
Navigating the MLOps tooling landscape (Part 1: The Lifecycle)
This is the first of a three-part blog post on the MLOps landscape. Here, I’ll talk about the ML Lifecycle, and the personas or roles that pushed it the way it is.
A few years ago, I wished that more tools supporting ML in production become mainstream. Back then, models usually get stuck in Jupyter Notebooks, and they often require an engineer to deploy them. A self-service solution is the dream.
It seems that my wish was granted, as slew of startups pop up, promising a better way to productionize ML. The major cloud platforms are taking a stab on it too. Now, I face the opposite problem: there are too many options, and it’s difficult to choose!
Welcome to MLOps, a very exciting field that marries software engineering and machine learning. There’s an academic field for it (Ratner, et al, 2019), and wow, the industry is booming.
Contents
In this three-part blogpost, I’ll attempt to navigate the MLOps landscape. I’ll be focusing on the commercial side, i.e., the tools, startups, and frameworks that I’ve seen while I answer three key questions:
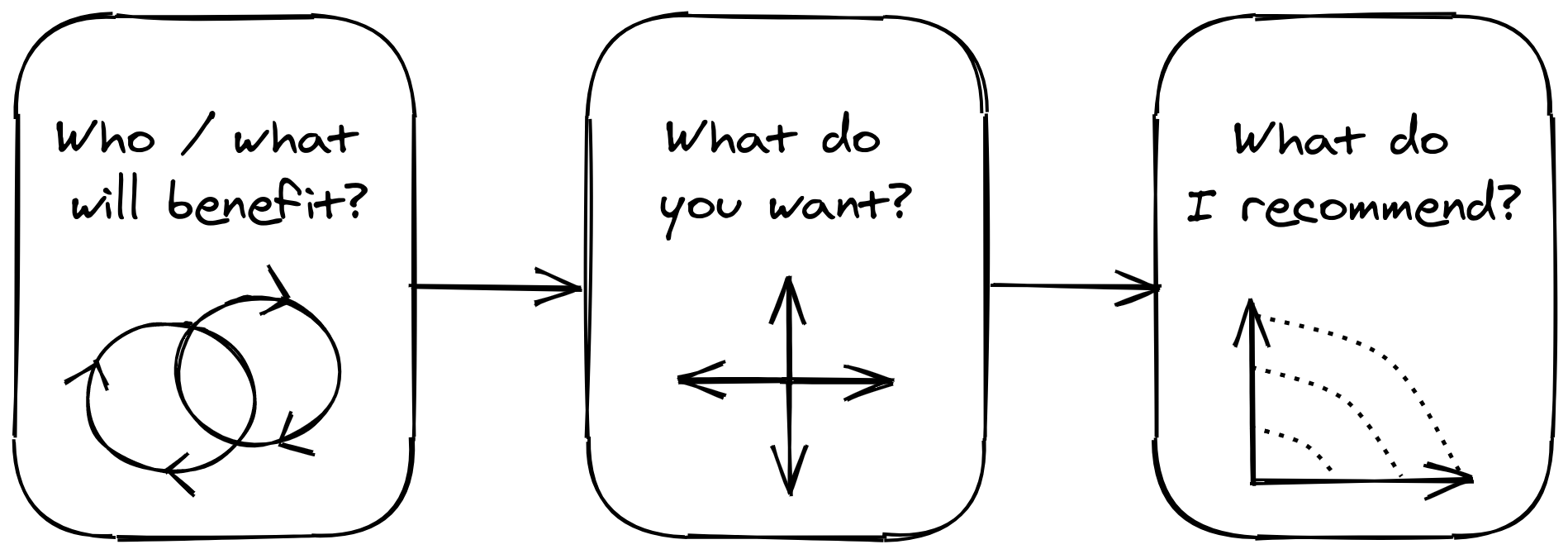
- Who/what will benefit?: we’ll set the stage by asking who will benefit by adopting these tools. Here, I’ll introduce my version of the ML lifecycle. (This page)
- What do you want?: I’ll describe a framework for categorizing MLOps tools, and outline a specific adoption strategy for each group. (Will be published on May 15)
- What do I recommend?: I’ll list down some decision frameworks I recommend based from experience and research. (Will be published on May 30)
Note that I won’t be reviewing each and every tool in existence! Instead, I’ll provide a framework for thinking about these groups, and in addition, a strategy for adopting them. I may recommend some based from my experience, but your mileage may vary.
How is this different?
There are already tons of resources exploring the MLOps landscape. The most notable ones are from Chip Huyen, where she surveyed tools, explored case-studies, and analyzed trends. I highly recommend that you read them— they’re insightful and informative!
However, like most resources, they are most effective if you already know what you want.
I liken this to eating in a new restaurant. You sit at a table, the waiter approaches, and he presents you a menu. They’re all neatly categorized with brief descriptions and price points. If you don’t know what you want, the menu is going to be overwhelming—simply an effect of the paradox of choice.

In that situation, what I’d usually do is ask the waiter: “what’s the bestseller?,” “I want something light and cheap,” “what’s perfect for this hot weather?” Then he narrows down my choices into something palatable. What he just did is to:
- Meet me where I am: understand is my current situation
- Identify what I may want: assess my situation and bridge it to the menu
- Recommend food based on my wants: make an opinionated statement based on collected info
The waiter helped me narrow-down my choices into two to three most relevant dishes. That’s enough for me to choose what I’ll eat, and be on my merry way. It’s just a three-step process of cutting things down, but it eliminated my paralysis brought by having too many options.
For the keen-eyed, you’ll notice that each step maps to each post of this series. Part One will describe the current state of most ML orgs today. Part Two will use that info to bridge us into a more understandable landscape. Lastly, Part three will recommend strategies for adopting these tools.
Hopefully, this series can be that waiter for the MLOps ecosystem.
Who or what will benefit?
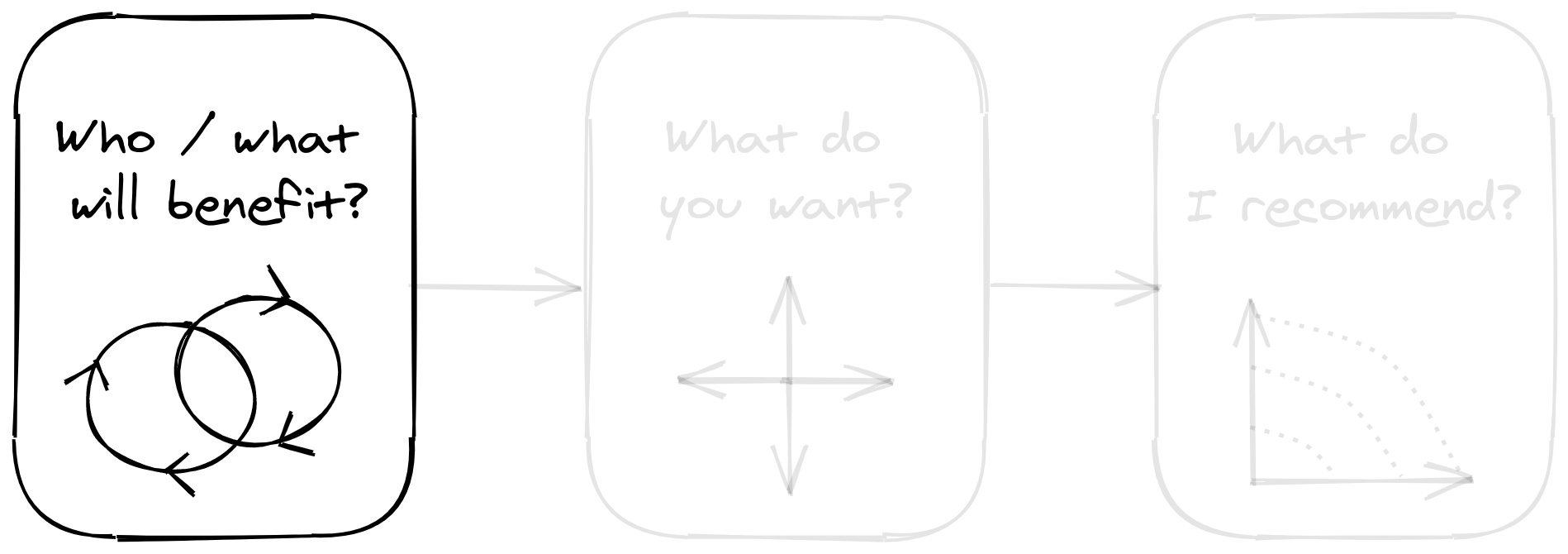
To set the stage, I want to discuss the use-cases MLOps can solve and the roles affected by them. MLOps satisfies two personas: (1) the machine learning researcher, and (2) the software engineer. These roles tend to work closely with one another, yet a gap often exists in their dynamic:
| Persona | Wants | Frustrations | Needs |
|---|---|---|---|
| Machine Learning Researcher | I want to focus on what I do best: training models, deriving features, etc. | Bringing a model to production takes considerable effort | Eliminate lead time for productionizing models |
| Software Engineer | I want a seamless way of putting models into production | It’s counter-productive to keep translating / integrating research code to our systems | Ensure best-practices are followed right off-the-bat |
Most organizations employ two tactics to quell their frustrations:
- Hire a hybrid of the two—the ML Engineer. They can be software engineers that are looking to do more ML, or researchers interested in flexing their software engineering muscles.
- Upskill ML Researchers with SWE skills. Teach researchers how to use git, basic CI/CD practices, and modularization. I am still a big proponent of this idea.1
The table above helps clarify the use-cases MLOps tools provide. By looking at their needs, we have:
- Self-serve machine learning: the goal is to cut the middleman between experimental and production artifacts. A model trained from a notebook should be no more difficult to deploy than a model built from production code.
- Follow software best practices: ML can be treated as a software component, so it must be created with the same rigor. This has an underlying assumption that following software best practices is always good—of course, that may or may not always be true for ML.
Together, they bring about the ML lifecycle. Improving this process should increase the quality of life of ML Researchers and software engineers. Investing on MLOps tools should benefit the ML lifecycle.
On the machine learning lifecycle
The machine learning lifecycle describes a model’s journey from experimentation to deployment. Usually, I observe that:
- There is an emphasis on ML models as the final artifact for most teams, and
- Deployment often means exposing said artifact as a software component.
Each person may have a different way of defining and describing its processes, but I always imagine it as two cycles looping together:

I always imagine the machine learning process as two cycles looping together
The leftmost loop caters most to software engineers, whereas the rightmost loop is for researchers. In some organizations, you might see researchers getting involved in the SWE loop— they babysit the training of their models, then accompany them to production.
I won’t belabor describing each component in the lifecycle, as I’m sure you’ll find better explanations for them in the interwebs. However, there are some key observations that I want to surface:
- The ML lifecycle involves a loop for both software and model development: They often map to our two personas above, but you might see an ML Engineer or Researcher doing both.
- The ML lifecycle involves discrete components that work together: as a lookahead, we’ll see that MLOps tools provide solutions that can improve the lifecycle by piecemeal, or as a whole.
This will serve as our lens in navigating the MLOps landscape. It describes how our two personas—the software engineer and the researcher— interact with one another. A good MLOps tool should provide their needs, answer their wants, and quell their frustrations.2
A good MLOps tool should provide [our researchers’ and engineers’] needs, answer their wants, and quell their frustrations.
Conclusion
In this section, we asked the question “who will benefit?” to motivate this endeavour. We learned of two personas: the ML Researcher and the Software engineer. They work closely together, yet their dynamic is not always seamless.
We examined their Wants, Needs, and Frustrations, then came upon my interpretation of the ML Lifecycle, i.e., two interlocking loops catering to each of our personas. The ML lifecycle provides a lens to navigate the MLOps landscape:
- When asked, “who will benefit?”, our answer is researchers and engineers.
- When asked, “what will benefit?”, our answer is the ML lifecycle.
We will look into this further in the next section, as we describe tools that (1) are software-focused or model-focused, and (2) provides a piecemeal or all-in-one solution. Remember, all of these will always bring us back to the ML lifecycle, and again, to our two personas.
Changelog
- 06-01-2021: This blog series was featured in Issue 19 of the MLOps Roundup Newsletter!
- 05-28-2021: This blog series was featured in Analytics Vidhya!
- 05-22-2021: Added a section explaining how this differs to other analyses
- 05-22-2021: Fix some minor grammar and usage issues.
Next Sections
- Part II: Navigating the MLOps Landscape—The Ecosystem
- Part III: Navigating the MLOps Landscape—The Strategies
If you like this, you’ll enjoy:
Resources
- Huyen, Chip (2020). “CS 329S: Machine Learning Systems Design”. In: stanford-css329s.github.io
- Ratner, Alexander, Alistarh, Dan, Alonso, Gustavo et al (2019). “MLSys: The New Frontier of Machine Learning Systems”. In: arXiv:1904.03257 [cs.LG]
- Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, and D. Dennison, “Hidden technical debt in machine learning systems”, in Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, 2015, pp. 2503–2511. [Online]. Available: http://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems
- Zinkevich, Martin. (2017). “Rules of machine learning: best practices for ML Engineering”. Available: https://developers.google.com/machine-learning/guides/rules-of-ml