allows us to create gold-standard data by correcting a
model’s suggestions. We will be implementing a similar recipe for images,
namely, with the image.correct recipe.
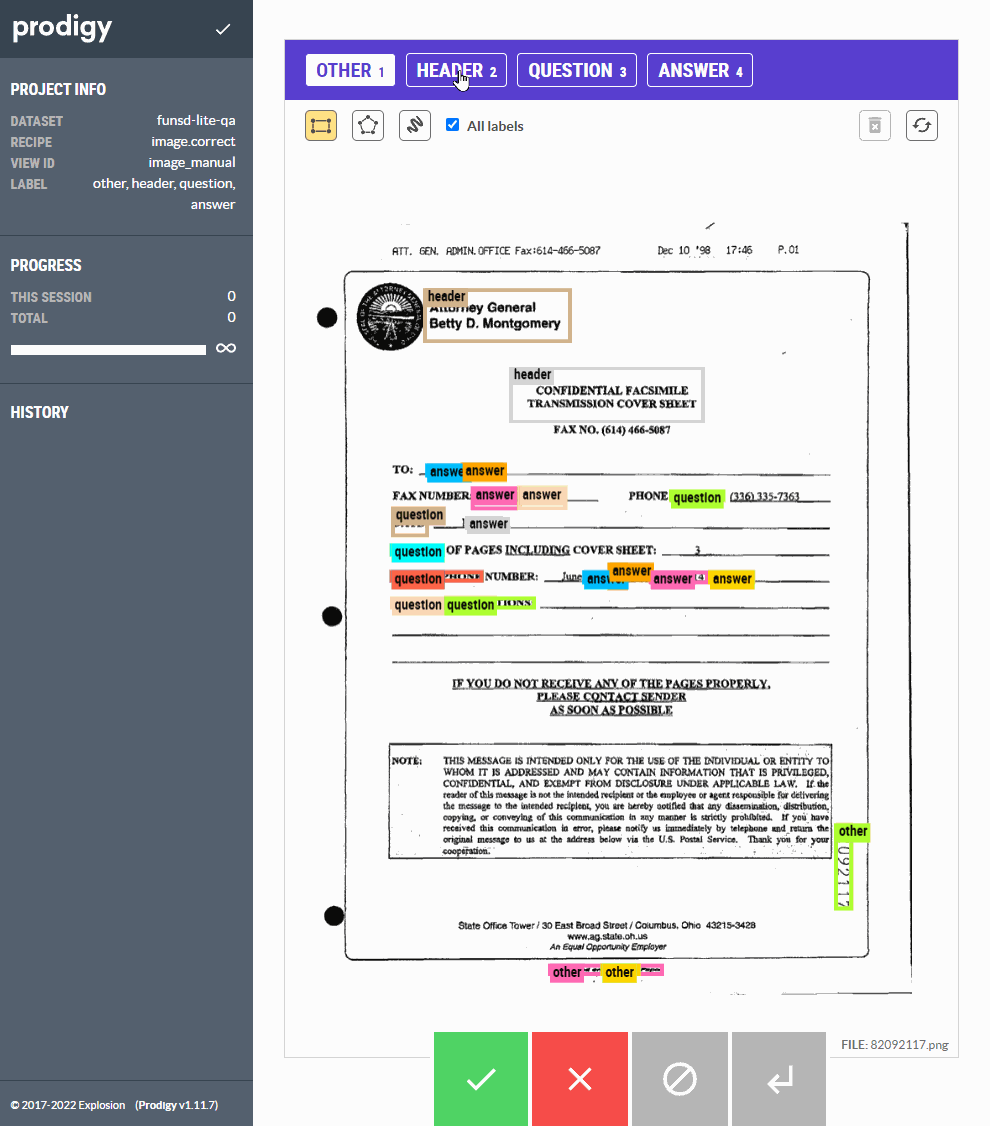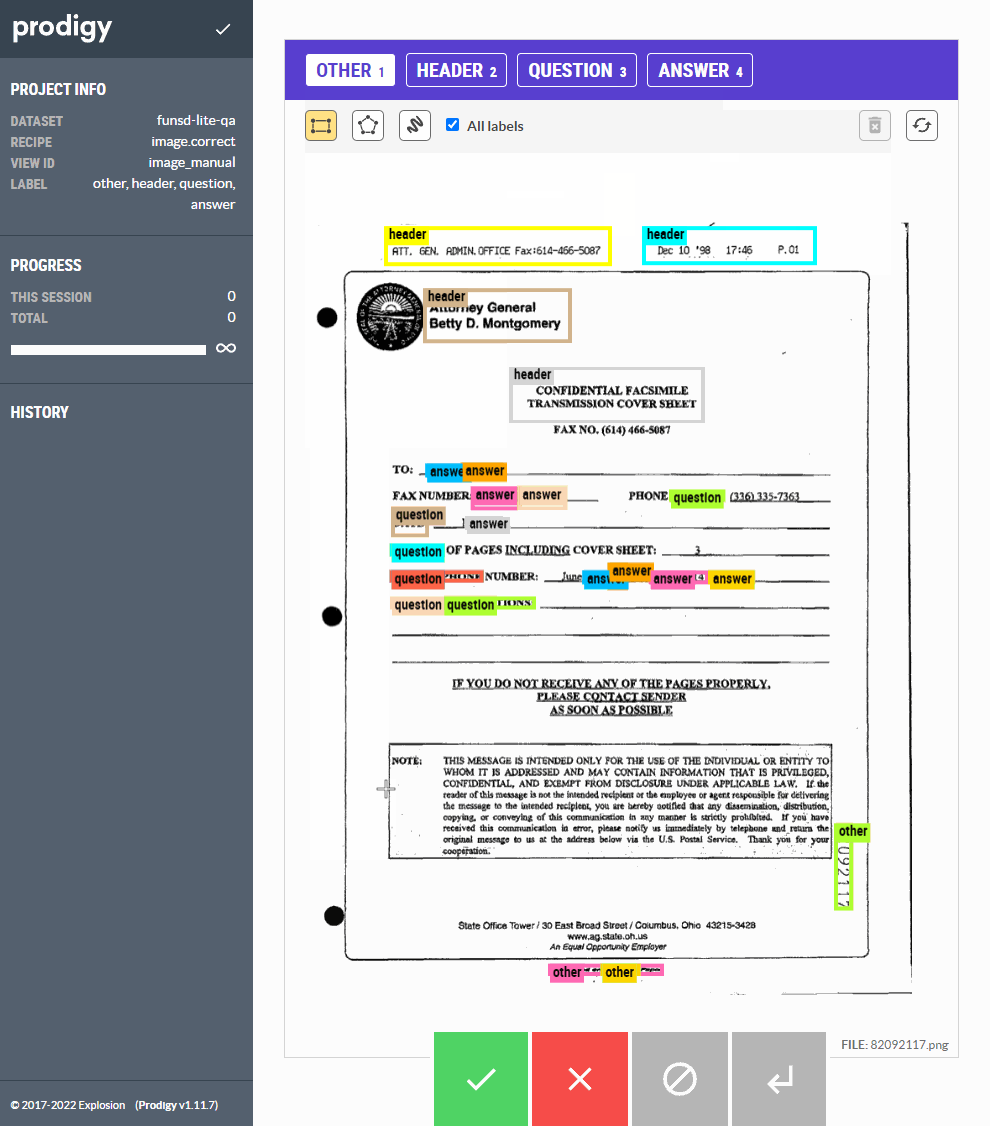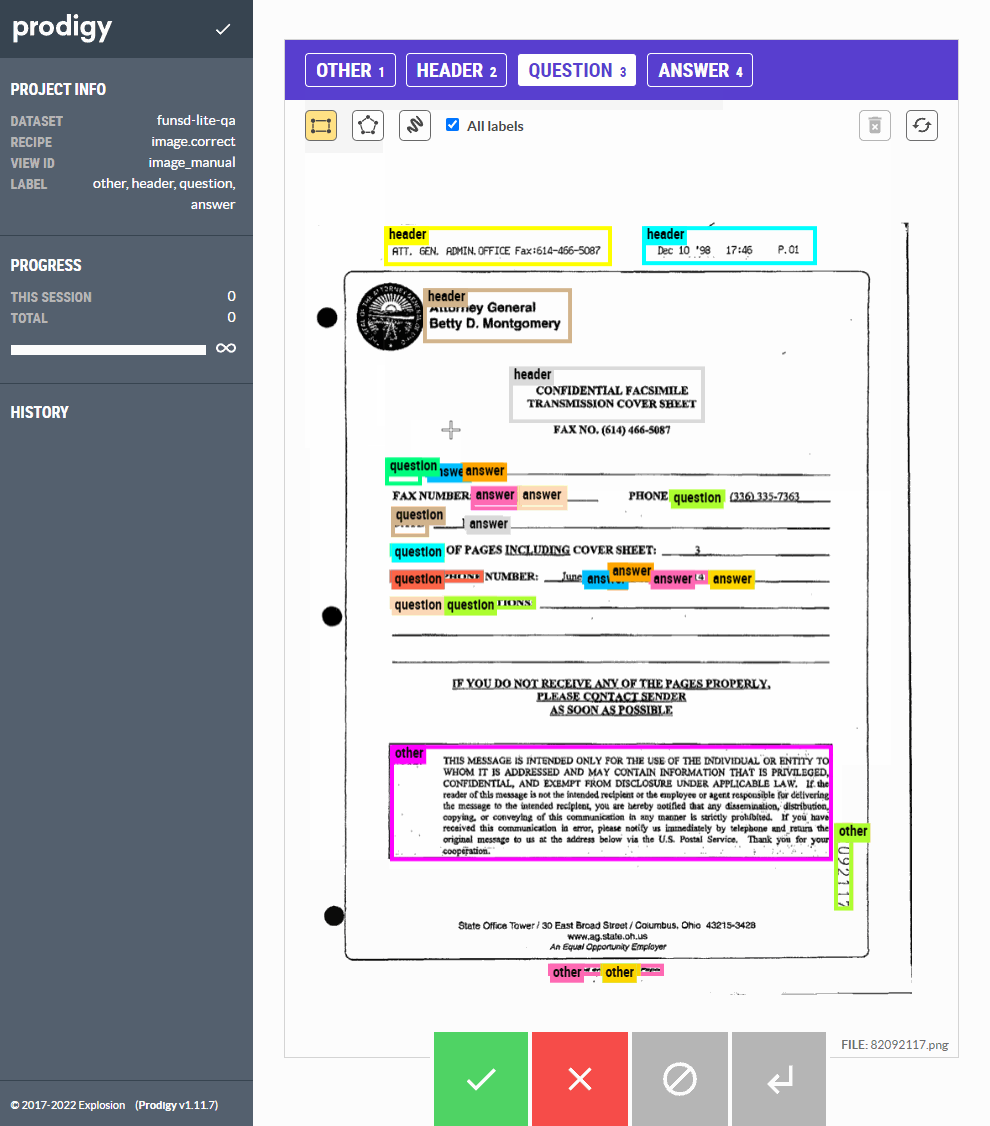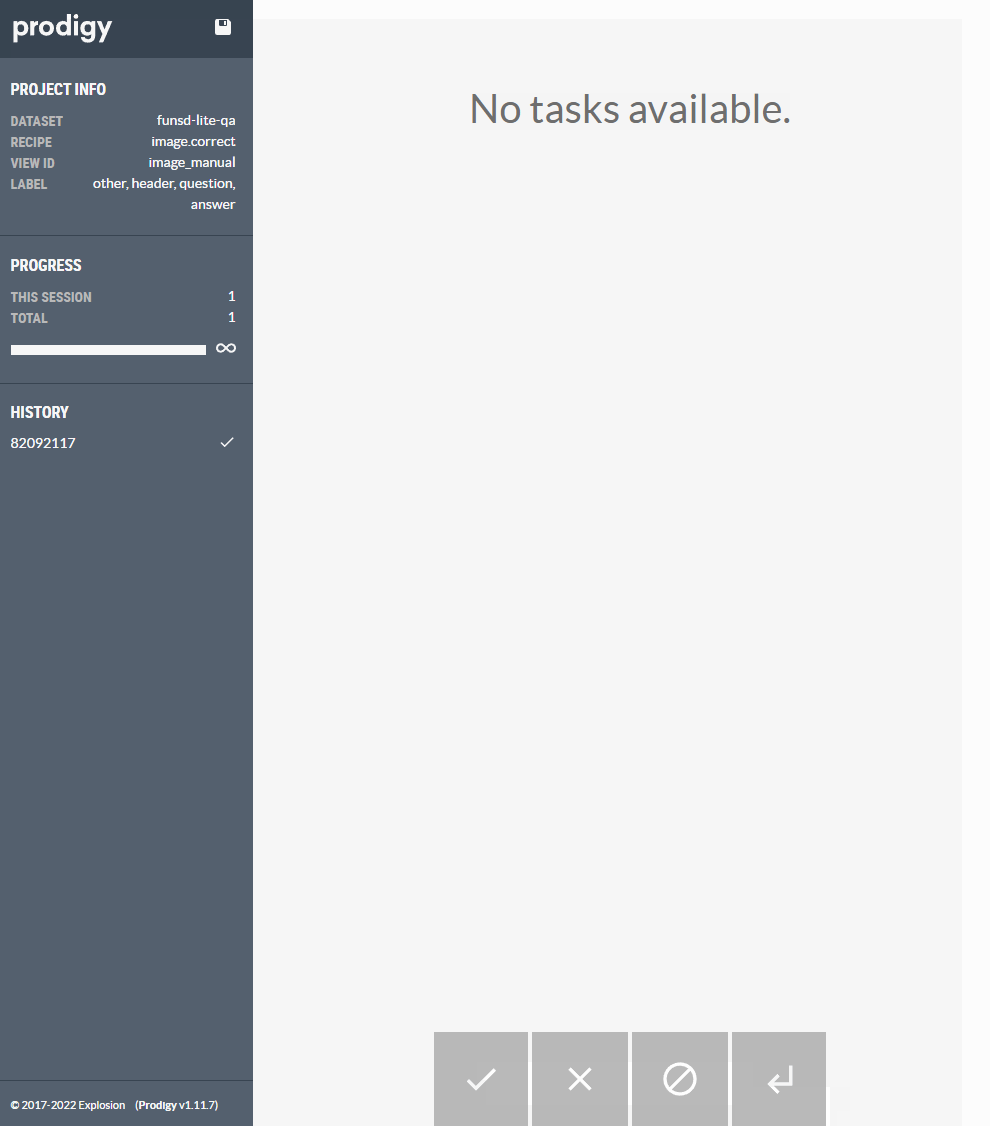
Figure: Using the image.correct custom recipe, we can correct the model annotations before saving it to the database
Note that the example above follows a streaming pattern: the model performs
inference for every image it comes across. This pattern is helpful if you’re
correcting in real-time or getting the images from an external API. On the other
hand, you can also correct by batch. Here, you can let the model perform batch
inference on a finite set of data, convert it to Prodigy’s data
format, and use the built-in
image.manual recipe for correction.
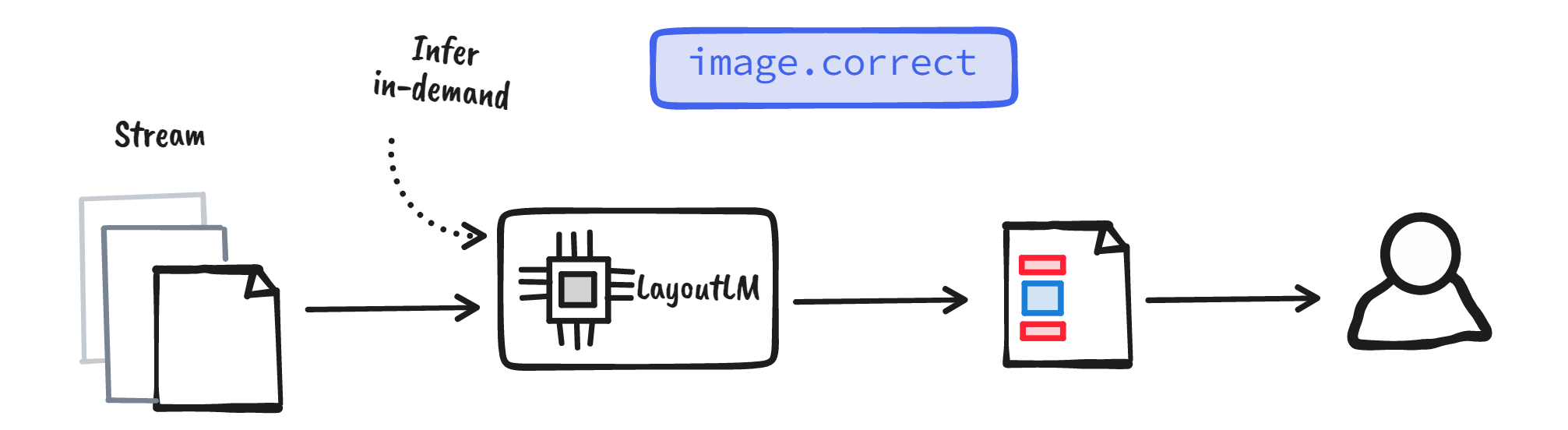
Figure: Streaming approach for correction. Model performs inference for every single image in the stream
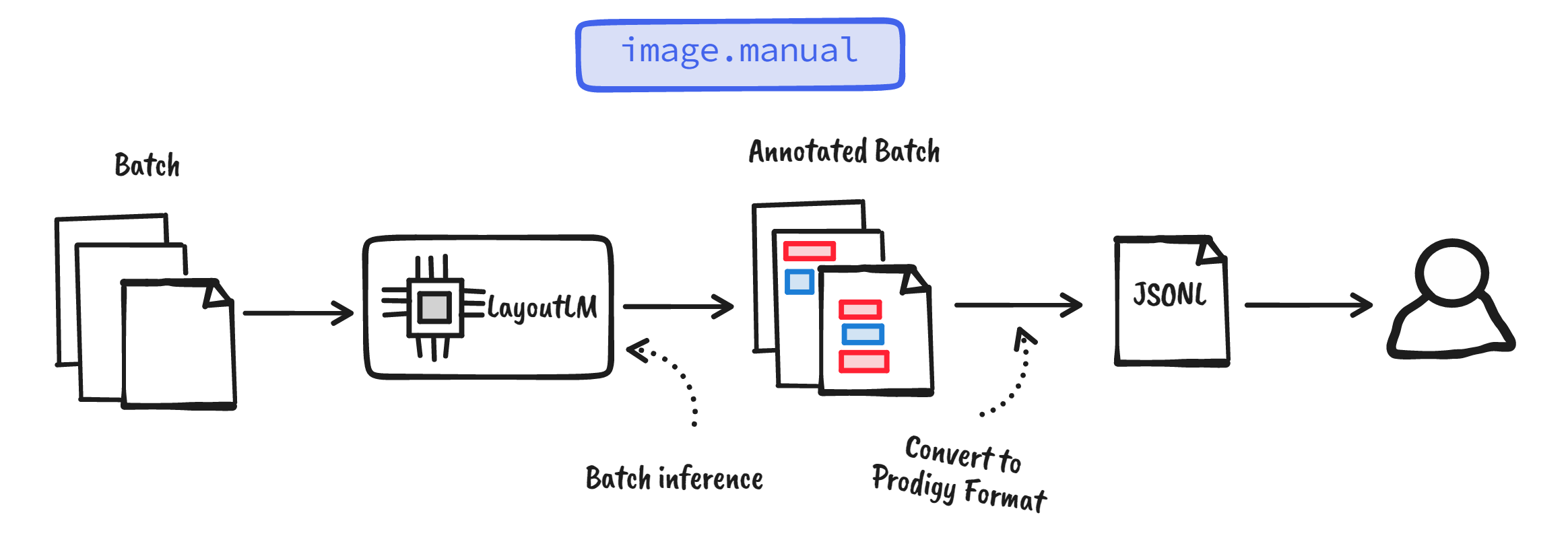
Figure: Batch approach for correction. Model performs batch inference, then we convert the annotations into
the Prodigy format then pass it on to the image.manual recipe.
Final thoughts
This blog post describes what I think are the most critical aspects of a document processing solution: an annotation mechanism, a multimodal model, and an evaluation step. I also demonstrated them in action using Prodigy and LayoutLM.
Machine learning was promised to automate manual labor. But it seems that we hit a wall and started automating creative endeavors instead. My take is that we optimized research for silver-bullet solutions: feed one big model with input, and you get the desired output. Manual labor, such as document processing, isn’t like that. Instead, they tend to be bespoke: you need to label data, you need to consider all elements of your document, you need to correct your model’s output—and one big model won’t cut it.
I hope that this framework can help you in your automation challenges. Feel free to drop a comment below to share your thoughts!