How to use Jupyter Notebooks in 2020 (Part 1: The data science landscape)
This is the first of a three-part blog post on the Jupyter Notebook ecosystem. Here, I’ll talk about the data science landscape, and the forces that pushes our tools to evolve.
Ah, Jupyter Notebooks. Love it or hate it, they’re here to stay. The last time I wrote about them was two years ago (it’s about running a notebook from a remote server), and the ecosystem has grown ever since—even how I interact with notebooks totally changed!
In this multi-part blogpost, I’d review my oft-used tool in the data science toolbox, Jupyter Notebooks, and how I use them in modern times. I divided this post into three:
- Part I: The data science landscape (This page). I’d like to look into how the practice of data science has changed for the past few years. Then, I’ll zoom into the three main forces that changed the way I use Notebooks today.
- Part II: How I use Notebooks in 2020. Given these changes, new tools in the Notebook ecosystem emerged. I’d like to share what I like (and don’t like) about them, and how I use them in my day-to-day.
- Part III: Notebooks and the future. Here I’ll share my wishlist for Notebooks, potential gaps that the community can still fill-in, and why Notebooks are still awesome!
To give context, a little more about me: as a data scientist, I alternate between doing analyses on notebooks and writing production code for data products. My work environment is highly-collaborative so I don’t just review code, I also read (and attempt to reproduce) others’ notebook analyses. With that said, I have a strong bias to production code and software best practices, yet I still use notebooks in my day-to-day.
The data science landscape today
The field of data science is rapidly changing . We’ve now entered a time where phrases like “sexiest job of the 21st century” and “data is the new oil” have become old and replaced by more realistic business problems and grounded technical challenges. I see this change as two-fold: we now need to support both the (1) demand for productionizing analyses and experiments, and the (2) rapid adoption of the Cloud.
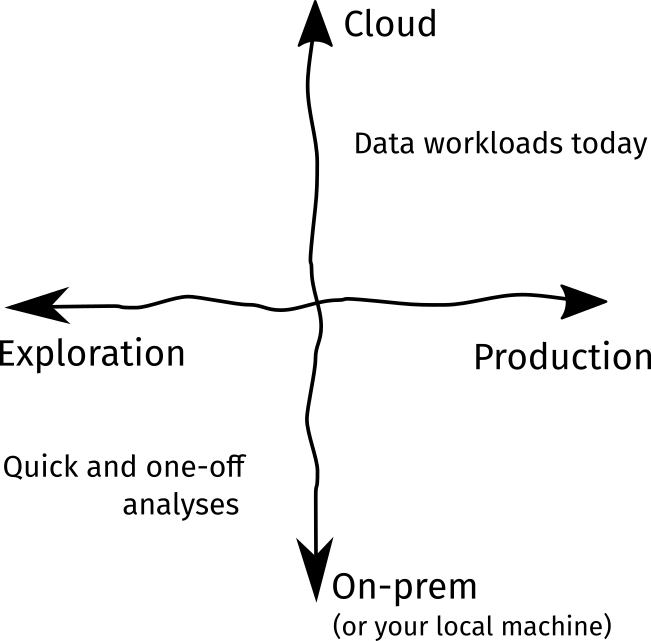
Figure: A simplified framework on how to think about the advancements in
the data science process for the past years
First, the need for production, i.e., creation of data products or deploying experiment artifacts within the software engineering lifecycle, has grown through the years. This is evidenced by an uptake for more engineering type of work with the rise of machine learning engineers and data science software developers. Furthermore, analyses aren’t confined anymore inside publications or charts, for there is now a growing demand for experiments to be reproduced and its artifacts to be deployed.
Next, the exponential increase of data necessitates the adoption of the Cloud. We cannot just load a 1TB dataset in pandas using our own laptops! The popularity of tools like Docker and Kubernetes allowed us to scale our data-processing workloads at unprecedented levels. Cloud adoption means that we take care of scaling, resource provisioning, and infrastructure when managing our workloads. However, the previous Jupyter Notebook ecosystem, as much as it is a staple in the data scientist toolbox, isn’t meant for these changes:
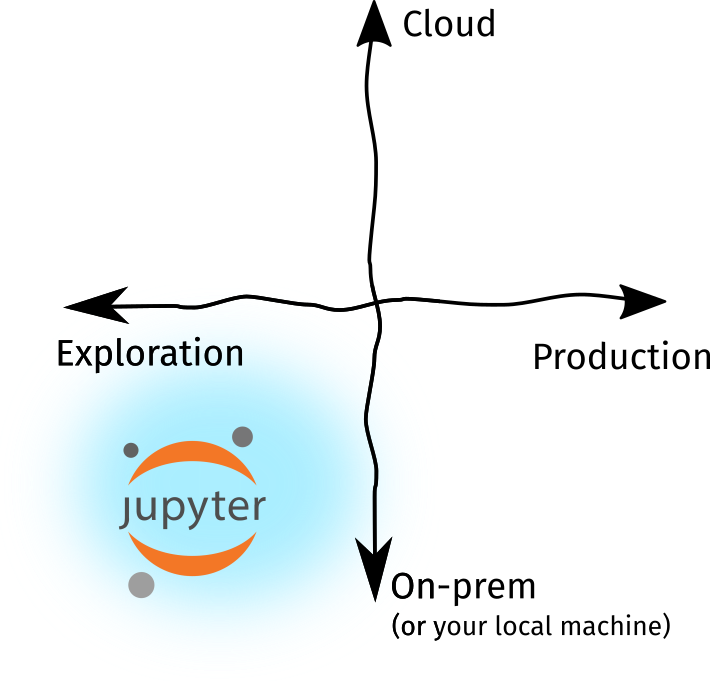
Figure: The Notebooks we know only cover a small domain of the data science
ecosystem
As I’ve said, the Jupyter Notebook we’ve come to know isn’t meant for these changes.
They’re meant for exploration, not production. They’re meant to run in a single
machine, not a fleet of pods. However, for the past five years, the Jupyter
Notebook ecosystem has grown: we now have JupyterLab, several plugins, new kernels
for other languages, and third-party tooling available at our disposal. Sure,
we can still run notebooks by typing jupyter notebook in our terminals, but
it’s now more than that!
This then begs the question: what are the forces that prompted these changes?, and how can we leverage this larger notebook ecosystem to respond to the changes in data science today?
The three forces of change
The Jupyter Notebook ecosystem is growing, and I posit that this is driven by three forces:
- Experiment on the Cloud: big data demands large compute and storage, something that your average consumer-grade machine will not always be capable of.
- Support for developer workflow: more and more data science teams are starting to adopt software engineering best practices—version-control, gitfow, pull requests, and more.
- Quick turnaround from analysis to production: it’s not enough to test hypotheses under controlled environments. Software written for analysis should be easily reused for prod.
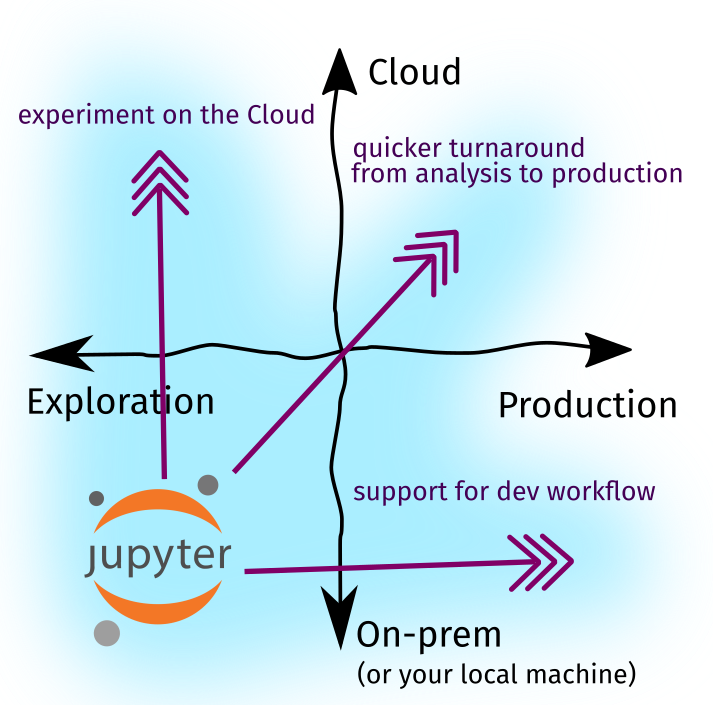
Figure: The growth of the Notebook ecosystem is driven by these forces
Growing towards a more Cloud-first environment means that we can perform Notebook-based tasks in machines more powerful than our own. For example, managed notebook instances enabled us to run Jupyter notebooks from a remote server with no-ops and setup. On the other hand, growing towards a more Production workflow provides us with a set of tools to endow our notebook-based tasks with software engineering practices. We’ll see more of these tools in the next part of this post.
Finally, note that the growth of a tool doesn’t depend on a single entity or organization. As we will see later on, filling these gaps may stem from individuals who contribute third-party plugins or organizations offering managed services from notebooks.
Conclusion
In the first part of this series, we looked into the two drivers of growth in the data science landscape: the (1) adoption of the Cloud, and the (2) increasing demand for production. We saw that Jupyter Notebooks only fill a small part of this ecosystem, i.e., it’s often used for exploration (not production) and only ran in our local machines (not in the Cloud).
Then, using that same framework, we identified three forces of change that allowed the Jupyter Notebook ecosystem to grow: increased experimentation on the Cloud, support for developer workflow, and quicker turnaround from analysis to production. These forces may have brought in the development of new tools, plugins, and Notebook-like products to satisfy such gaps.
For the next part of this series, I’ll talk about how we can use Jupyter Notebooks given these forces of change. I’ll review some of the tools and workflows that have helped me in my day-to-day work and side-projects.