
Postscript: The ChristmAIs Journey
One of my first blog posts in Thinking Machines involves a deep-learning based holiday card generator dubbed as ChristmAIs. It was an exciting two-month journey of creating artworks using AI: there are things that we tried but didn’t work, reasons we pivoted, and small wins in publishing the article. This post serves as a postscript, like a “developer’s cut,” of this whimsical application.
You can view the original blogpost in this link and the open-source repository here

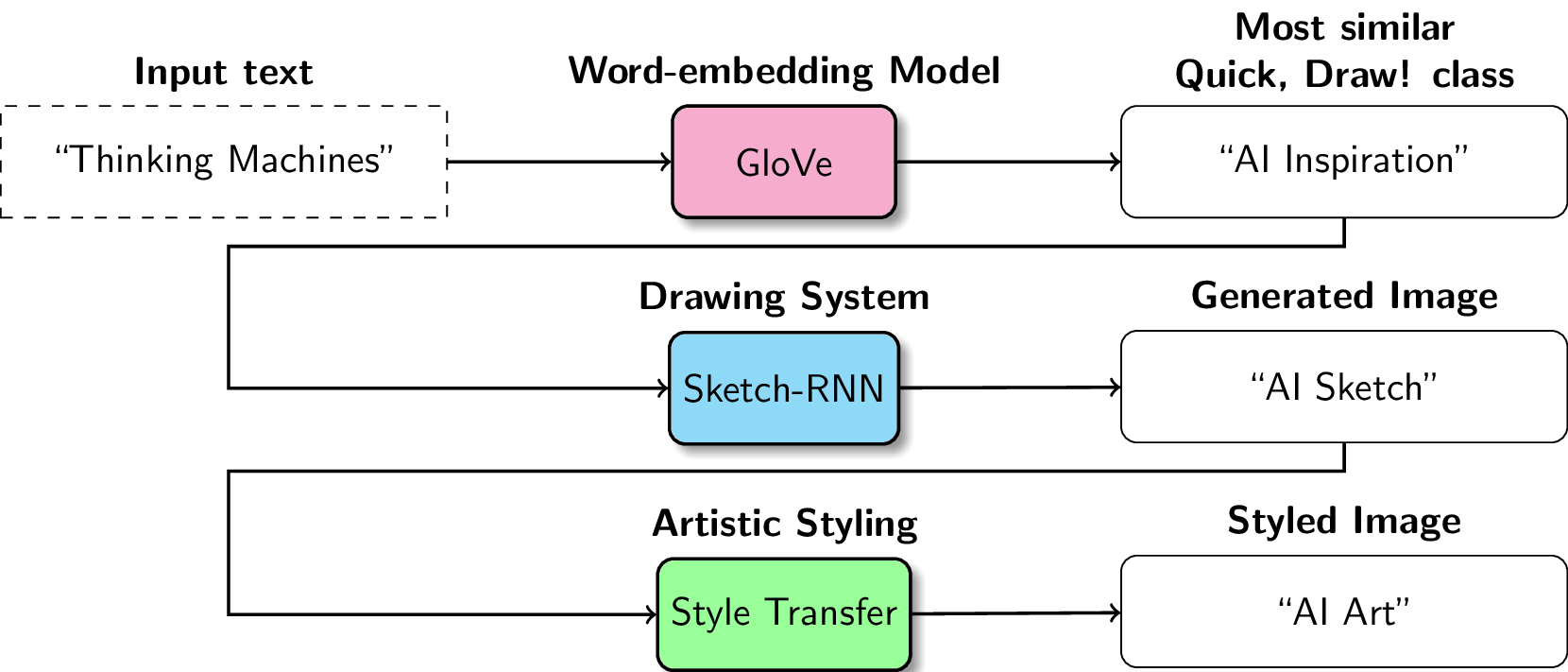
The whole pipeline can be summarized as the following:
- Take an input string and find an object representation,
- Draw the object representation; then
- Style the drawing
The most difficult part was the second step, how do you actually let an AI system draw? I’ll be spending a large chunk of the blog post on that step, then mention in passing the other two.
What didn’t work
One of the first things we tried was to replicate Tom White’s Perception Engines. The idea is to have a drawing system iteratively create abstract images based on various ImageNet classes. So by using a combination of strokes, circles, and colors as its primitives, the perception engine should be able to draw any real-world object.

They definitely look pretty, and it’s something you want to showcase to people. White provided a base set of primitives using circles and lines in his open-source repository, and we tried to use that as the drawing system. In this case, we even tried genetic algorithms to optimize the drawing (he only used random walks):
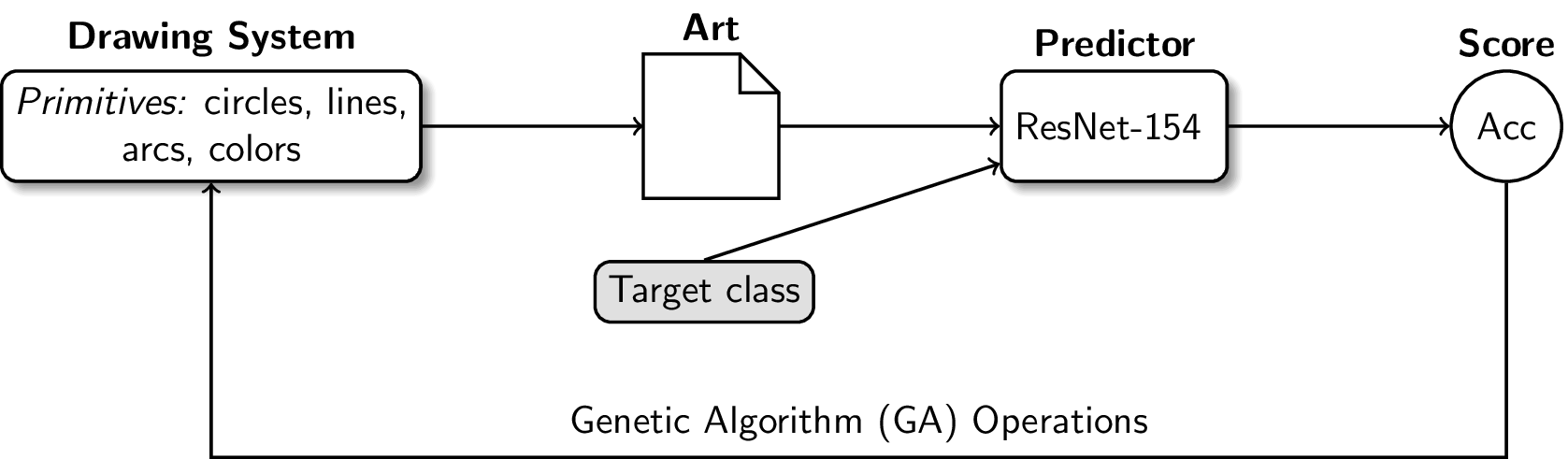
We didn’t have much luck.



Then we tried to restrict everything into dark lines by removing the circles and other colors in the background. We thought that by training the “outlines,” we can get atleast some recognizable shapes:
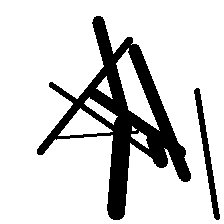
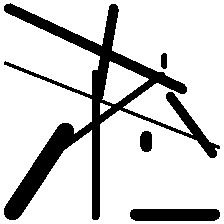

Perhaps one of the reasons why we weren’t able to replicate his work is because there’s not much information on how the whole system actually works. I guess it’s also part of his artistic license to keep their secret sauce. So yup, we decided to scrap this idea.1
What worked
Good thing, one of our engineers suggested using the Quick, Draw! dataset as primitives for our Drawing System. It’s simply a set of drawings made by real players from the game Quick, Draw!

Thus, I just need to figure out how we can generate new images from that dataset. I can use individual strokes, but building it from scratch will take a lot of time (it was almost December), so I went on and use generative models to accomplish the drawing task.
The main idea for generative models is that it first summarizes a particular class in a single distribution, then samples from it. So for a set of “book” doodles, the generative model finds the distribution that perfectly fits (or represents) all of them, then creates new drawings based on that.

The sequence-to-sequence variational autoencoder Sketch-RNN (Ha and Eck, 2017) seems perfect for the job, so I decided to incorporate that in the system.
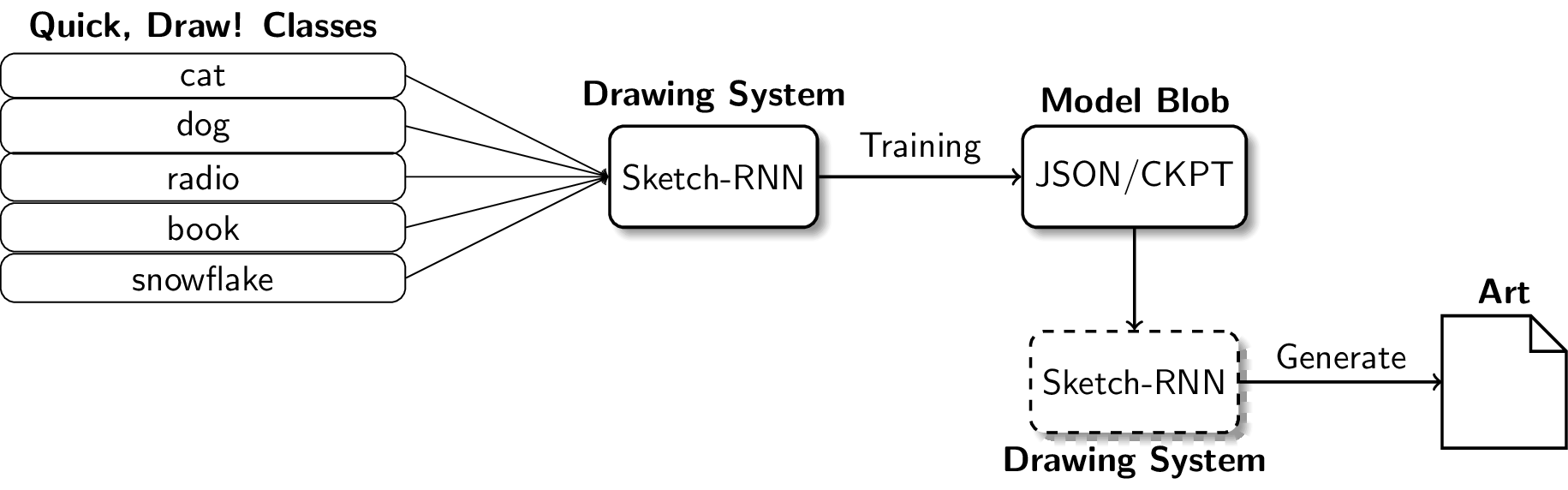
For the final pipeline, the first and last stages—the one where we convert strings to objects and the one where we need to style the object further—are more straightforward. We used the GloVe word embedding model (Pennington, et al., 2014) to map2 any input string into one of the trained Quick, Draw classes, and used Arbitrary Neural Style Transfer3 (Ghiasi, et al., 2017) to add more artistic styling to the resulting drawings.
Results
I’m pretty proud of our final product. Mainly because of my amazing and talented teammates who helped productionalize this machine learning system!
-
We built a web application where people can try entering any given text and choose the artistic style to create AI generated holiday cards! The backend uses a Google Compute Engine (GCE) instance.
-
We also printed some holiday cards and artworks that look really dope!

- We got noticed by David Ha! He’s the author of the original Sketch-RNN, and probably one of the big names in machine learning and creativity (from Google Brain). Perhaps this is one of the highlights of this project.
Happy Holidays 🎉
— hardmaru (@hardmaru) December 25, 2018
Someone made this holiday card generator using Sketch-RNN and Style Transfer:https://t.co/50dWllrga8https://t.co/Tag9IwVenP pic.twitter.com/68Q0fPL5eP
Conclusion
In this post, I shared the creative process we’ve undergone when building ChristmAIs. We started of by replicating Tom White’s work, but it didn’t produce pleasing results. Then, we pivoted on an entirely different pipeline using generative models, and it worked! So far, I’m very happy with the results: we got an open-source project, got recognized by one of Google Brain’s top research scientists, and produced an AI-generated art apt for the holiday season.
References
- Pennington, Jeffrey, Socher Richard, et al.(2014). “Glove: Global Vectors for Word Representation”. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.1532-1543.
- Ha, David and Eck Douglas(2017). “A Neural Representation of Sketch Drawings”. In: arXiv:1704.03477[cs.NE]
- Ghiasi, Golnaz et al. (2017). “Exploring the structure of real-time, arbitrary neural artistic stylization network”. In: arXiv:1705.06830[cs.CV]
-
You can even see the remnants of our exploratory replication work in the repository. Perhaps you can replicate it by yourself! ↩
-
This step simply involves getting the word vector for the query string and the Quick, Draw! classes, and computing the cosine similarity for each. ↩
-
For style transfer, we used Ghiasi’s work on “Arbitrary Image Stylization.” Unlike the work of Gatys, this technique only trains a single model for any given style image. It’s much faster and less complex. ↩