Research
My field is in natural language processing and machine learning. I explore how we can build equitable language technologies through cheap, small, and specialized language models that can be deployed at the edge, i.e., nearest to the communities who need these technologies the most.
I believe that good data is the foundation for building these models, especially when working with low-resource languages where data is scarce and quality matters more. I’m excited about techniques that involve creative (or in Tagalog, ma-diskarte) ways to obtain high quality signals given these extreme constraints. That said, I’m always open to learning new approaches!
Below is a selection of work that reflects my current interests. My work has been published in top NLP conferences such as ACL, NAACL, and EMNLP. I’m always excited for potential internships or research visits, so just reach out if you find me a good match!
Selected Publications
Keywords: data-centric NLP, multilinguality, resources & evaluation
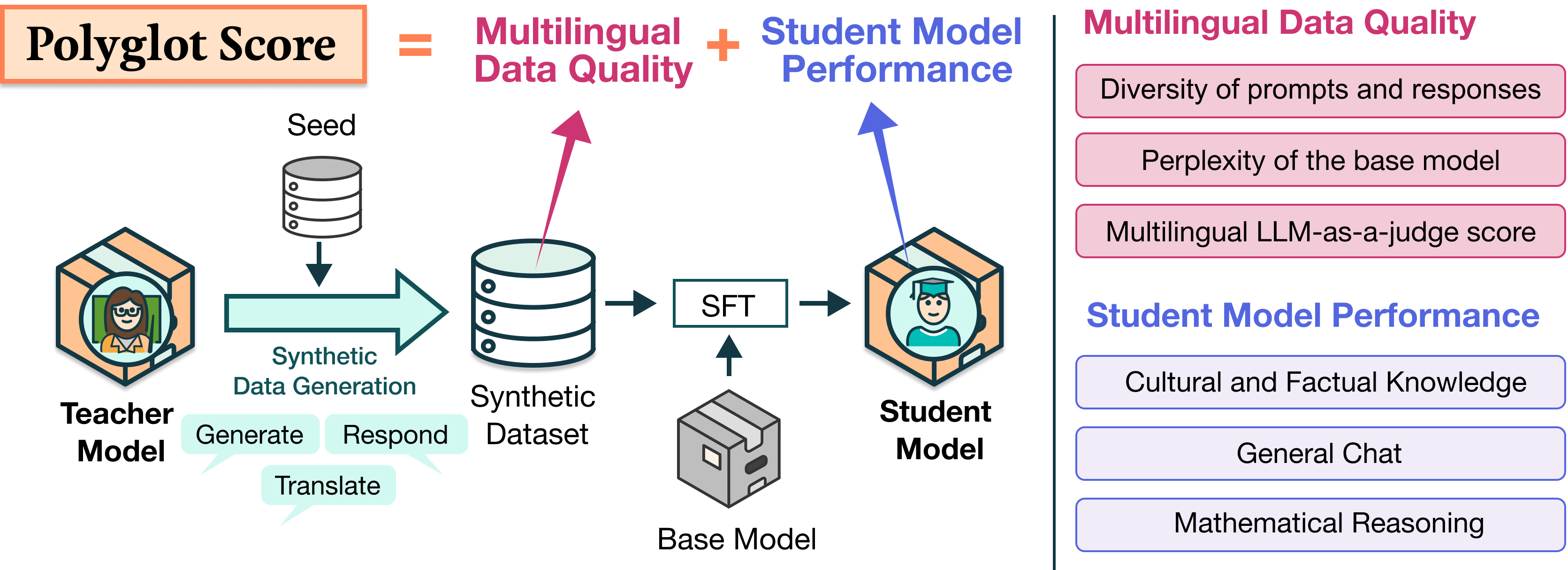
Polyglot Teachers: Evaluating Models for Multilingual Synthetic Data Generation
Preprint ‘26
Lester James V. Miranda, Ivan Vulić, and Anna Korhonen
Code / Dataset / Models / Website
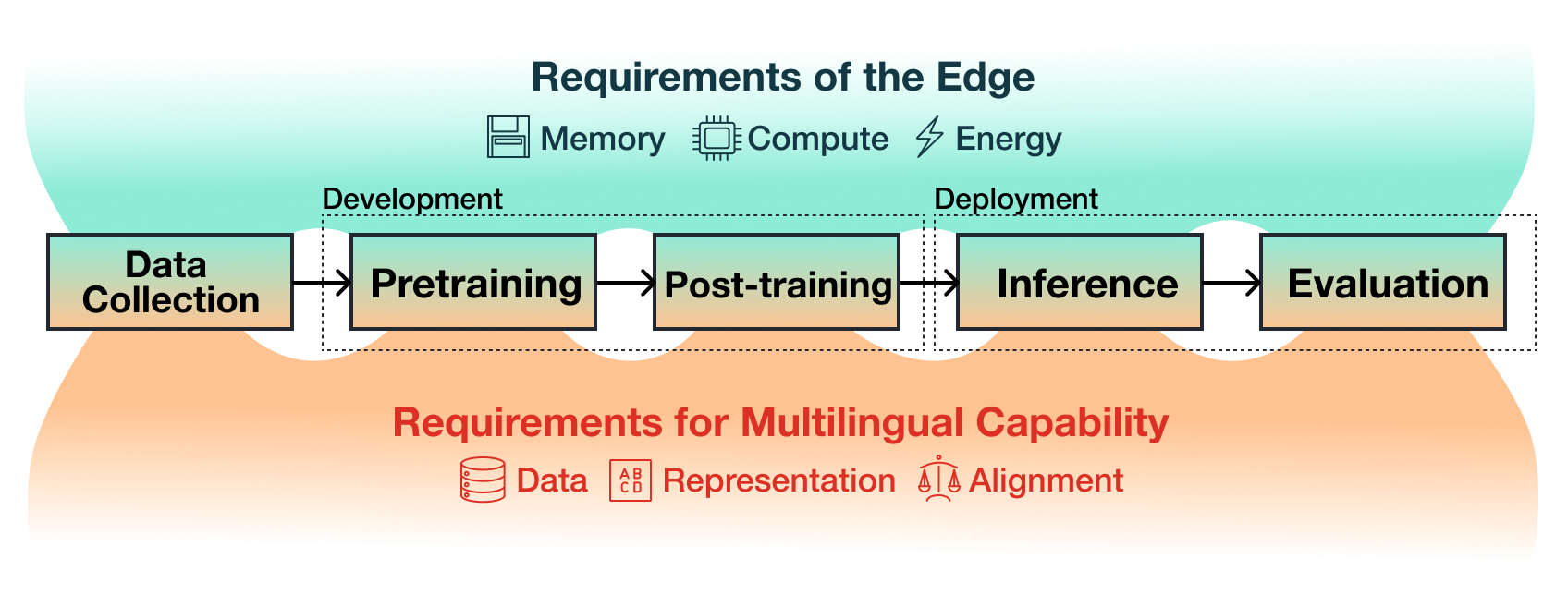
Multilinguality at the Edge: Developing Language Models for the Global South
Preprint ‘26
Lester James V. Miranda, Songbo Hu, Roi Reichart, and Anna Korhonen
Code / Website
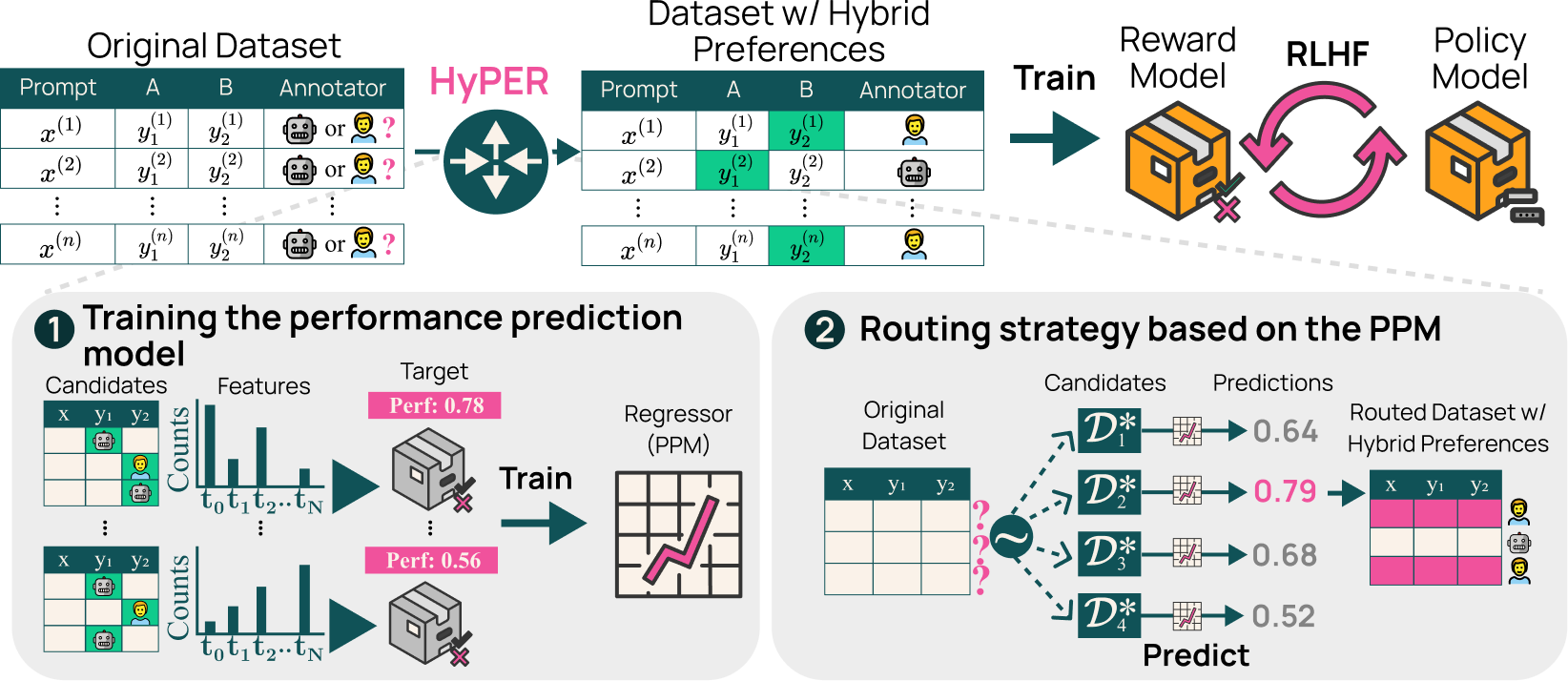
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
ACL ‘25 (work done as pre-doc at Ai2)
Lester James V. Miranda★, Yizhong Wang★, Yanai Elazar, Sachin Kumar, Valentina Pyatkin, Faeze Brahman, Noah A. Smith, Hannaneh Hajishirzi, and Pradeep Dasigi
Code / Dataset / Slides / Poster / Video
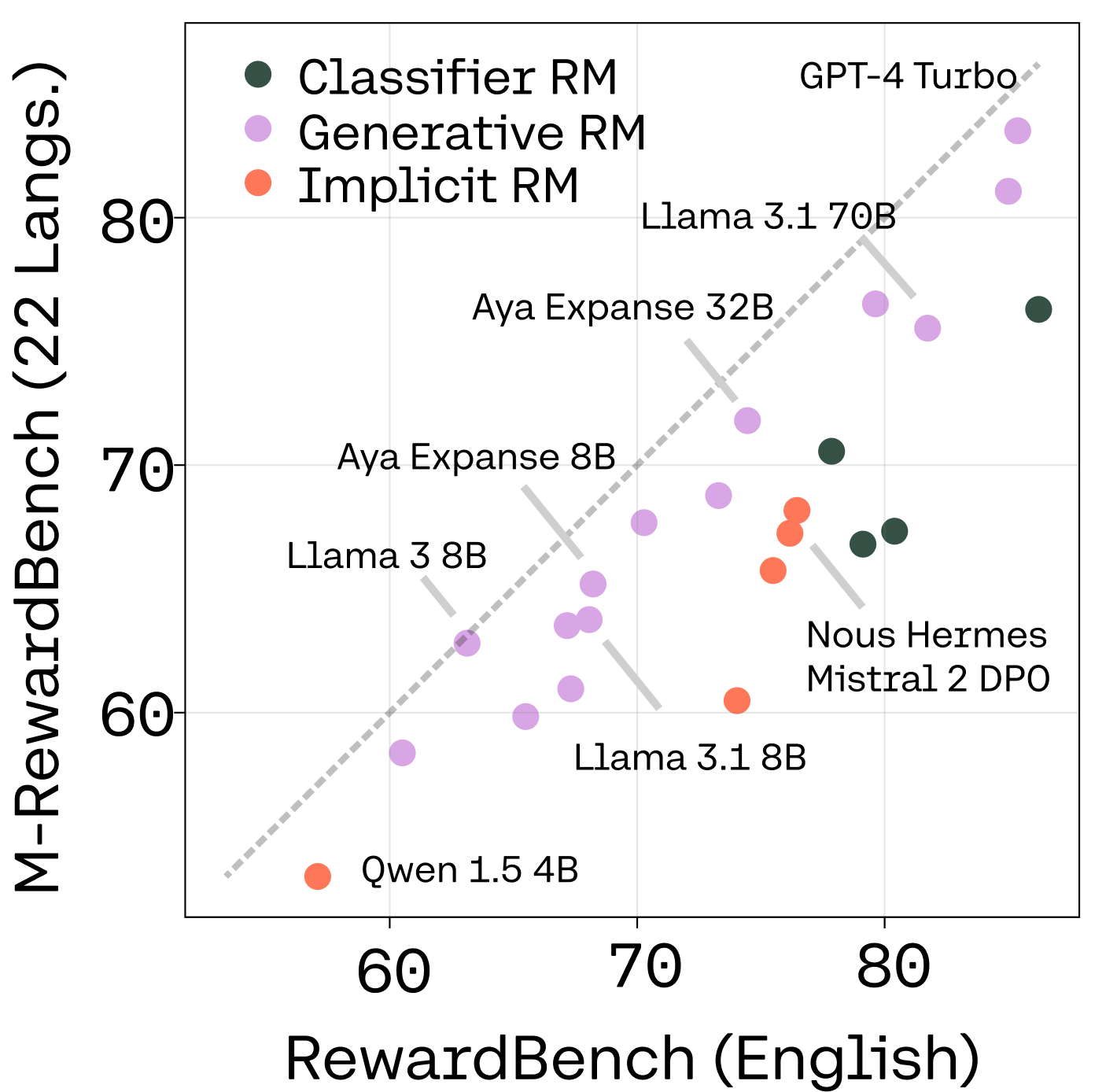
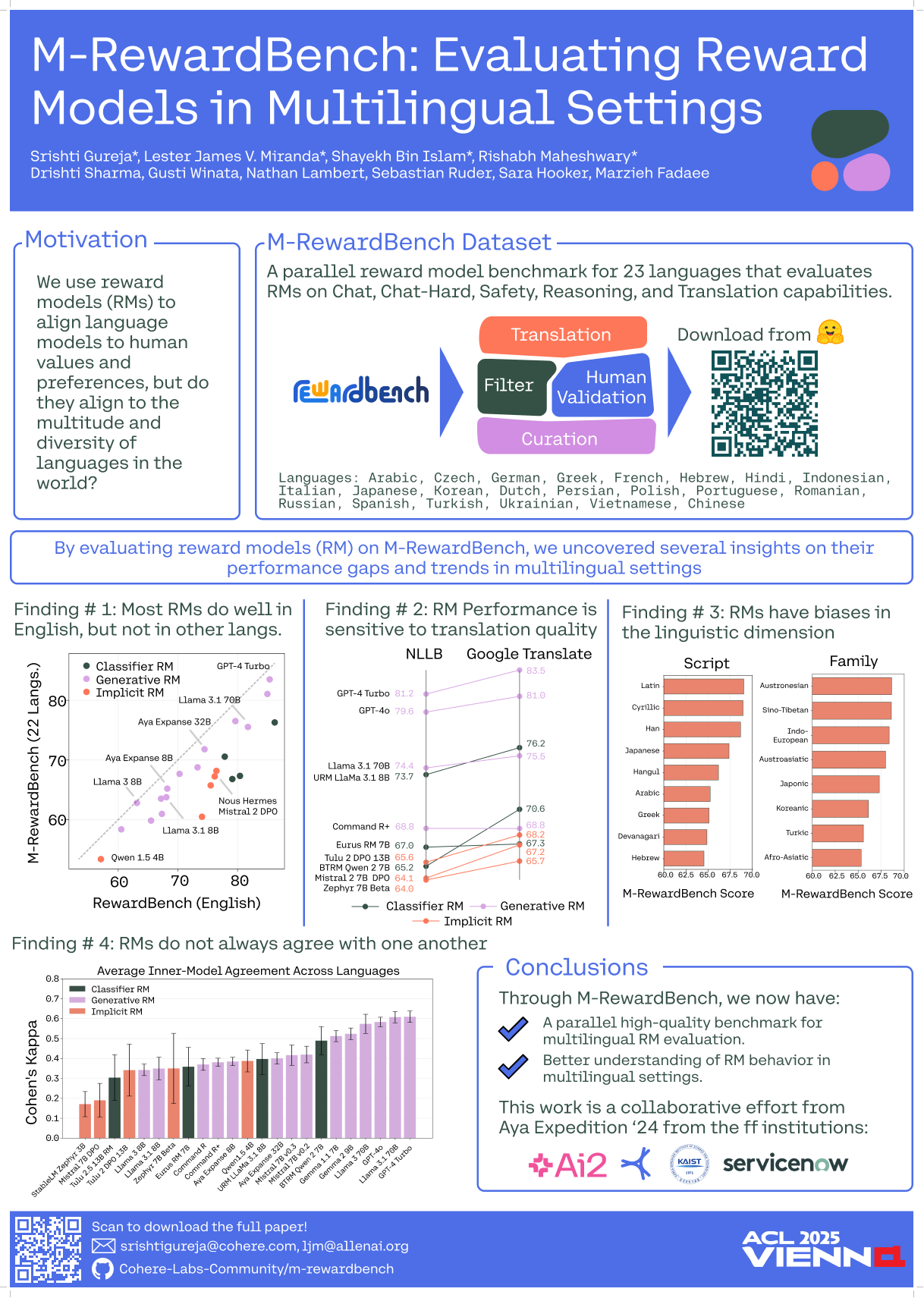
M-RewardBench: Evaluating Reward Models in Multilingual Settings
ACL ‘25 (work done as part of Expedition Aya w/ Cohere Labs)
Srishti Gureja★, Lester James V. Miranda★, Shayekh bin Islam★, Rishabh Maheshwary★, Drishti Sharma, Gusti Winata, Nathan Lambert, Sebastian Ruder, Sara Hooker, and Marzieh Fadaee
Code / Dataset / Slides / Poster / Video
I have been involved in several open-model efforts such as Tülu 3, OLMo 2 (synthetic preferences for RLHF) and OLMo 3 (synthetic tool-use trajectories for SFT) during my days as a pre-doc in Ai2. I also contributed datasets in the SEACrowd project for Southeast Asian languages.
Finally, I care a lot about advancing Filipino NLP and representing my native language. This involves:
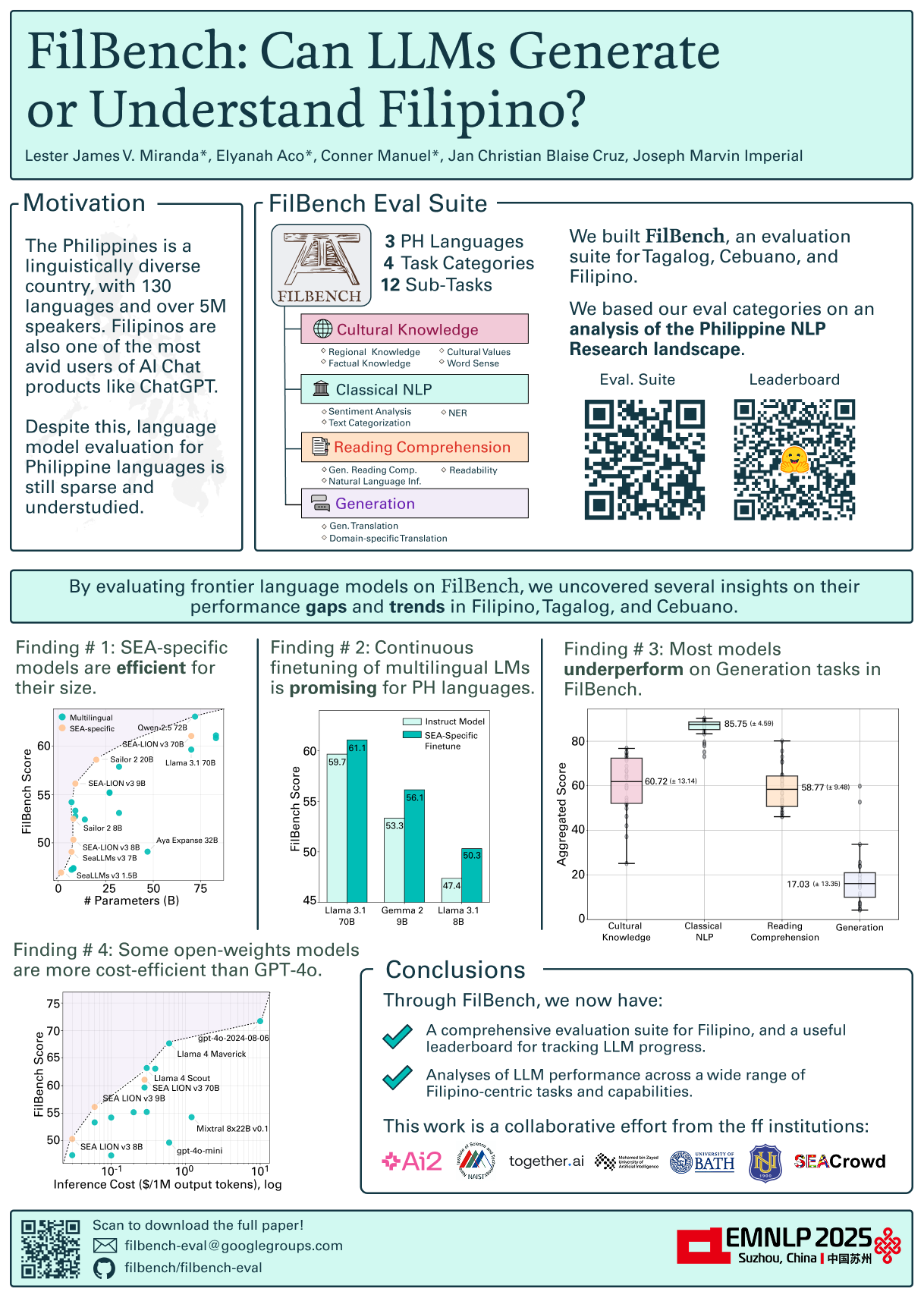
- developing benchmarks such as FilBench-Eval (EMNLP ‘25),
- building resources such as UD-NewsCrawl (ACL ‘25) and TLUnified-NER (SEALP ‘23), and
- creating open-source tools like calamanCy (NLP-OSS ‘23).
I write a lot about Filipino NLP in this blog and organize researchers on collaborative projects through the FilBench collective.
Research Posters
I enjoy making posters for my research projects, and still strive to improve this craft. Here are some that I presented in various conferences and workshops!