Geomancer: automate extraction of geospatial features
November 2022: We’ve stopped development of Geomancer and archived the repository. I’ve recently changed jobs, too, as I am working in open source full-time with Explosion and spaCy! You can check out my retrospective at the end.
Last Tuesday, I gave a talk at Databeers Manila at the Asian Institute of Management about Geomancer, an open-source library that I helped build. So I figured it best to talk about the project through my slides and give a deeper context to some of the library’s design.

Why build Geomancer?
Through some of our geospatial client work, we saw how informative a single coordinate could be. When taken together, we can extract patterns that can help us with tasks like wealth estimation, building detection, and hub estimation. However, a significant prerequisite involves getting useful machine learning features to train statistical models.1

Feature engineering is a common task in machine learning. It involves transforming raw data into features that data scientists can use for statistical learning techniques. Unfortunately, there is no easy way to do these as of late. Most require extensive knowledge of geospatial tools like QGIS or ArcGIS. These techniques also don’t work well at scale: workflows can be complicated and costly in compute and storage.

Geomancer aims to bridge that gap by providing a Python library and a framework to set up a geospatial feature engineering system.

What can Geomancer do?
Geomancer allows users to quickly define features, connect to multiple data
warehouses, and share or reproduce features. For example, data scientists need only to
interact with the geomancer Python library, while data engineers set up the
backend connection to the data warehouse.
Given a set of lat-long coordinates, users define a
Spell
to create features declaratively. These are the building blocks of the
library. For example, a spell can be a distance to the nearest point of interest (POI), the number of
POIs within a set length, and more!
For example, we want to get the distance to the nearest embassy for several points. We first transform our list of coordinates into a Pandas DataFrame, then define a spell from the DistanceToNearest primitive. Finally, we pass the name of the POI, the data warehouse source (more on that later), and the name of the resulting feature:
from geomancer.spells import DistanceToNearest
import pandas as pd
# Dataframe of coordinates with columns 'latitude' and `longitude'
my_coords = pd.read_csv("coordinates.csv")
spell = DistanceToNearest("embassy",
source_table="bigquery_osm_table",
feature_name="dist_embassy",
)
We can then
cast
this
Spell
on the DataFrame to obtain a new one with the feature, dist_embassy, in another column.
output_df = spell.cast(my_coords)
Getting single features might be a hassle, so the library also has a way to
group features (Spells) into a collection via a
SpellBook.
You can also serialize features into a JSON file for sharing and
reproducibility.
Suppose after our analysis, we realized that the distance to primary
roads and the number of nearby supermarkets are good indicators for estimating
wealth. We can collect these features into a SpellBook, and then
export it as a JSON file:
from geomancer.spells import DistanceToNearest, NumberOf
from geomancer.spellbook import SpellBook
spellbook = SpellBook(
spells=[
DistanceToNearest(
"primary",
source_table="bigquery_osm_table",
feature_name="dist_primary"
),
NumberOf(
"supermarket"
source_table="bigquery_osm_table",
feature_name="num_supermarkets"
),
])
spellbook.author = "Juan dela Cruz"
spellbook.description = "Good features for economic indicators"
spellbook.to_json("features.json")
We can then send these features to another data scientist so that they can try it out in their own set of coordinates (maybe to verify it in another location or country):
from geomancer.spellbook import SpellBook
import pandas as pd
coords = pd.read_csv("country_coords.csv")
spellbook = SpellBook.read_json("features.json")
df_with_features = spellbook.cast(coords)
Geomancer obtains these features because it’s connected to a data warehouse (in the above case, it’s BigQuery). Most geospatial datasets are stored in these large OLAP databases, and Geomancer takes advantage of their storage and compute capabilities. Currently, the library has drivers for BigQuery, PostGIS, and SpatiaLite.
And that’s it for the library portion of Geomancer! You can install geomancer via pip, and start casting spells your way! In the next section, I’ll discuss the framework’s architecture and layout.
It’s an interesting read if you want to know more how we set up Geomancer in Thinking Machines.
Architecture
There are two main components for Geomancer: the Python library and the geospatial data warehouse. You can think of Geomancer as a glorified database query writer. The Python library allows us to abstract away the need to write complicated SQL queries and spend time setting up and configuring databases.
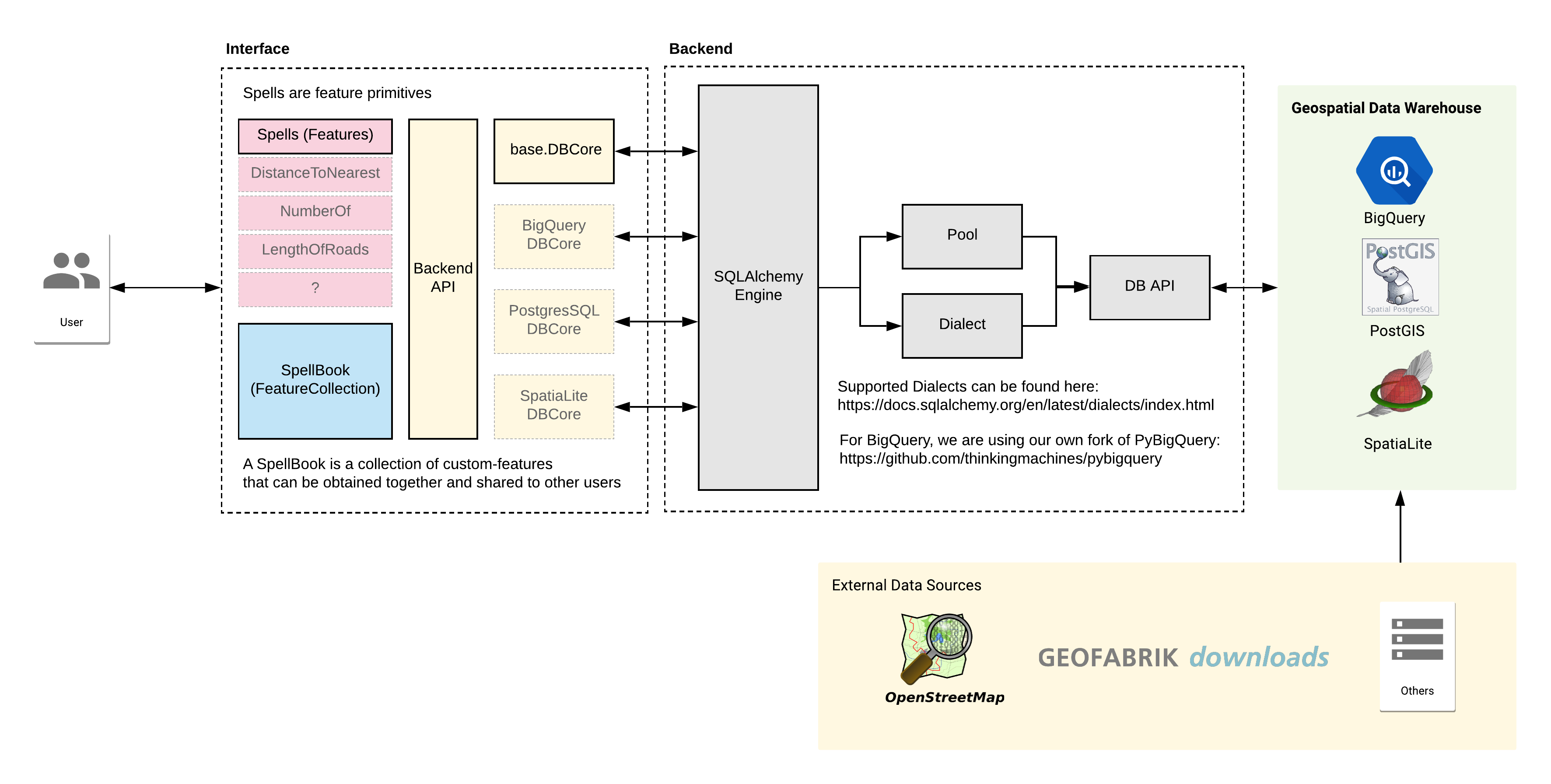
Starting from left to right:
- The interface is a standard Python library. Its backend is run via the SQLAlchemy engine, which allows us to combine and group queries without the hassle of a templating engine. We extended the SQLAlchemy Core with the databases we support. This process will enable us to write dialects (i.e., different variations of the SQL language) to our liking.
- The geospatial data warehouse stores the datasets we have. In the example above, you can see this referenced as
bigquery_osm_table. We set up pipelines to obtain data from external sources such as Geofabrik and OpenStreetMap, plus some of our proprietary data sources.
I like this setup because there’s a clear delineation between a data scientist’s and a data engineer’s roles. As a result, they both do what they do best: the former on engineering features and the latter on setting up pipelines.
Conclusion (Postscript)
Updated November 2022: I rewrote the conclusion to fit my current thoughts on the project.
Unfortunately, we discontinued development on Geomancer because of several factors: I got busy with client work, I managed a team, and the use cases might be smaller than I imagined. Development stalled and went to a halt. I also handled more prominent consulting clients back then, so I could only focus a little on internal open-source work.
Nevertheless, two years after Geomancer, I learned a lot about the non-engineering side of software engineering. Sure, I think my technical knowledge has grown, but the invisible parts of developing software revealed themselves to me:
- Time is money. We spent a lot of time developing it that there should always be a relevant business case to “break even.” This can be in the form of a client project that demonstrates the tool or a SaaS. We don’t practice the latter, and we can’t find the former, so it was a cost deficit in the end.
- Don’t be attached to your code. The younger version of me still has an unhealthy relationship with my passion; seeing things not work out bums me out. I have reflected on this recently, see “my personal framework for flourishing.” Sometimes, the business strategy changes, and your work may not be part of it.
- Learn to market. Before, the development of Geomancer was done by a small group of volunteers. As we all got busy, we deprioritized open-source work for more money-generating activities (business development, client work, etc.). I still believe in the importance of this tool, but I think I failed to market it properly.
Lastly, I learned that I love working in open-source! Open-source software was my gateway to programming back in 2017, and five years down the line, it’s still something I enjoy. I decided to devote myself to open-source when the opportunity presented itself, so I accepted an offer to work at spaCy. Initially, I was planning to go back to Ateneo to prep for my Ph.D., but the winds of change!2
I’m also grateful to Thinking Machines for giving me the space to develop this library and to various volunteers who helped me build it. Thank you! I wrote this postscript because I want to bookend this experience on a good note.3 I don’t think Geomancer was successful. But at least I can close that chapter with finality. It sucks, but such is life. The Github repository for Geomancer is now archived. Thinking Machines is currently working on another geospatial tool, Geowrangler. I wish this new project success!
-
We want to differentiate between geospatial and machine learning features. They’re the same term but refer to different things. Geospatial features include coordinates, attributes, and temporal information. We can consider the features extracted by Geomancer as a derivation of geospatial features. ↩
-
My favorite poem on change and fate is from Ella Wheeler Wilcox’s The Winds of Fate. Curiously, I discovered it from a Magic: The Gathering card, Winds of Change! ↩
-
I was also inspired by Seiya Tokui’s reflections on Chainer. A few years ago, Preferred Networks shifted from using Chainer (their in-house neural net framework) to Pytorch. I know Geomancer is not as big as Chainer, but I definitely feel for Tokui-san’s post. ↩