
How to use Jupyter Notebooks in 2020 (Part 3: Final thoughts)
This is the last of a three-part blog post on the Jupyter Notebook ecosystem. Here, I’ll share some of my reflections and wishlist to better improve the Notebook experience. You’ll find Part One in this link and Part Two here.
Hi friends! Thanks for accompanying me in the final part of this series. Let’s jump right into it!
To recap what we know so far, in Part One, we created a framework that identifies two directions of growth— cloud adoption and production systems— and three forces of change that push the Jupyter ecosystem forward (as represented by the purple arrows):
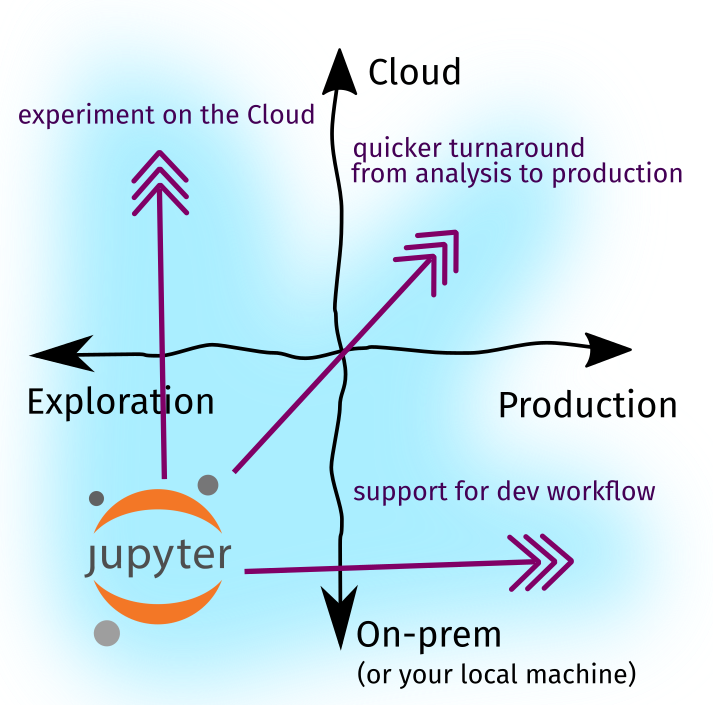
We saw that Jupyter Notebooks, by themselves, occupy the bottom-left portion of the quadrant: they work best as an exploration or prototyping tool, and we typically use them in our own laptops. However, the data science landscape in 2020 is different: (i) most of our work happens in the Cloud and (ii) there is more emphasis on writing production data systems. Given that, in Part Two, we explored various tools and extensions that helped bridge the gap:
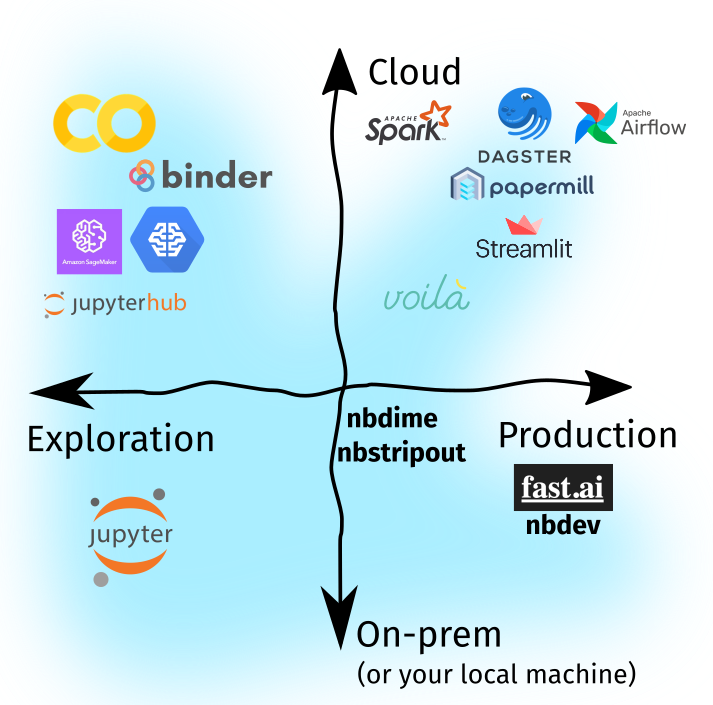
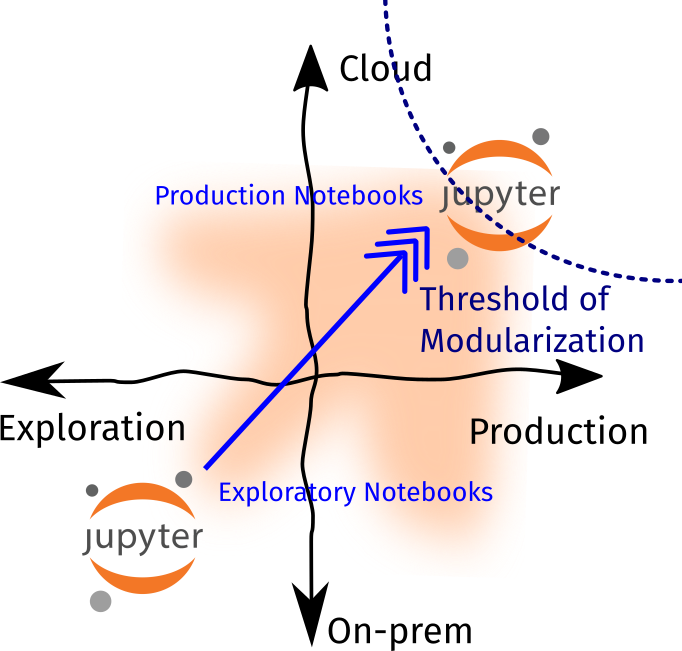
Part Two is chock-full of tactical information so I’d suggest that you read through it. It closes off by offering a strategic framework called the threshold of modularization, where it allows one to decide when to highly-optimize a software artifact:
As we close this series off, I’d like to give a short reflection on Jupyter Notebooks, a short meta-thesis on why I’m writing these blogposts, and my wishlist for the Notebook ecosystem in the future.
Conclusion
Are notebooks here to stay?
I opened up this series with the statement:
“Ah, Jupyter Notebooks. Love it or hate it, they’re here to stay.”
Given what we know and what we’ve learned so far, let’s revisit this assertion and see if it holds ground. I’d approach this in a two-fold manner: first, with Notebooks as a paradigm, and second, with Notebooks as a product (i.e., Jupyter Notebooks by Project Jupyter).
As a paradigm, it’s here to stay. The idea of interspersing text and code is not a new concept. We can see this as an offshoot of Donald Knuth’s literate programming paradigm—where instead of developing with respect to computer logic, we develop with respect to human thoughts. There have been many “products”1 built around this, like Wolfram’s Mathematica or Rlang’s RMarkdown Notebooks. I’d say that given the boom in data science, especially the practice of exploratory data analysis and open science, Notebooks as a literate programming paradigm found its home.
As a technology, Jupyter Notebooks will become an open standard. My fearless forecast is that we’ll start seeing an emergence of Notebook-type products based from Jupyter Notebooks, such as Google Colaboratory. These companies aren’t reinventing the wheel, rather, they’re adopting the Jupyter open standard to create platforms for their specific use-case— e.g., ObservableHQ for data visualization, CoCalc for online courses, and Kaggle Kernels for data science competitions. As Jupyter Notebook becomes an open standard, my only hope is that tools can still provide interoperability between them.
I believe that the future of Jupyter Notebooks is bright if done right. It combines the “perfect storm” of a well-established paradigm, and a possibility to become an open standard. In the next section, I’ll talk about some of my wishes for the Jupyter Notebook ecosystem and things it can still improve upon.
My wishlist
Just three:
- Make “Restart Kernel and Run All” (RKRA) a first-class citizen I always think of RKRA, loosely, like a compiler: first it inspects if the logic flow of your notebook checks out, and transforms it into a readable material. Whenever I hit RKRA and it “passes,” then I have a certain level of confidence that I don’t have undeclared variables, unordered rows, or unimported libraries. I hope that RKRA can be displayed more prominently in the interface.
- More Notebook IDEs The tool
nbdevseems to be a good leap forward, but I hope that there would be more players in this space. We have discussed various tools likenbstripoutandnbdime, and I hope that there’s an IDE (or an opinionated Jupyter “distribution”) that ships this right off the bat. Perhaps Jupyter Notebooks can be treated as “editors” with easily-customizable configs, and us developers can just save and share our configs like intmuxorvim. It would be fun looking at other’s configs that way! - A cell-lock mode? The ability to order cells freely is both bane and boon. On one hand, it allows me to switch context and be more flexible in how I organize my cells. On the other, it facilitates misuse and discourage software best practices. I wish that there’s a simple toggle to enable a cell-lock mode, where I’m not allowed to move cells back and forth and force me in a linear workflow.
Final thoughts
I wrote this essay because I’ve seen a lot of people reading my outdated tutorial on “Running Jupyter Notebooks in a remote server” back in 2018. I’d say it’s outdated because there are now more ways of accomplishing the same task with considerably less effort— i.e., if I were to do it again I’ll probably use Colab or SageMaker instead.
Jupyter Notebooks are great, and they don’t deserve the animosity they get. There’s always a right tool for the job, we use editors when doing this and notebooks for doing that. In addition, Notebooks eased me in when I was still learning Python and data science. They’re a useful tool, with a growing and thriving ecosystem.
I’d like to thank you, reader, for accompanying me in this journey. I hope you enjoyed your time here and learned something new. Feel free to drop a comment below if you see any inaccuracies, or if you’d just like to share your workflow! Until next time!
Other Resources
- Reddit Discussion for Part One and Part Two
- Joel Grus’ JupyterCon presentation on “I don’t like notebooks.”
- Yihui Xie’s blog post on “The First Notebook War.”
Footnotes
-
I am using the term “product” loosely here. It doesn’t have to be a paid service, it can be a libre open-source project. ↩