How can language models augment the annotation process?
Recently, I’ve been working on a project that involves prompting large language models (LLM) like GPT-3 to obtain zero- and few-shot annotations for named entity recognition and text categorization. We demonstrated how prompt-based interfaces found in the likes of ChatGPT can still be helpful even for structured prediction tasks.
In this blog post, I want to explore how this approach translates to more intricate and challenging annotation tasks, such as argument mining where one has to trace chains of reasoning. I’ll be working on a portion of the UKP Sentential Argument Mining Corpus (Stab, et al., 2018), where sentences are categorized either as a supporting argument, an attacking argument, or a non-argument for a given topic. I want to investigate two major questions:
-
Can zero-shot annotations be reliable? Here, I’d like to benchmark zero-shot annotations from GPT-3 and compare them with a baseline approach. I don’t think we should rely on GPT-3 alone to annotate our data, but it doesn’t hurt to see if they work.
-
Can LLMs provide extra affordance? I’d like to explore UI elements in which LLMs can help human annotators reduce their cognitive load when labeling. I want to explore an LLM’s ability to highlight spans or provide reason for their labels. Each of these affordances represent a different level of “reliance” on an LLM’s capabilities.
I will focus on the topic of minimum wage in the UKP corpus. I find it interesting, and the number of samples is small enough that I don’t have to worry about OpenAI API costs.
| Tokens | No argument | Supporting | Opposing | |
|---|---|---|---|---|
| Training set | \(42589\) | \(968\) | \(414\) | \(396\) |
| Development set | \(4899\) | \(108\) | \(46\) | \(44\) |
| Test set | \(13257\) | \(270\) | \(116\) | \(111\) |
| Total | \(60745\) | \(1346\) | \(576\) | \(551\) |
Table: Dataset statistics for the minimum wage subset of the UKP Sentential Argument Mining corpus (Stab, et al., 2018).
You can find the full project in this Github repository. It is an instance of a spaCy project that you can run to reproduce my results.
Can zero-shot annotations be reliable?
First, I want to check how accurate GPT-3’s zero-shot annotations are. Then, I will compare it against a standard approach of training a supervised model from the corpus. To qualify, the word “reliability” here is shallow. I’m not making claims on a language model’s trustworthiness, only its test set accuracy.
I will compare GPT-3’s zero-shot annotations against a standard approach of training a supervised model from the corpus.
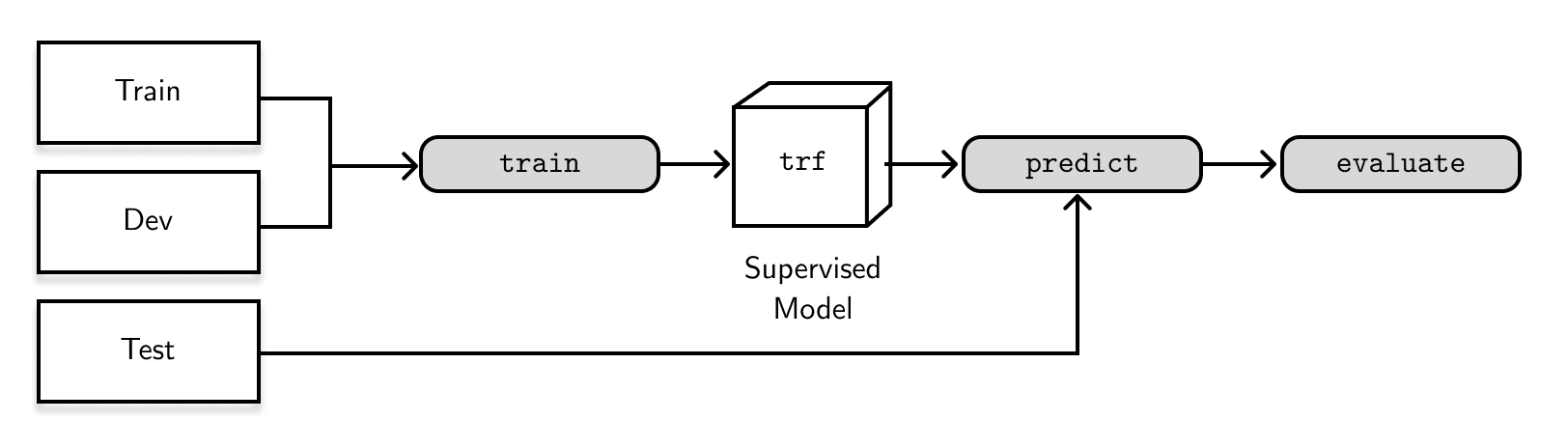
In the supervised set-up, I’m using spaCy’s TextCategorizer to perform an exclusive text classification task. It uses a stacked ensemble of a linear bag-of-words model, and a neural network model initialized with the weights of a large RoBERTa transformer (Liu, et al., 2019).1 To recap how supervised learning works, we train a model from the training and development sets, then evaluate the predictions on a held-out test set as shown in the figure below:
In the zero-shot set-up, I completely ignore the training and development sets and include test set examples into the prompt. Then, I send this prompt to GPT-3 and parse the results. Finally, I treat whatever it returns as its predictions and compare them with the gold-standard test data.
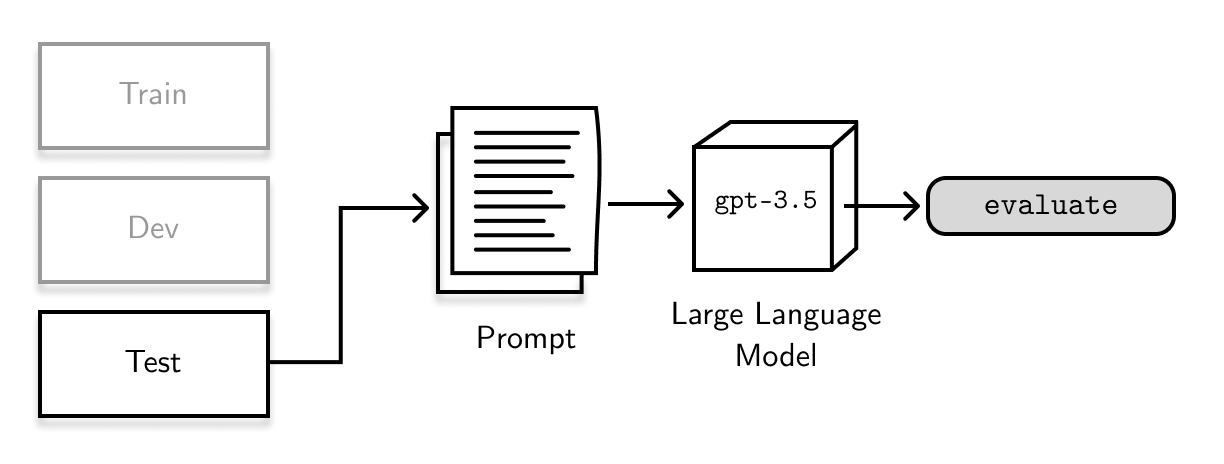
I formatted the prompt like this:
Determine whether the text is a supporting argument (Argument_for),
opposing argument (Argument_against), or none (NoArgument) regarding
the topic of "minimum_wage." Answer in the following format:
answer: <Argument_for,Argument_against, or NoArgument>
Text:
"""
Increasing minimum wage will increase our standard of living.
"""
And GPT-3 answers in the form of:2
answer: Argument_for
For comparison, I evaluated the predictions of the supervised and zero-shot setup using the gold-standard test data. The results are shown in the table below:
| Scores | Zero-shot | Supervised |
|---|---|---|
| Micro F1-score | \(\mathbf{81.45}\) | \(79.88\) |
| Macro F1-score | \(\mathbf{78.74}\) | \(77.52\) |
| F1-score (per type) | Zero-shot | Supervised |
|---|---|---|
Supporting argument (Argument_for) |
\(\mathbf{75.21}\) | \(73.60\) |
No argument (NoArgument) |
\(\mathbf{86.74}\) | \(85.66\) |
Opposing argument (Argument_against) |
\(\mathbf{74.26}\) | \(73.30\) |
Interestingly, the zero-shot pipeline performs better than the supervised pipeline. For example, the Macro F1-score, which reports how well the two classifiers fare in light of an imbalanced dataset, shows the zero-shot classifier leading by a hair against the supervised model. These results answer the question we posed in this section— we can rely on GPT-3’s zero-shot annotations when labeling an argument mining dataset.
Perhaps the wrong conclusion to make here is that we can just replace our supervised model with a zero-shot classifier in production. It’s an appealing thought because we see higher scores from our LLM predictions. However, that’s a trap because we already know the test set. In production, we either don’t have access to gold-standard annotations, or we’re still making it ourselves. So instead, think of our zero-shot predictions as silver-standard annotations that we can refine further to produce trustworthy, gold-standard labels.
Think of our zero-shot predictions as silver-standard annotations that we can refine further to produce trustworthy, gold-standard labels.
Can LLMs provide extra affordance?
In this section, I want to explore what other capabilities a large language model can offer as we annotate our dataset. I want to think of these as affordances, something that an annotator can use as they produce gold-standard data.
In the context of argument mining, we can use LLMs to (1) highlight an argument’s claim and premise and (2) provide a reason as to why it labeled a particular text as such. I’d like to think of these affordances as different levels of reliance over GPT-3’s capabilities:

I noticed that I become more inattentive as I use affordances that rely heavily on LLMs.
From my annotation experience, I noticed that I become more inattentive as I use affordances that rely heavily on LLMs. It’s easier for me to just accept whatever the language model suggests. This can be dangerous because an LLM can, in all its biases, influence my annotations. More so if it demonstrates some level of intelligible text to defend its decision. Perhaps it’s just my personal negligence and laziness, but I’d like to highlight this experience to provide some context to the next sections.
Directed: highlight an argument’s claim and premise
Palau and Moens (2009) define an argument as a set of premises that support a claim.3 For our dataset, I would like to introduce an annotation set-up where the premise and the claim, if present, are highlighted to guide annotation.
Annotation set-up where the premise and claim, if present, are highlighted to guide annotation.
This set-up aims to give the annotator extra information to label a particular text. For example, they can use the highlighted spans to easily check the premise of an argument with respect to its claim. The hope is that through this, we can reduce the cognitive load of annotation as the relevant parts of the document are already emphasized.
For this to work, we need to (1) treat the premise and the claim as spans and prompt GPT-3 to identify them for each text as a span labeling task. Then, we (2) pass this information into our annotation tool and label as usual, except that the relevant spans are now highlighted:
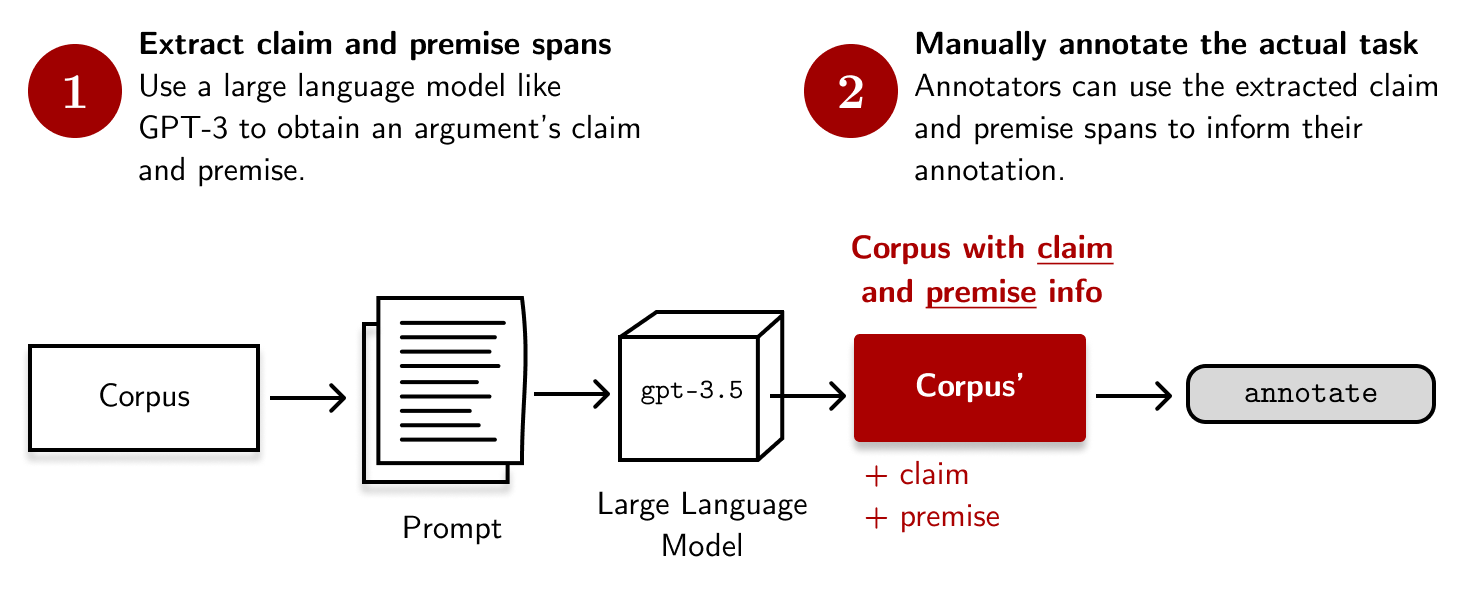
For GPT-3, the prompt goes like this:
From the text below, identify the exact span of text that represents
the premise, and the claim regarding the topic of minimum wage.
Answer in the following format:
Premise: <comma delimited list of string or N/A>
Claim: <string or N/A>
Here's the text
Text:
"""
In 2009, an increase in minimum wage resulted to a
higher standard of living .
"""
And we expect the answer in the form of:
Premise: "In 2009", "higher standard of living"
Claim: "increase in minimum wage"
I implemented this process using the OpenAI
recipes from
Prodigy. In particular, I used the ner.openai.fetch recipe
to prompt GPT-3 to extract spans based on the labels I provided—i.e.,
Premise and Claim. This recipe attaches the premise and claim as spans into
a new corpus that I can load using Prodigy’s built-in
textcat.manual recipe. Because
of this set-up, the spans are highlighted in the UI as shown below:
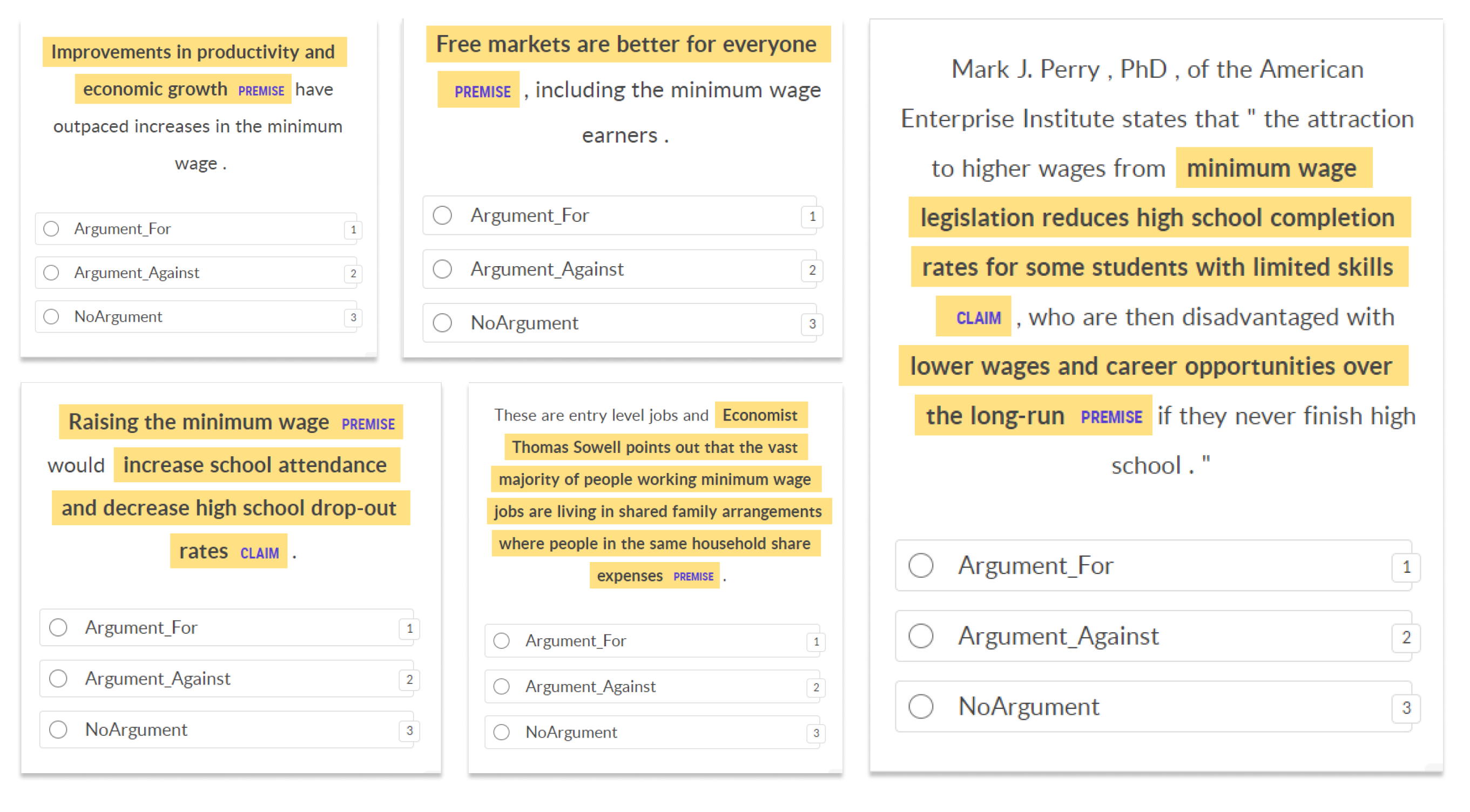
This set-up allows annotators to take advantage of relevant spans as they decide
the label for a particular example. We can also combine our textcat
annotations earlier to pre-select the category choice so that annotators can
confirm an LLM’s prediction. For example, they can compare the highlighted
premise to the predicted category and decide whether to correct or accept the
suggested annotation.
Finally, I want to mention that this set-up still relies on a human annotator’s reasoning in order to label the text. The UI presents the relevant components, i.e. an argument’s premise and claim, but it’s still up to the annotator whether to use or ignore these affordances. In the next section, we will double-down on GPT-3’s capabilities and ask it to “reason” why it labeled a particular text as such.
Dependent: provide reason on a labeling decision
This time, we increase our dependence on an LLM’s output by asking it to explain why it labeled a particular text as such. Wei, et al. (2022) proposes a prompting method called chain-of-thought to elicit complex reasoning from large language models. We will be using this technique in our argument mining dataset.
Chain-of-thought prompting is often applied to arithmetic, commonsense, and symbolic reasoning tasks. The trick is to decompose a problem into intermediate steps and solve each before giving the final answer. Researchers have found empirical gains when using chain-of-thought prompting, but it’s still a hotly debated topic whether large language models can reason like humans do (Bender et al., 2021 and Bender and Koller, 2020).
One way we can apply chain-of-thought prompting to our dataset is by decomposing an argument into its premise and claim. Then, we can examine each premise and determine if they are in favor, against, or irrelevant to the claim.4 From there, we can start classifying the text amongst our three labels. This “reasoning pipeline” is shown in the figure below:
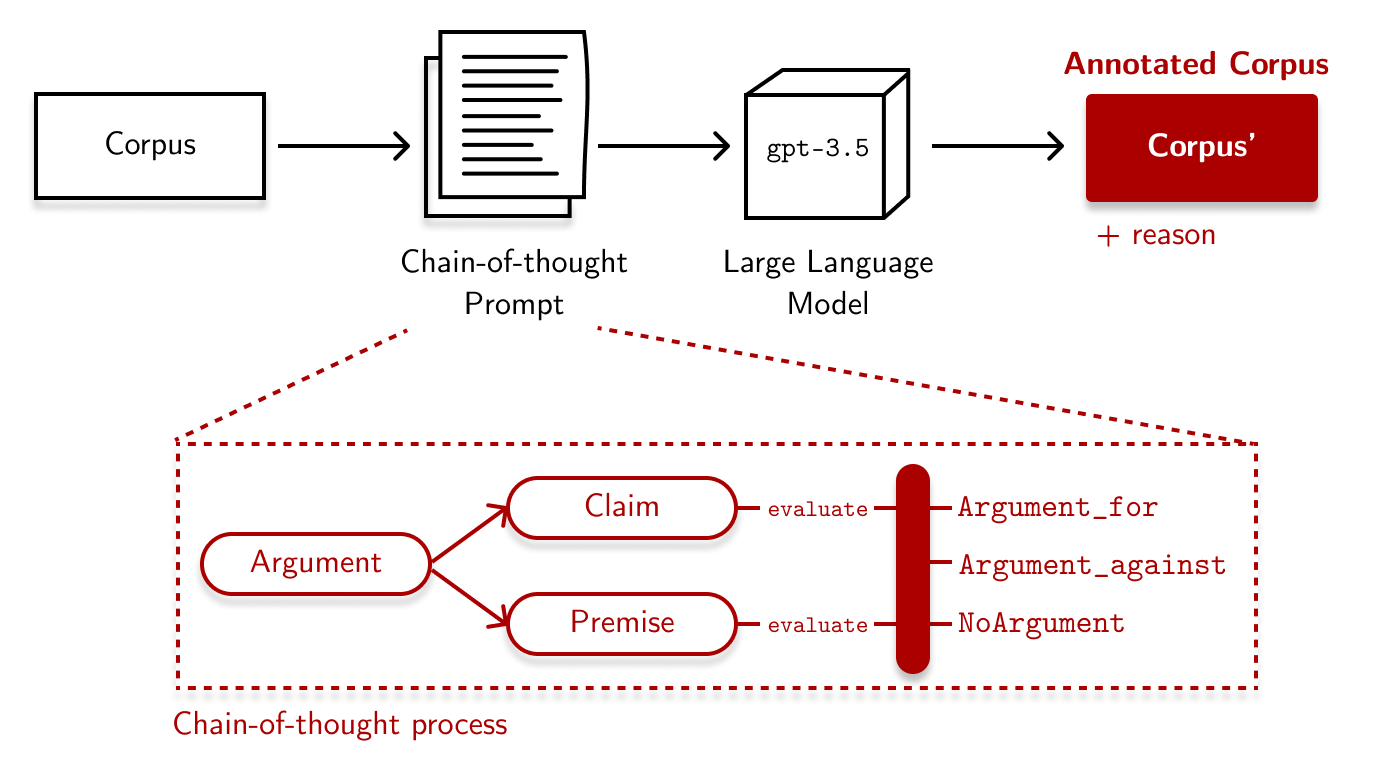
The prompt is a bit long, but it goes like this: I first provided the
instructions for the task (i.e., the labels to classify with, the format for
parsing, etc.), then I included exemplars via chain-of-thought. You can find the
complete prompt by clicking the details tab below:
Chain of thought prompt for argument mining annotation</summary>
Determine whether the text below is a supporting argument (Argument_for),
opposing argument (Argument_against), or none (NoArgument) regarding
the topic of "minimum wage." First, identify the premise and the
claim, then determine if the reasons or evidence presented in the
argument are in favor of the claim, against the claim, or irrelevant
to the claim. Answer in the following format:
answer: <Argument_for, Argument_against, or NoArgument>
reason: <reasoning process>
Below are some examples
Text:
"""
Or instead of hiring fewer employees , the company may start
outsourcing jobs to employees in countries that are willing to
work for much less than $ 10.10 per hour , resulting in fewer
jobs for Americans ."
"""
answer: Argument_against
reason: The premise of the text is that if the minimum
wage is increased to $10.10 per hour, then companies may
start outsourcing jobs to countries where employees are
willing to work for much less, leading to fewer jobs for
Americans. This is an argument against increasing the
minimum wage. Therefore the answer is Argument_against.
Text:
"""
{{text}}
"""
</details>
I used the same recipe as the zero-shot experiment earlier, but changed the
prompt to use chain-of-thought. I then loaded OpenAI’s output back to a custom
Prodigy recipe so that I can view the results in a UI. Below, you’ll find some
screenshots of this updated UI (they might be too small in your screen so feel
free to open the images in another tab). Here, we see GPT-3’s explanation
alongside its suggestion:
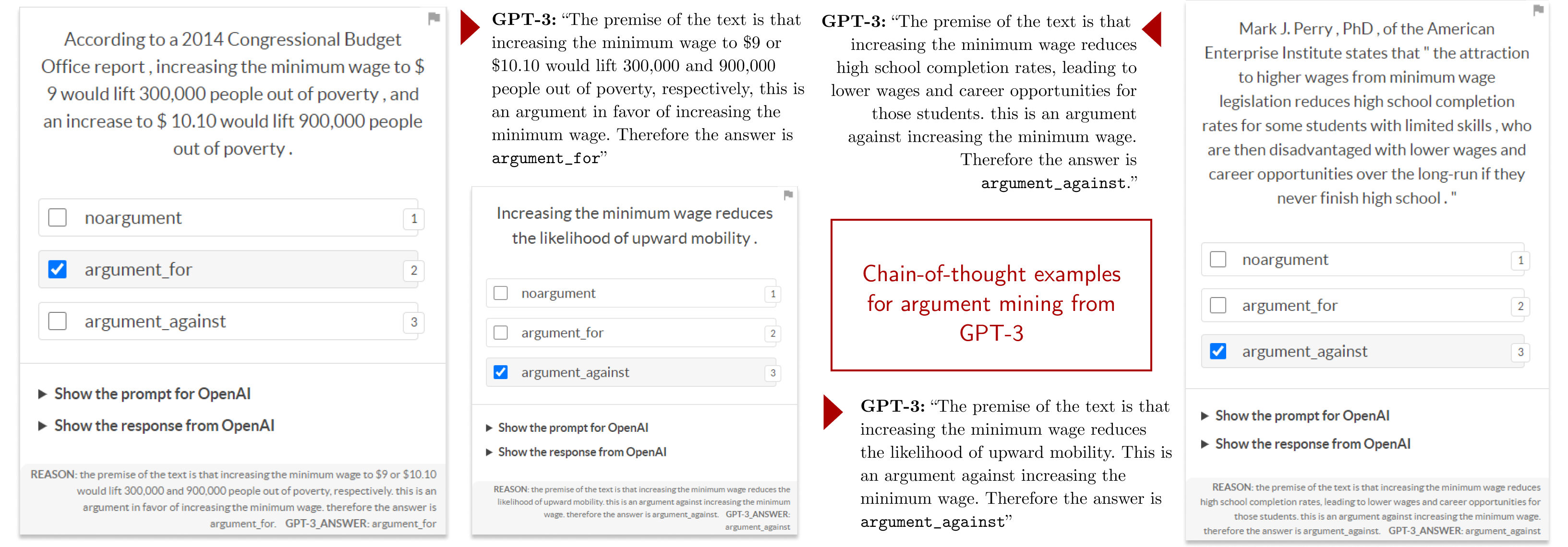
Ideally, annotators can refer to GPT-3’s explanation to confirm or correct a
suggestion. Personally, I find this workflow helpful on texts that are either
confusing or hard to parse. Having the premise and claim deconstructed in an
explicit way can help improve annotation efficiency and hopefully reduce
annotator fatigue.
Final thoughts
In this blog post, we looked into different ways on how large language models
like GPT-3 augment the annotation process. We did this in the context of
argument mining, a complex annotation task that involves reasoning. First, we
examined how zero-shot predictions fare in the corpus, and then explored
potential affordances to improve the annotation process. We categorized these
affordances based from their reliance on LLMs— manual, directed, and
dependent.
A directed approach uses an LLM to provide supplementary information that a
human annotator can use to inform their labeling decision. On the other hand, a
dependent approach asks an LLM to not only suggest labels, but also explain
why a text was labeled as such. Personally, I find myself being more inattentive
as I go from a more dependent approach to an LLM-guided annotation.
The final annotation still rests on a human annotator’s decision, not the LLM’s.
These affordances are mere guides that provide convenience through suggestions.
The final annotation still rests on a human annotator’s decision, not the LLM’s.
These affordances are mere guides that provide convenience through suggestions.
I find it comforting, because I believe there’s still some nuance in most
annotation tasks that only we can capture.
Finally, I think I made some claims here about improving efficiency because of
these UI affordances (e.g., inattentiveness, parsing chain-of-thought). I admit
that these were all from my personal experiences when annotating and trying out
these recipes. I’m happy to hear suggestions on how I can verify or test these
claims. Feel free to drop a comment below.
References
- Palau, R.M., & Moens, M. (2009). Argumentation
mining: the detection, classification and structure of arguments in text.
International Conference on Artificial Intelligence and Law.
- Thorn Jakobsen, T.S., Barrett, M., Søgaard,
A., & Lassen, D.S. (2022). The Sensitivity of Annotator Bias to Task
Definitions in Argument Mining. In Proceedings of the 16th Linguistic
Annotation Workshop (LAW-XVI) within LREC2022, pp. 44-61, Marseille, France.
European Language Resources Association.
- Lawrence, J., Reed, C.(2019) Argument Mining:
A Survey. Computational Linguistics 45 (4): 765–818. doi:
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen,
D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A
Robustly Optimized BERT Pretraining Approach. ArXiv, abs/1907.11692.
https://doi.org/10.1162/coli_a_00364.
- Stab, C., Miller, T., Schiller, B., Rai, P., and Gurevych,
I. (2018). Cross-topic argument mining from heterogeneous sources. In
Proceedings of the 2018 Conference on Empirical Methods in Natural Language
Processing, pages 3664–3674, Brussels, Belgium, October-November. Association
for Computational Linguistics.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E.H.,
Le, Q., & Zhou, D. (2022). Chain of Thought Prompting Elicits Reasoning in
Large Language Models. ArXiv, abs/2201.11903.
- Huang, F., Kwak, H., & An, J. (2022). Chain of
Explanation: New Prompting Method to Generate Higher Quality Natural Language
Explanation for Implicit Hate Speech. ArXiv, abs/2209.04889.
- Bender, E.M., Gebru, T., McMillan-Major, A., &
Shmitchell, S. (2021). On the Dangers of Stochastic Parrots: Can Language Models
Be Too Big? 🦜. Proceedings of the 2021 ACM Conference on Fairness,
Accountability, and Transparency.
- Bender, E.M., & Koller, A. (2020). Climbing
towards NLU: On Meaning, Form, and Understanding in the Age of Data. Annual
Meeting of the Association for Computational Linguistics.
Determine whether the text below is a supporting argument (Argument_for),
opposing argument (Argument_against), or none (NoArgument) regarding
the topic of "minimum wage." First, identify the premise and the
claim, then determine if the reasons or evidence presented in the
argument are in favor of the claim, against the claim, or irrelevant
to the claim. Answer in the following format:
answer: <Argument_for, Argument_against, or NoArgument>
reason: <reasoning process>
Below are some examples
Text:
"""
Or instead of hiring fewer employees , the company may start
outsourcing jobs to employees in countries that are willing to
work for much less than $ 10.10 per hour , resulting in fewer
jobs for Americans ."
"""
answer: Argument_against
reason: The premise of the text is that if the minimum
wage is increased to $10.10 per hour, then companies may
start outsourcing jobs to countries where employees are
willing to work for much less, leading to fewer jobs for
Americans. This is an argument against increasing the
minimum wage. Therefore the answer is Argument_against.
Text:
"""
{{text}}
"""
The final annotation still rests on a human annotator’s decision, not the LLM’s. These affordances are mere guides that provide convenience through suggestions.
-
You can check the configuration file I used for this project in this Github repository. ↩
-
I don’t really expect that GPT-3 will always abide with the response format I set— it’s a statistical model, after all. However, I didn’t encounter any parser errors during my experiments. ↩
-
Several NLP papers may still have varying degrees of explicitness towards this definition (Jakobsen, et al., 2022), but for the purposes of this blog post, we’ll stick with the one above. ↩
-
Personally, I think what qualifies as a chain-of-thought prompt is a bit vague. For now, I scoped it as “any prompt that contains a coherent series of intermediate reasoning steps that lead to the final answer of a problem.” Lastly, I highly recommend going through the paper’s OpenReview discussion, there are some interesting points raised by the reviewers regarding evaluation. ↩