
Towards a Tagalog NLP pipeline
Update (2023-12-06): I am happy to announce that two papers came out from this project: “Developing a Named Entity Recognition Dataset for Tagalog” and “calamanCy: A Tagalog Natural Language Processing Toolkit”.
Tagalog is my native language. It’s spoken by 76 million Filipinos and has been the country’s official language since the 30s. It’s a text-rich language, but unfortunately, a low-resource one. In the age of big data and large language models, building NLP pipelines for Tagalog is still difficult.
In this blog post, I’ll talk about how I built a named-entity recognition (NER) pipeline for Tagalog. I’ll discuss how I came up with a gold-standard dataset, my benchmarking results, and my hopes for the future of Tagalog NLP.
I don’t recommend using this pipeline for production purposes yet. See caveats.
Table of Contents (click ↵ to jump back to the TOC)
- Background: Tagalog NER data is scarce
- Methods: We still want gold-annotated data
- Experimental results
- Conclusion
Tagalog NER data is scarce ↵
Even if Tagalog is text-rich, the amount of annotated data is scarce. We usually call these types of languages as low-resource. This problem isn’t unique to Tagalog. Out of the approximately 7000 languages worldwide, only 10 have adequate NLP resources (Mortensen, 2017 and Tsvetkov, 2017). However, we can circumvent the data scarcity problem by bootstrapping the data we have.
We can circumvent the data scarcity problem… ↵
There are many clever ways to circumvent the data scarcity problem. They usually involve taking advantage of a high-resource language and transferring its capacity to a low-resource one. The table below outlines some techniques:
| Approach | Data* | Prerequisites | Description |
|---|---|---|---|
| Supervised learning | High | Large amount of labeled data. | Train a model as usual using feature-label pairs. |
| Cross-lingual transfer learning | None to a few | Understanding of the similarities between source and target languages. | Transfer resources and models from resource-rich source to resource-poor target language. |
| Zero-shot learning | None | High similarity between source and target domains. It often helps if the latter is a “subset” of the former. | Train a model in a domain and assume it generalizes out-of-the-box in another domain. |
| Few-shot learning | A few to high | Similarity between source and target domains and a task-specific finetuning dataset. | Use a pretrained model from a large corpus, and then finetune on a specific task. |
| Polyglot learning | A few to high | A mixed corpus or a dataset with languages converted to a shared representation. | Combine resource-rich and resource-poor languages and train them together. |
* Data: amount of gold-labeled annotations required.
My work focuses on supervised and few-shot learning. Because these methods require a substantial amount of data, I need to take advantage of existing corpora. One way is to use silver-standard data. Silver-standard annotations are usually generated by a statistical model trained from a similar language or a knowledge base. They may not be accurate or trustworthy, but they’re faster and cheaper to create.
…by bootstrapping the data we have ↵
The best way to work with silver-standard data is to use them for bootstrapping the annotations of a much larger and diverse dataset, producing gold-standard annotations. Through this method, we reduce the cognitive load of labeling and focus more on correcting the model’s outputs rather than doing it from scratch. The figure below illustrates the workflow I’m following:
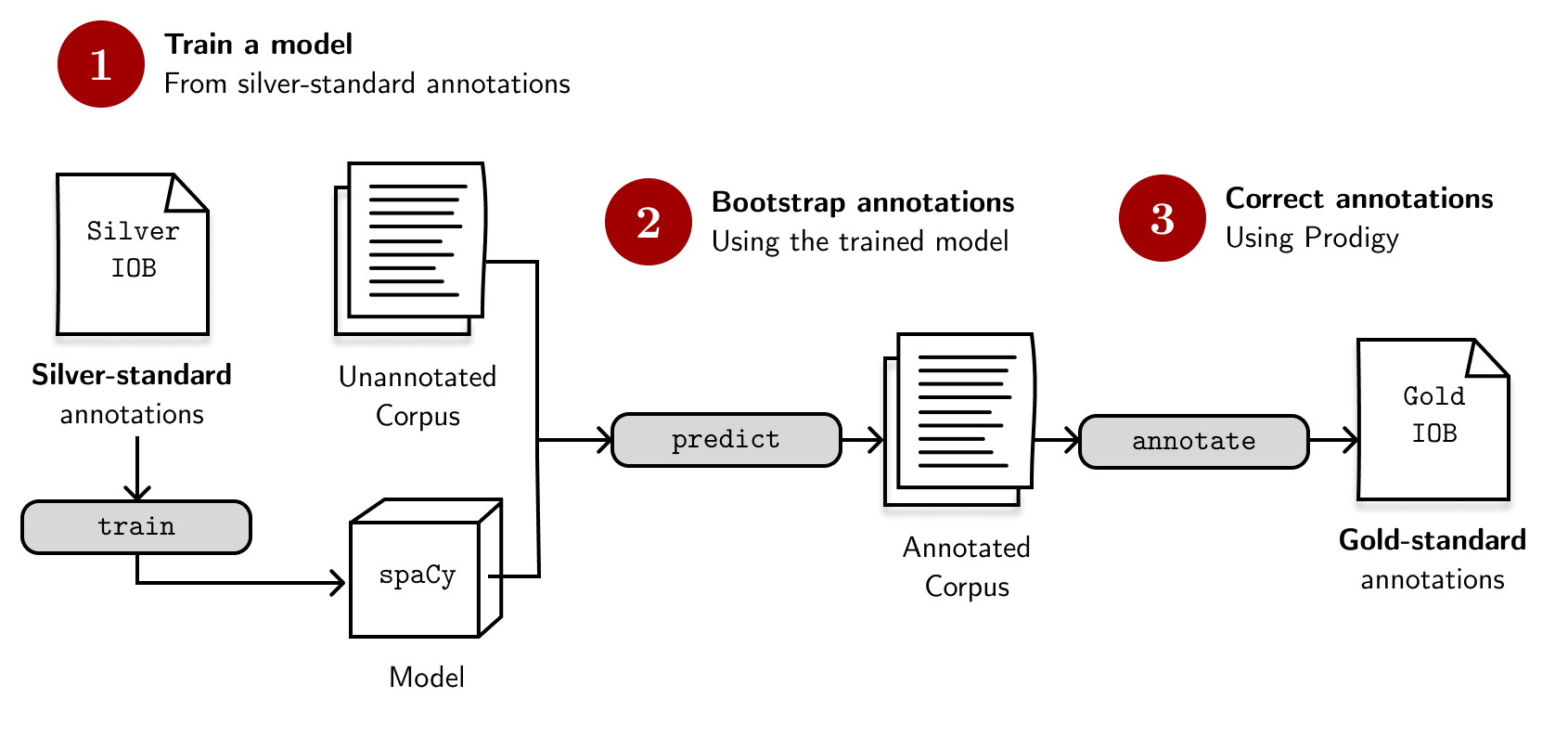
By bootstrapping the annotations, we reduce the cognitive load of labeling and focus more on correcting the model’s outputs rather than labeling from scratch.
The only major NER dataset for Tagalog is WikiANN. It is a silver-standard dataset based on an English Knowledge Base (KB). Pan, Zhang, et al., (2017) created a framework for tagging entities based on Wikipedia and extended it to 282 other languages, including Tagalog. However, it’s not perfect. For example, the first few entries of the validation set have glaring errors:
Example: Hinlalato ng paa is the middle toe finger, not an ORG.
Example: Ninoy Aquino should be tagged as PER, while Sultan Kudarat as LOC.
Also, the texts themselves aren’t complete sentences. A model trained on this data might translate poorly to longer documents as the context of an entity is lost.We can’t rely solely on a model trained from WikiANN. However, it can still be useful: we can use it to train a model that bootstraps our annotations.
…the texts [in WikiANN] aren’t complete sentences. A model trained on this data might translate poorly to longer documents…so we can’t [just] rely [on it].
Fortunately, we have a lot of unannotated datasets that represent the diversity of the Filipino language. For example, there is the CommonCrawl repository that contains web-crawled data for any language. We also have TLUnified (Cruz and Cheng, 2022) and WikiText TL-39 (Cruz and Cheng, 2019) that are much more recent. For my experiments, I will use the TLUnified dataset because one of its subdomains (news) resembles that of standard NER benchmarks like CoNLL. It contains reports from 2009 to 2020 that were scraped from major Filipino-language news sites, broadsheet and associated tabloid, in the Philippines (e.g., CNN Philippines, ABS-SCBN, Manila Times, etc.).
I will be using the TLUnified dataset as it’s more recent, and one of its subdomains resemble that of standard NER benchmarks like CoNLL.
My process goes like this: I will train a model from WikiANN and have it predict entities for TLUnified. Then, I will correct the predictions using Prodigy, an annotation software, to produce gold-standard annotations. Piece of cake, right?
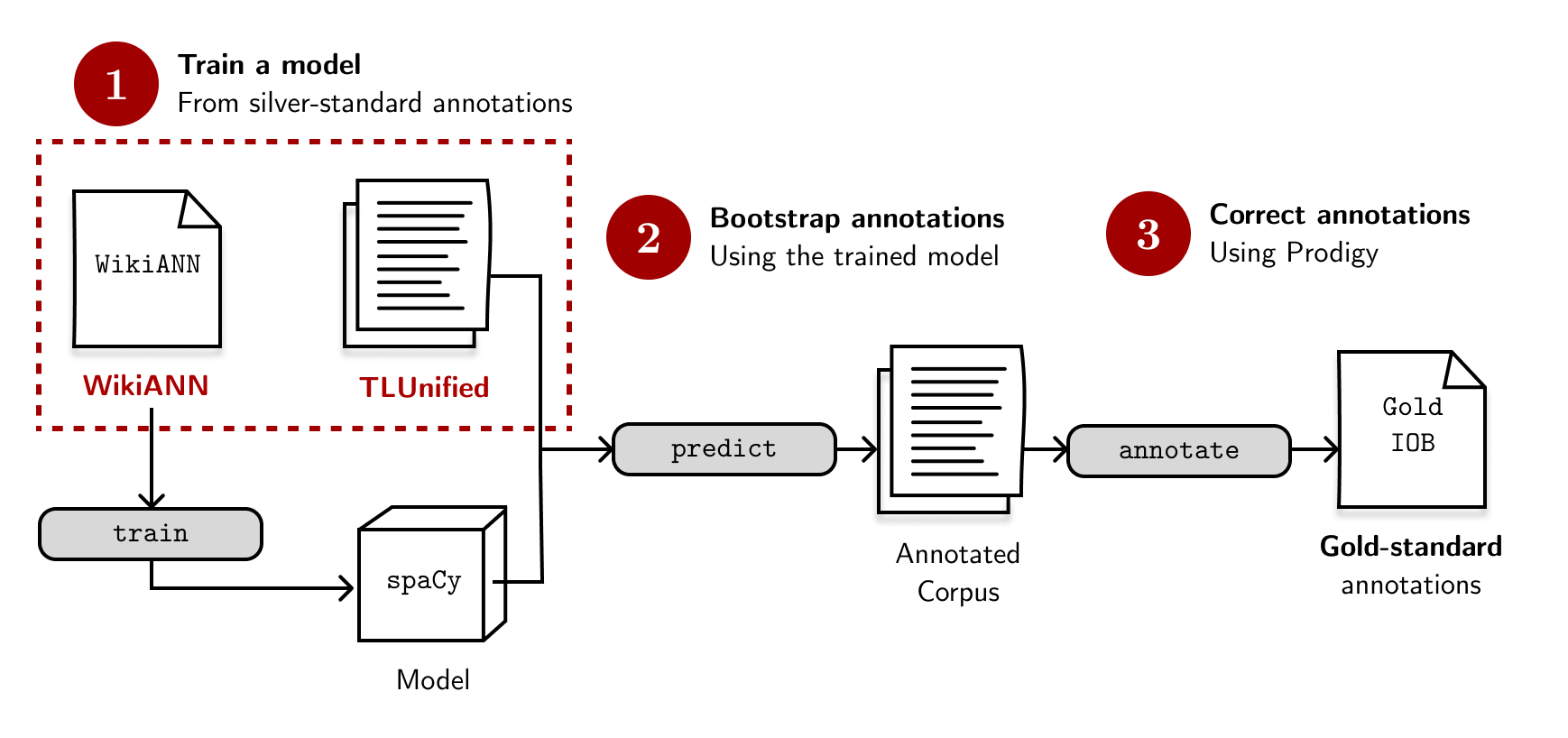
However, labeling thousands of samples is not the hardest part. As the sole annotator, I can easily influence a dataset of my biases and errors. In practice, you’d want three or more annotators and an inter-annotator agreement. Unfortunately, this is the limitation of this work. In the next section, I’ll outline some of my attempts to be more objective when annotating. Of course, the ideal case is to have multiple annotators, so let me know if you want to help out!
As the sole annotator, [I] can influence a dataset of my biases and errors. This is the limitation of this work.
We still want gold-annotated data ↵
This section will discuss how I annotated TLUnified to produce
gold-standard data. I’ll also introduce my benchmarking experiments to see how
baseline models perform on this dataset. For clarity, I’ll call the
annotated TLUnified as tl_tlunified_gold (tl - language code, tlunified -
data source, gold - dataset type).
I corrected annotations from a silver model… ↵
For the past three months, I corrected annotations produced by the WikiANN model. I learned that as an annotator, it’s easier to fix annotations than label them from scratch. I also devised annotation guidelines (Artstein, 2017) to make the annotation process more objective. Professor Nils Reiter has an excellent guide for developing these. Lastly, I also took inspiration from The Guardian’s work, which uses Prodigy for quotation detection.
For TLUnified, I used three labels for annotation:
- PER: person entities limited to humans. It may be a single individual or group (e.g., Juan de la Cruz, Nene, mga abogado).
- ORG: organization entities are limited to corporations, agencies, and other groups of people defined by an organizational structure (e.g., United Nations, DPWH, Meralco).
- LOC: location entities are geographical regions, areas, and landmasses. Subtypes of geo-political entities (GPE) are also included within this group (e.g., Pilipinas, Manila, Luzon)
Again, you can check the full annotation guidelines to see the nuances in labeling these entities.
Since there are still gaps in my annotation process, the annotations produced in
v1.0 of tl_tlunified_gold are not ready for production. Getting multiple
annotations and developing an inter-annotator agreement for several iterations
is the ideal case.
Nevertheless, I produced some annotations for around 7,000 documents. I split them between training, development, and test partitions and uploaded the v1.0 of raw annotations to the cloud. You can access the raw annotations and replicate the preprocessing step by checking out the GitHub repository of this project. The table below shows some dataset statistics:
tl_tlunified_gold| Tagalog Data | Documents | Tokens | PER | ORG | LOC |
|---|---|---|---|---|---|
| Training Set | 6252 | 198588 | 6418 | 3121 | 3296 |
| Development Set | 782 | 25007 | 793 | 392 | 409 |
| Test Set | 782 | 25153 | 818 | 423 | 438 |
…then benchmarked it with baseline NER approaches ↵
I want to see how standard NER approaches fare with tl_tlunified_gold. My
eventual goal is to set up training pipelines to produce decent Tagalog
models from this dataset. I made two sets of experiments, one involving word
vectors and the other using transformers. I aim to identify
the best training setup for this Tagalog corpus. I’m not pitting
one against the other; I want to set up training pipelines for both in the
future.
My eventual goal is to identify the best training setup for this Tagalog corpus. I’m not pitting one against the other; I want to setup training pipelines for both in the future.
First, I want to benchmark several word vector settings for NER. The baseline approach simply trains a model from the training and dev data, nothing more. Then, I will examine if adding word vectors (also called static vectors in spaCy) can improve performance. Finally, I will investigate if pretraining can help push performance further:
| Approach | Setup | Description |
|---|---|---|
| Supervised learning | Baseline | Train a NER model from scratch. No tricks, just the annotated data. |
| Supervised learning | Baseline + fastText | Source fastText vectors for the downstream NER task. |
| Supervised learning | Basline + fastText + pretraining | Pretrain spaCy’s token-to-vector layer while sourcing fastText vectors. |
The figure below shows the default setup for our word vector pipeline. The baseline approach won’t have any word vectors nor pretraining (Baseline). Then, we will use word vectors as additional features for training our statistical model (Baseline + fastText). Lastly, we will use pretraining to initialize the weights of our components (Baseline + fastText + pretraining).
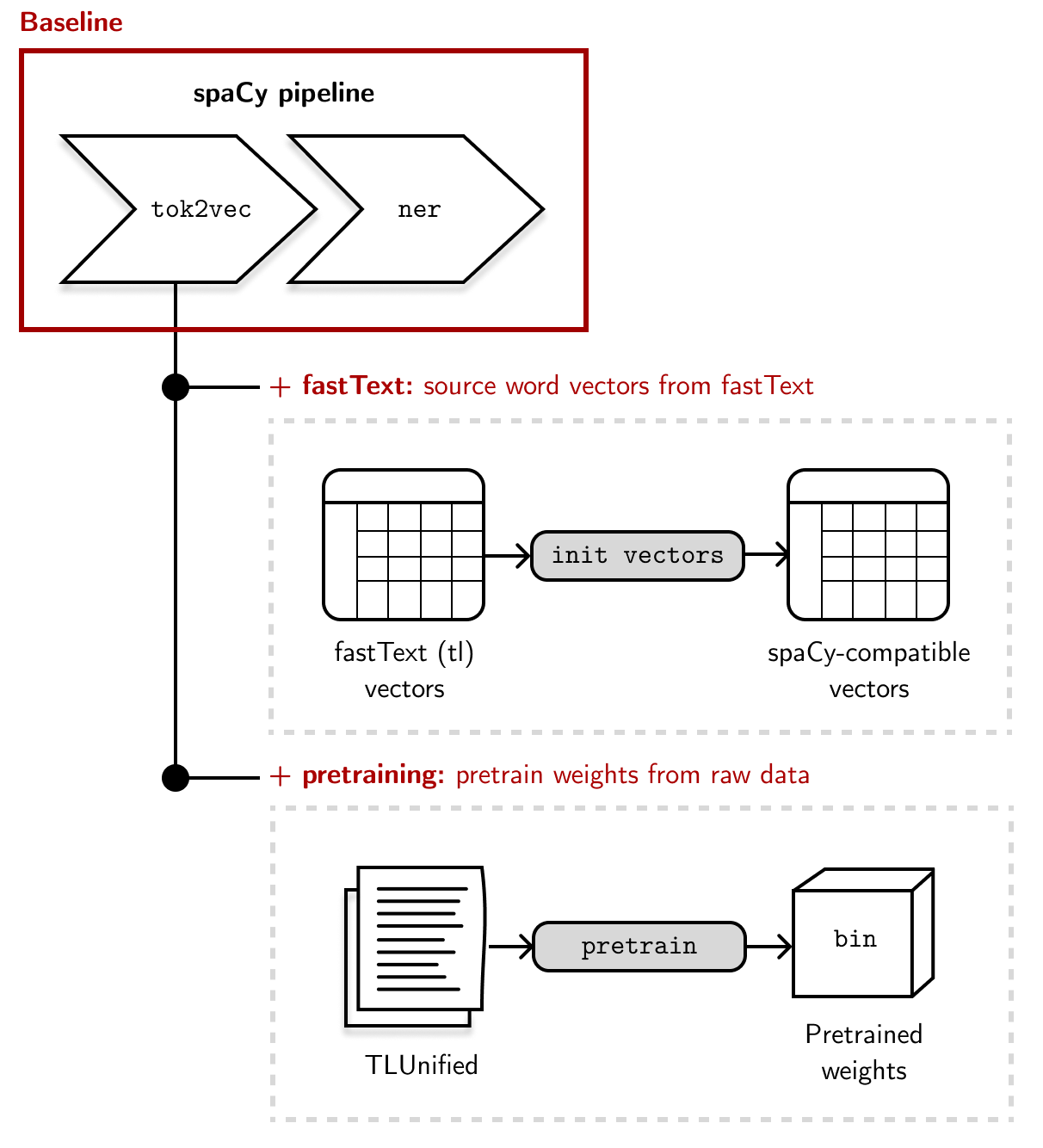
Next, I will measure the performance of a monolingual and multilingual language model. I’m using transformer models as a drop-in replacement for the representation layer to achieve higher accuracy:
| Approach | Language Models | Description |
|---|---|---|
| Few-shot learning | roberta-tagalog | Monolingual experiment with a large RoBERTa model trained from TLUnified. I will be testing both base and large variants. |
| Few-shot learning | xlm-roberta | Multilingual experiment with a large XLM-RoBERTa. Trained on 100 different languages. I will be testing both base and large variants. |

Again, I want to use what I learned from these experiments to set up a training
scheme for a Tagalog pipeline down the road. Something akin to en_core_web_lg
or en_core_web_trf in spaCy, but for Tagalog. For all the experiments above, I
will use spaCy’s transition-based
parser for sequence labeling.
Experimental Results ↵
The results below aim to answer eventual design decisions for building NLP pipelines for Tagalog. I plan to create a word vector-based and language model-based training setup. If you’re interested in replicating my results, check out the spaCy project in Github! Lastly, because we’re doing a bit of hyperparameter tuning here (choosing the proper config, etc.), I will report the results as evaluated on the dev set to avoid overfitting.
The results below aim to answer eventual design decisions for building NLP pipelines for Tagalog. I plan to create a word vector-based and language model-based training setup.
I ran each experiment for three trials, and I will report their mean and standard deviation.
Finding the best word vector training setup ↵
To find the best word vector training setup, I designed an experiment to test how static vectors and pretraining can improve performance. The baseline approach has none of these; it simply trains a model from scratch. Then, I sourced static vectors and, eventually, a set of pretrained weights. Within these two, there are still design choices left to be made:
-
On static vectors: by default, I’m using the vectors available from the fastText website. These were trained from CommonCrawl and Wikipedia. I’d like to know if it matters if I train my own fastText vectors from TLUnified and if there are efficiency gains when using floret vectors.
-
On pretraining: by default, my pretraining objective is based on characters, i.e., the model is tasked to predict some number of leading and trailing UTF-8 bytes for the words. However, spaCy also provides another pretraining objective based on a static embeddings table. I’d like to know which one is more performant between the two.
The table below shows the performance, using default settings, for our three training scenarios. The results suggest that using a combination of static vectors and pretraining can improve F1-score by at least 2pp.
| Setup | Precision | Recall | F1-score |
|---|---|---|---|
| Baseline | 0.87±0.01 | 0.87±0.01 | 0.87±0.00 |
| Baseline + fastText* | 0.89±0.01 | 0.86±0.01 | 0.88±0.00 |
| Baseline + fastText* + pretraining | 0.89±0.01 | 0.89±0.01 | 0.89±0.00 |
* 714k keys and unique vectors. Vectors were sourced from the fastText website.
It’s also worth noting that the baseline result (87% F-score) where we trained a model without any static vectors nor pretrained weights performs well! Of course, we want to push these scores further so in the next sections, I’ll be exploring alternative configurations for our word vector pipeline.
On static vectors: it is worth training floret vectors ↵
In the previous experiment, I used the fastText vectors provided by the fastText website. These vectors were trained from CommonCrawl and Wikipedia. I’m curious if I can achieve better performance if I train my own vectors.
I trained two sets of word vectors from TLUnified, one based on fastText and the
other on floret. Both vectors were
trained using the skipgram
model,
with a dimension of \(200\), and a subword minimum (minn) and maximum size
(maxn) of \(3\) and \(5\) respectively.
Lastly, I also removed the annotated texts from TLUnified during training to ensure no overlaps will influence our benchmark results. These results can be seen in the table below:
| Word Vectors | Unique Vectors* | Precision | Recall | F1-score |
|---|---|---|---|---|
| fastText (default: CommonCrawl + Wikipedia) | 714k | 0.89±0.01 | 0.86±0.01 | 0.88±0.00 |
| fastText (TLUnified) | 566k | 0.89±0.01 | 0.88±0.00 | 0.88±0.01 |
| floret (TLUnified) | 200k | 0.88±0.01 | 0.88±0.01 | 0.88±0.00 |
* This time, we’re talking about unique vectors, not keys. Several keys can map to the same vectors, and floret doesn’t use the keys table.
We can also inspect the cosine similarity of subword pairs between related and unrelated terms. Here I’m using the vectors from fastText and floret, both trained with TLUnified:


The results suggest that the floret vectors were able to keep the correlation between subtokens intact despite its smaller size (\(700k\) → \(200k\)). So perhaps training my own fastText vectors isn’t worth it, but exploring floret is. In addition, this efficiency gain has little to no performance penalty, as seen in Table 6. So let’s see what happens if I train floret with bucket sizes of 100k, 50k, and 25k:
floret vector performance on different vector table sizes. All *vectors were trained using TLUnified. Evaluated on the development set.| Unique Vectors | Precision | Recall | F1-score |
|---|---|---|---|
| 200k | 0.88±0.01 | 0.88±0.01 | 0.88±0.00 |
| 100k | 0.88±0.00 | 0.87±0.00 | 0.88±0.01 |
| 50k | 0.86±0.01 | 0.85±0.01 | 0.85±0.00 |
| 25k | 0.82±0.02 | 0.82±0.01 | 0.81±0.00 |
There was a slight degradation in performance when I adjusted the bucket size from \(200k\) to \(25k\). It’s not as drastic as I expected, but it’s interesting to see the pattern. There’s even a case for using \(100k\) rows in floret, but for now, I’ll stick to \(200k\).
On pretraining: there is no significant difference between the two pretraining objectives ↵
spaCy provides two optimization objectives to pretrain the token-to-vector
weights from raw data:
PretrainCharacters and
PretrainVectors. Both
use a trick called language modeling with approximate outputs (LMAO), in which
we force the network to model something about word co-occurrence.
Using their default values, I ran an experiment that compares the two. Similar to the previous experiment, I also removed overlaps between the final dataset and the pretraining corpus to ensure that they won’t affect the results:
| Pretraining objective | Precision | Recall | F1-score |
|---|---|---|---|
PretrainCharacters |
0.89±0.01 | 0.89±0.01 | 0.89±0.00 |
PretrainVectors |
0.90±0.01 | 0.89±0.00 | 0.90±0.00 |
The results suggest that there is no significant difference between the two.
PretrainVectors has a slight edge on precision, but it’s not apparent.
However, for an agglutinative language like Tagalog, our pipeline might benefit
from a model with some knowledge of a word’s affixes, so I’ll use
PretrainCharacters for the final pipeline.
Some notes for the final word vector pipeline ↵
In the future, I hope to create pipelines akin to spaCy’s en_core_web_md or
en_core_web_lg but for Tagalog. I’ll settle for the following setup:
- Train floret vectors from TLUnified. spaCy’s floret vectors provide
efficiency with no cost to performance. The F1-scores are competitive even with the
vectors sourced from fastText (trained on CommonCrawl and Wikipedia). The size
of the model (i.e., if it’s medium (
*_md) or large (*_lg)) can then be a function of the hash table size. - Pretrain token-to-vector weights using the ‘characters’ objective. Pretraining gives a decent boost to performance. I also think the “characters” objective can better model the structure of Tagalog words. Lastly, I only pretrained for \(5\) epochs (\(12\) hours!), so I might push it to \(10\) or more in the final pipeline.
- Hyperparameter tuning. I’ve been using the default training and NER parameters throughout my experiments. I prefer starting from a crude pipeline and moving on to its finer points. I’ll spend some time doing a hyperparameter search using WandB and see if there are more optimizations I can do.
Finding the best language model training setup ↵
With spaCy’s Huggingface
integration, finding a decent
language model as a drop-in replacement for our token-to-vector embedding layer
is much faster. Previously, we slotted a tok2vec
embedding layer that downstream components like
ner use. Here, we effectively replace
that with a transformer model. For example, the English transformer model
en_core_web_trf uses RoBERTa
(Liu, et al., 2019) as its base. We want transformers because
of their dense and context-sensitive representations, even if they have higher
training and runtime costs.
Luckily, Tagalog has a RoBERTa-based model. The
roberta-tagalog-large
was trained using TLUnified and was benchmarked on multilabel text
classification tasks (Cruz and Cheng, 2022). The large
model has 330M parameters, whereas the base model has 110M. I’ll use both
variants throughout the experiment as my
monolingual language model of choice.
The only limitation in this setup is that roberta-tagalog-large was also
trained on parts of TLUnified that I annotated, so it may have some information
regarding my test set. However, I don’t want to pretrain my own transformer
model for now without the overlapping texts, so I’ll use this language model as
it is. I just want to caveat that this setup may have inflated my reported
scores.
On the other hand, I also want to benchmark with a multilingual transformer model. The XLM-RoBERTa (XLM-R) model may be a good fit (Conneau, et al., 2019). It was pre-trained on text in 100 languages, including Tagalog. Most of its data source came from a cleaned version of CommonCrawl, with Tagalog containing 556 million tokens and 3.1 GiB in size. My hope is that the XLM-R model can take advantage of learned representations from morphologically similar languages for our downstream task.
I finetuned these language models for three trials on different random seeds. The results can be seen in the table below:
| Language Model | Precision | Recall | F1-score |
|---|---|---|---|
| roberta-tagalog-large | 0.91±0.01 | 0.91±0.02 | 0.91±0.01 |
| roberta-tagalog-base | 0.90±0.01 | 0.89±0.01 | 0.90±0.00 |
| xlm-roberta-large | 0.88±0.00 | 0.88±0.00 | 0.89±0.01 |
| xlm-roberta-base | 0.87±0.02 | 0.87±0.01 | 0.88±0.01 |
I didn’t expect the two models to be on par with one another. In addition, the performance of our word vector pipeline (floret + pretraining) is competitive with our transformer approach. Training for the base models took around four hours in an NVIDIA V100 GPU (I’m using Google Colab Pro+) and twelve to fifteen hours for the larger ones.
Some notes for the final transformer pipeline ↵
In the future, I hope to create a transformer-based model similar to spaCy’s
en_core_web_trf for Tagalog. I’ll settle for the following setup:
- Use
roberta-tagalog-*as the transformer model. I hypothesize that a model trained specifically for a given language should outperform a “generalist” language model. I will keep tabs on XLM-R but shift focus on building uponroberta-tagalog. - Hyperparameter tuning. Like the word vector pipeline, I need to conduct hyperparameter search for my transformer pipeline. Playing around the training and span-getter parameters might be a good starting point.
Evaluating our pipelines ↵
We now have a word vector and transformer-based pipeline. The former uses floret
vectors with pretraining, while the latter takes advantage of the
roberta-tagalog-* language model. Let’s do a few more
evaluation to wrap things up. For now I’ll be calling them tl_tlunified_lg and
tl_tlunified_trf to be consistent with spaCy’s model naming convention:
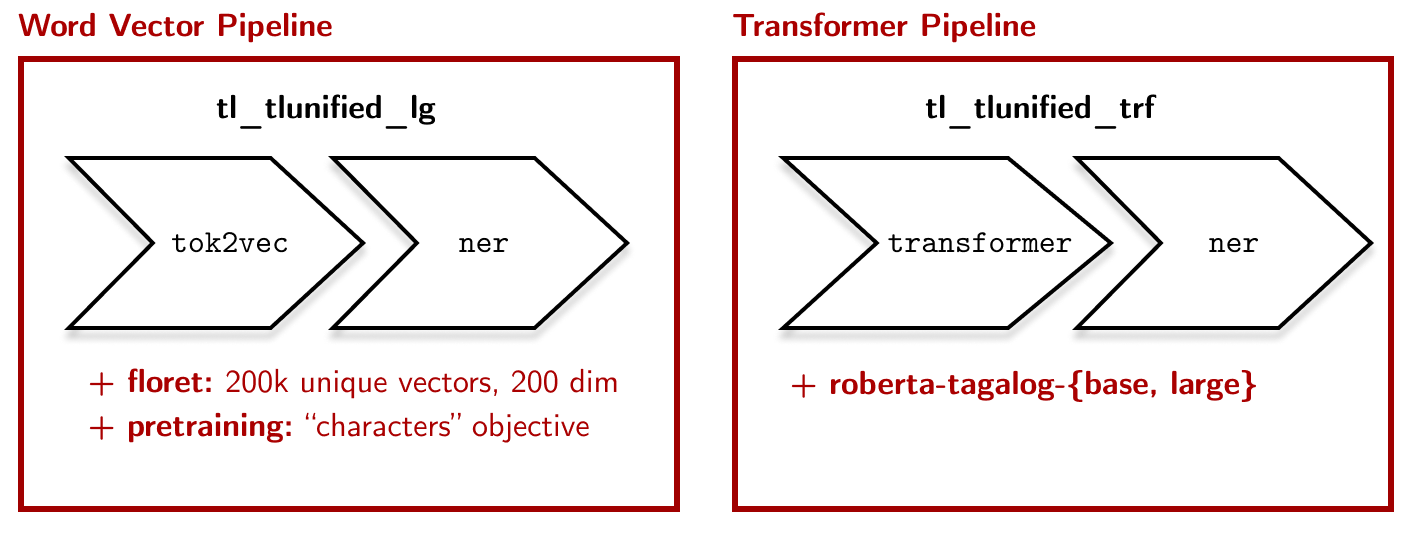
Let’s evaluate their performance on the test set:
| Pipeline | Precision | Recall | F1-score |
|---|---|---|---|
| tl_tlunified_lg | 0.85±0.01 | 0.86±0.02 | 0.86±0.02 |
| tl_tlunified_trf (base) | 0.87±0.02 | 0.87±0.01 | 0.87±0.01 |
| tl_tlunified_trf (large) | 0.89±0.01 | 0.89±0.00 | 0.90±0.02 |
We can see a performance difference between the transformer and word vector pipelines (around 4pp). Let’s see the per-entity results:
| Pipeline | PER | ORG | LOC |
|---|---|---|---|
| tl_tlunified_lg | 0.88±0.02 | 0.77±0.02 | 0.86±0.00 |
| tl_tlunified_trf (base) | 0.90±0.01 | 0.80±0.02 | 0.87±0.01 |
| tl_tlunified_trf (large) | 0.92±0.01 | 0.81±0.02 | 0.87±0.00 |
Lastly, let’s look at our pipelines’ performance on unseen entities. Here, we define an unseen test set that contains entities not seen by the model during training. This evaluation allows us to check how a model responds to entities it newly encounters. The way I split the texts is naive: I based them on the orthographic representation of the words. For example, entities like “Makati City” and “Lungsod ng Makati” will be treated as separate entities even if they point to the same location. For the gold-annotated TLUnified, our unseen test set has 784 documents.
| Pipeline | Precision | Recall | F1-score |
|---|---|---|---|
| tl_tlunified_lg | 0.75±0.01 | 0.83±0.02 | 0.79±0.01 |
| tl_tlunified_trf (base) | 0.85±0.00 | 0.84±0.02 | 0.84±0.02 |
| tl_tlunified_trf (large) | 0.88±0.02 | 0.88±0.00 | 0.88±0.00 |
The scores are what we expect. All pipelines dropped their performance when they encountered previously unseen entities. However, note that the transformer pipelines may have test set leakage during their pretraining, causing it to inflate the scores. On the other hand, I have better control of the word vector pipeline to run pretraining without the unseen test set.
Conclusion ↵
In this blog post, I outlined my progress in building an NLP pipeline for Tagalog. I started with the named-entity recognition (NER) task because it is a crucial problem with many applications. I talked about…
- ..how I created a gold-annotated corpus for Tagalog. I used a larger dataset called TLUnified and pre-annotated it with predictions from a silver-standard model trained from WikiANN. I then corrected its annotations using Prodigy, thereby producing around 7000+ documents.
- …how I built a word-vector and language model-based pipeline. I did some tests
to decide the best setup for my two pipelines. The word vector pipeline consists
of a hash table trained from floret and a pretrained token-to-vector weight
matrix. On the other hand, the language model pipeline is based on
roberta-tagalog. I also tested how a multilingual model like XLM-R fares on the dataset. - …how I evaluated each pipeline. Aside from the benchmarking tests, I evaluated each pipeline on the held-out test set and a test set with previously-unseen entities. The transformer-based models worked well, while the word vector-based model is still competitive.
To summarize the process above, we have this figure below. I hope that this simplifies the whole procedure on building an NLP pipeline:
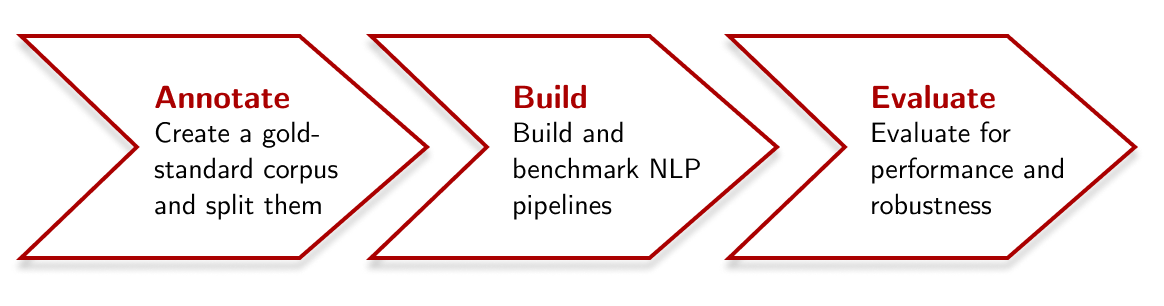
Next steps ↵
There are still a lot of things I want to do. Let’s use the same figure to talk about the potential next steps for this work:
- On annotation. Right now, the annotations were from me. Although I wrote myself an annotation guideline, it isn’t enough to make the labels more objective and error-free. Having multiple annotators and computing for inter-annotator agreement may be the best option.
- On building the pipeline. I want to spend some time performing
hyperparameter search to optimize the NLP pipelines. For the word vector
pipeline, it may also be good to do degradation tests to see how the pretrained
weights respond to dataset size. In the future, I see myself adding more
components to this pipeline, not just
ner. For example, some folks at the University of the Philippines are creating a larger Tagalog UD Treebank. I can tap into their corpus to train a dependency parser and parts-of-speech (POS) tagger for my existing pipelines. - On evaluation. Aside from evaluating a held-out test set and previously-unseen entities, I want to improve the evaluation scheme and include perturbations and irregular train-test splits (Vajjala and Balasubramaniam, 2022, Søgaard, et al., 2021).
Caveats ↵
As I’ve prefaced at the beginning of this blog post, I do not recommend using this for production. This NLP pipeline is still a work in progress, and I’m developing ways to make the model more robust. Here are the limitations of this work:
- The gold-annotated dataset was labeled by a single annotator. Ideally, this would be done by multiple annotators to limit bias and errors. You can get the annotated dataset now but use it with caution.
- The pipelines to date still need to be optimized. I still need to perform a more thorough parameter search to improve the results. This applies to both the word vector and language model-based pipelines.
- The evaluation still needs a bit of work. Although evaluating on the test set and unseen entities may be standard practice, I’d like to investigate more on which instances the model works.
The Tagalog corpus is the biggest bottleneck. Increasing the amount of gold-annotated data or increasing the reliability of silver-standard annotations should be a priority. The former is a bit of a brute-force approach, but I think that sometimes we just need to sit down, tackle the problem, and start annotating.
Final thoughts ↵
In Tagalog, we have this word called diskarte. There is no direct translation in English, but I can describe it loosely as resourcefulness and creativity. It’s not a highly-cognitive trait: smart people may be bookish, but not madiskarte. It’s more practical, a form of street smarts, even. Diskarte is a highly-Filipino trait, borne from our need to solve things creatively in the presence of constraints (Morales, 2017). I mention this because working in Tagalog, or any low-resource language, requires a little diskarte, and I enjoy it!
There are many exciting ways to tackle Tagalog NLP. Right now, I’m taking the standard labeling, training, and evaluation approach. However, I’m interested in exploring model-based techniques like cross-lingual transfer learning and multilingual NLP to “get around” the data bottleneck. After three months (twelve weekends, to be specific) of labeling, I realized how long and costly the process was. I still believe in getting gold-standard annotations, but I also want to balance this approach with model-based solutions. However, I still believe that getting enough annotations to support a structured dataset evaluation is worth it.
I wish we had more consolidated efforts to work on Tagalog NLP. Right now, I noticed that research progress for each institution is disconnected from one another. I definitely like what’s happening in Masakhane for African languages and IndoNLP for Indonesian. I think they are good community models to follow. Lastly, Tagalog is not the only language in the Philippines, and being able to solve one Filipino language at a time would be nice.
Right now, I’m working on calamanCy, my attempt to create spaCy pipelines for Tagalog. Its name is based on kalamansi, a citrus fruit common in the Philippines. Unfortunately, it’s something that I’ve been working on in my spare time, so progress is slower than usual! This blog post contains my experiments on building the NER part of the pipeline. I plan to add a dependency parser and POS tagger from Universal Dependencies in the future.
That’s all for now. Feel free to hit me up if you have any questions and want to collaborate! Maraming salamat!
References
- Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised Cross-lingual Representation Learning at Scale. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451, Online. Association for Computational Linguistics.
- David Mortensen. 2017. Low-Resource NLP (Algorithms for Natural Language Processing slides).
- Kyle Gorman and Steven Bedrick. 2019. We Need to Talk about Standard Splits. In Anna Korhonen, David Traum, and Lluís Màrquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2786–2791, Florence, Italy. Association for Computational Linguistics.
- Jan Christian Blaise Cruz and Charibeth Cheng. 2022. Improving Large-scale Language Models and Resources for Filipino. In Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Jan Odijk, and Stelios Piperidis, editors, Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 6548–6555, Marseille, France. European Language Resources Association.
- Jan Christian Blaise Cruz and Charibeth Cheng. 2019. Evaluating Language Model Finetuning Techniques for Low-resource Languages. Preprint, arXiv:1907.00409.
- Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach. Preprint, arXiv:1907.11692.
- Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors, Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6282–6293, Online. Association for Computational Linguistics.
- Ron Artstein. 2017. Inter-annotator Agreement. In Nancy Ide and James Pustejovsky, editors, Handbook of Linguistic Annotation, pages 297–313. Springer, Dordrecht.
- Anders Søgaard, Sebastian Ebert, Jasmijn Bastings, and Katja Filippova. 2021. We Need To Talk About Random Splits. In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty, editors, Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1823–1832, Online. Association for Computational Linguistics.
- Sowmya Vajjala and Ramya Balasubramaniam. 2022. What do we really know about State of the Art NER? In Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bente Maegaard, Joseph Mariani, Hélène Mazo, Jan Odijk, and Stelios Piperidis, editors, Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 5983–5993, Marseille, France. European Language Resources Association.
- Xiaoman Pan, Boliang Zhang, Jonathan May, Joel Nothman, Kevin Knight, and Heng Ji. 2017. Cross-lingual Name Tagging and Linking for 282 Languages. In Regina Barzilay and Min-Yen Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1946–1958, Vancouver, Canada. Association for Computational Linguistics.
- Yulia Tsvetkov. 2017. Opportunities and Challenges in Working with Low-Resource Languages. Slides.
- Marie Rose H. Morales. 2017. Defining Diskarte: Exploring Cognitive Processes, Personality Traits, and Social Constraints in Creative Problem Solving. Philippine Journal of Psychology, 50(2).