
The Filipino qualities we need to build world-class language technologies
I gave a talk at the Analytics & AI Association of the Philippines (AAP) on the topic of Philippine language model evaluation (Slides), specifically on FilBench.1 The purpose of the meetup was really to figure out (1) whether we can build a “Philippine LLM” and (2) what doing so would entail. I had some experience building open language models back in my previous work, and my research on multilinguality is directly related, so I was able to share my thoughts and experiences.
To preface: the answer to the question of “can we actually build Filipino-centric LLMs?” is definitely YES. The tools are open-source, the recipes are publicly available, and there’s definitely a lot of talent. However, the challenges are two-fold:
-
Building Filipino-centric LLMs does not entail applying Silicon Valley approaches to our local contexts. The capital difference is vast and the ecosystem is different. It’s better to look into how our neighbors (geographically and economically) are doing it, such as Malaysia or Africa.
-
Figuring out real needs is paramount to prevent the project from becoming a vanity training exercise. If the use-case can be solved by the next ChatGPT or Claude release, then maybe it’s not worth going deeper than the application layer.
Recently, there’s been a lot of talk about retaining ownership over the whole LM development pipeline, hence the proliferation of sovereign LLMs. It’s a common motivation, but I’m not yet well-versed in this topic. The point is: are we building this to fulfill a business need? To include more Philippine languages? To own the LM development stack?
So can we build Filipino-centric LLMs and contribute world-class technologies? My answer is YES, because we Filipinos have the unique qualities and values to do so.
The next step then is to provide an environment where these qualities will flourish. These qualities are: Diskarte, Sipag at Tiyaga, and Bayanihan. Let me explain them in the following sections.
We can build Filipino-centric LLMs and contribute world-class language technologies because we have the unique qualities to do so: Diskarte, Sipag at Tiyaga, and Bayanihan. The challenge then is to create an environment that allows these qualities to flourish.

The slides below are taken from the closing remarks of my talk (about 75% of the talk is about FilBench), but the text doesn’t map to them one-to-one. Just think of this blog post as an extended version of those closing slides.
Diskarte - achieving a goal under extreme constraints
After World War 2, several US Army Willys MB Trucks were left in the Philippines as American troops left the country. There was a shortage of public transportation due to the destruction of infrastructure, and so, we began stripping down these trucks and altering them to add metal roofs, and various paintings and ornaments. This later on became the jeepney or jeep, which is now our cultural icon and the current mode of transportation today.2 Diskarte is difficult to translate into English because it can mean many things: resourcefulness, ingenuity, creative thinking, etc. There is this nice paper that talks about this at length, and I encourage anyone to read it. Personally, I see diskarte as the ability to achieve a goal under extreme constraints.

The best way to innovate is similar to how we approached the jeepney: taking these innovations from the Global North and adapting them to our local contexts through ingenuity and resourcefulness.
I argue that the best way to innovate is similar to how we approached the jeepney: taking these innovations from the Global North and adapting them to our local contexts through ingenuity and resourcefulness. Simply importing Silicon Valley approaches is not enough. I wrote about this at length in a recent survey paper (Miranda et al., 2026), but one approach I’m currently exploring is careful synthetic data generation to address the lack of training data. Synthetic data is now a common approach in training frontier language models, but I believe we can strip it down and, similar to the jeepney, add some ornaments / adjustments to make it work for low-resource languages. I encourage you to read the survey paper, as I mention potential paths for improvement such as creating task-specific small language models, deploying models at the edge, and improving a model’s capabilities through a robust set of harnesses.
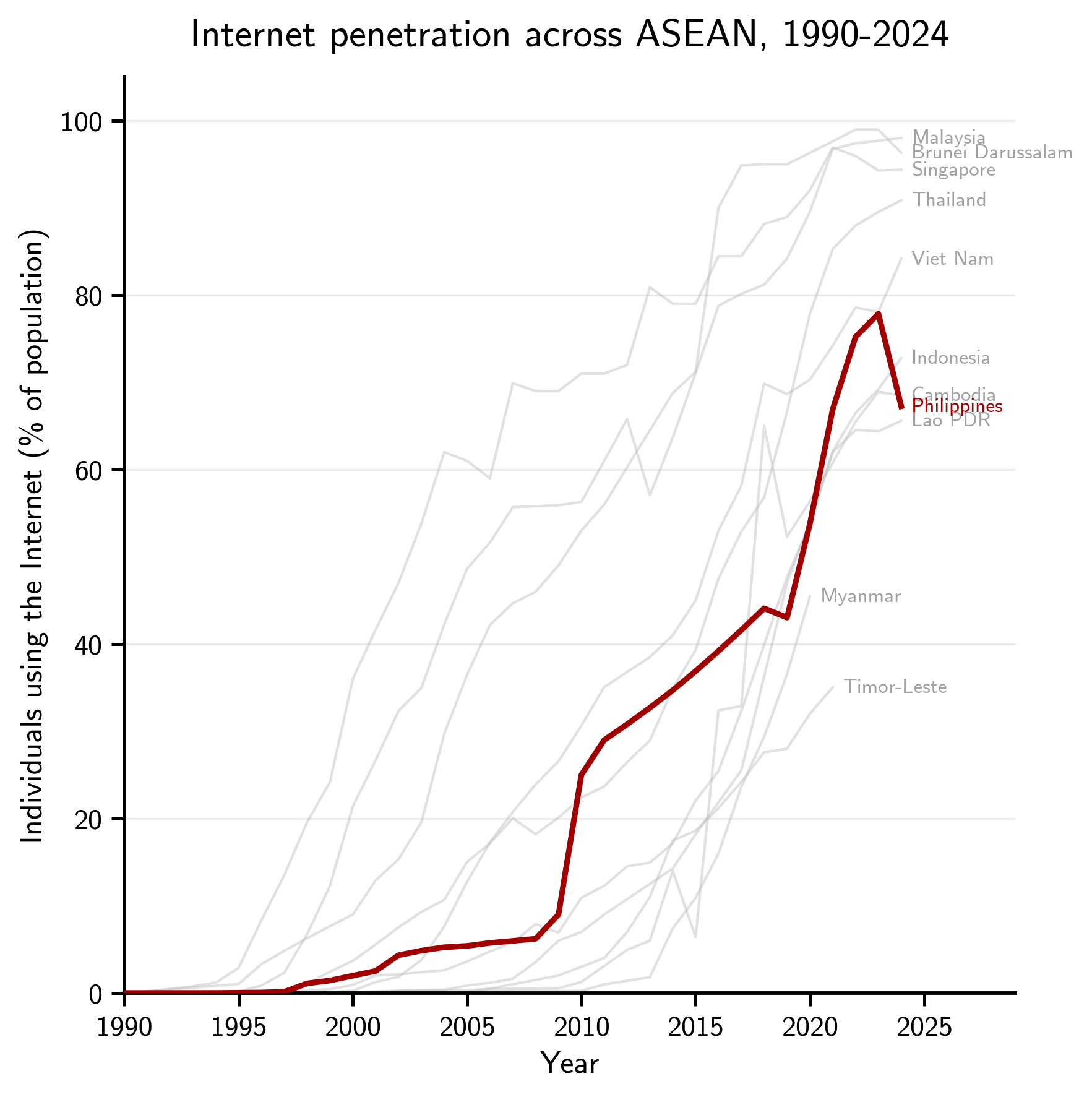
That said, the Philippine NLP landscape is constrained in terms of both data and compute. Although there is a significant presence of Filipino speakers and the language is well-represented on the internet, few have transformed this resource into useful, high-quality datasets. This situation is even more pronounced for other Philippine languages. In addition, our compute situation (for both development and deployment) leaves a lot to be desired. We lack the compute infrastructure to train LLMs (Epoch AI Data on GPU Clusters, 2026), and our internet and technology penetration lags behind that of our ASEAN neighbors (ITU Data based on the World Bank).
Sipag at Tiyaga - supporting sustained effort through time
There is a famous saying: “Pag may tiyaga, may nilaga.” Perhaps the nearest English translation I can do is: “If the patience is true, you’ll get a stew.”3 I’d argue that most components of a language modeling recipe (especially in multilingual post-training) are more a test of patience than flashes of insight: collecting enough data through large-scale annotation or synthesis, figuring out the right data mix across many ablations, and ensuring the evals faithfully reflect the capabilities we care about. How, then, can we support these types of activities?

Most components of a language modeling recipe (especially in multilingual post-training) are more a test of patience than flashes of insight.
On the brighter side, I feel quite optimistic about some of the teams scattered across government and academia. For example, E-CAIR has built task-specific systems, and I’ve seen some of their members publishing in *CL and ICML! I also met some folks from AIM last year in Vienna at ACL, so there’s good investment happening there too. And I’ve chatted with a few undergraduate thesis groups in UST and PUP (and I still get the occasional e-mail about calamanCy), so there’s clearly a loose network of groups working on the fringes. What I’m trying to say is that there is talent here willing to do the hard parts—it’s just a matter of getting these efforts more coordinated and aligned.
I’d like to propose two dimensions on how to support these activities: infrastructure and incentives. Infrastructure here can take two forms: compute grants that give people room to experiment, and governance structures with a central decision-maker to keep efforts coordinated. The first one is quite self-explanatory. But I think the second one is much more important.
For example, it is quite difficult to find what is the canonical National AI strategy for the Philippines. The OECD AI Policy Navigator and UNESCO points to NAISR v2 which is from DTI, but the website says it was superseded by another Philippine AI Strategy Roadmap by DOST. Now, the only DOST-related roadmap I can find is this slide deck, but that can’t be it, right?
Bayanihan - collective action to achieve a goal
I always find the imagery of bayanihan inspiring. It’s now uncommon today due to most houses being made of concrete, but the spirit of bayanihan still lives: I remember back in high school when we had Brigada Eskwela and gathered together (my classmates, teachers, and even parents) to clean classrooms, or even the disaster relief packages we assembled for victims of typhoon Yolanda back in college. I’d like to think that this is possible in the context of LLM development.

For such a network to work, it has to be focused on a single objective, much like the imagery of bayanihan where the only goal is to move a house from one place to another.
I wrote about this last year, and I still believe in the capability of grassroots networks. We attempted to build a small research network earlier this year, and while it has been a slow start with a few hiccups along the way, I feel optimistic about what we can achieve next.
However, for such a network to work, it has to be focused on a single objective, much like the imagery of bayanihan where the only goal is to move a house from one place to another. The challenge with loose networks is that everyone has their own priorities and interests, so the effort diffuses. Again, I want to stress that focusing on a single, measurable objective is important. In my opinion, the project should be well-scoped, short-term, and designed so that nodes can pitch in and make drive-by contributions whenever they want. I still have a lot to learn about managing these types of networks, so if you’ve done this before and would like to chat, please reach out!
If grassroots networks are to be multi-sectoral, there has to be a way to align diverse and often conflicting incentives. In academia, for example, there is pressure to secure grants and publications (which, in computer science, means publishing in top conferences and journals). Industry, on the other hand, tends to prefer engineering-heavy, context-specific deployments. As a PhD student, I find that Industry Tracks in conferences are a good avenue for these partnerships: the student gets to work on a concrete project and can even write a paper about it. Finally, the involvement across sectors doesn’t have to be deep on all sides. It could be a donor-recipient setup where, for example, the government provides the problem statement, industry provides the resources, and academia provides the scientific rigor to achieve the goal.
Final thoughts and reflections
If we want to build Filipino-centric language models, we need to build them our way. This entails adapting innovations from other parts of the world to our local contexts and constraints rather than simply importing them (diskarte), creating governance and incentive structures that support long-horizon, experimental work (sipag at tiyaga), and building grassroots networks around a shared, well-scoped goal (bayanihan).
To make this concrete: a good goal would be to train Filipino-centric LMs that cover the country’s major languages (Tagalog, Cebuano, Ilokano, Hiligaynon, Bikol, Kapampangan). The most reasonable approach is to post-train on a strong multilingual base model, then evaluate on a new version of FilBench where all these languages are well-represented. The first major constraint is data, so we need to source it through scraping, native-speaker annotation, or synthetic data generation (diskarte). The second is compute and funding, which calls for partnerships with industry or organizations willing to underwrite them (bayanihan). Finally, much of this work demands sustained experimentation, data ablations, and people willing to see it through (sipag at tiyaga).
As I’ve said, the tools and recipes are publicly available, and I truly believe we have the qualities to make it work. The ball simply needs to get rolling.
References
- Lester James Validad Miranda, Elyanah Aco, Conner G. Manuel, Jan Christian Blaise Cruz, and Joseph Marvin Imperial. 2025. FilBench: Can LLMs Understand and Generate Filipino? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2496–2529, Suzhou, China. Association for Computational Linguistics.
- Lester James V. Miranda, Songbo Hu, Roi Reichart, and Anna Korhonen. 2026. Multilinguality at the Edge: Developing Language Models for the Global South. Preprint, arXiv:2604.21637.
-
I won’t be talking a lot about FilBench in this blog post. But if you’re curious, check out my blog post, check the leaderboard, or read the paper (Miranda et al., 2025)! ↩
-
I really like the imagery of the jeepney to symbolize diskarte because my dad used to own and drive one, and I learned how to read by reading handpainted jeepney signs. ↩
-
The idea of course is that making a stew requires long cooking time where tough cuts of meat require hours of slow simmering to become tender. ↩