'Draw me a swordsman': Can tool-calling LLMs draw pixel art?
Recently, we’ve witnessed language models become increasingly adept at using real-world tools through their function-calling capabilities. Whenever I develop games, I use Aseprite to create pixel art characters and environments. Aseprite is powerful: I can prepare spritesheets, test color palettes, and preview animations—it’s not something any AI image generator can simply replace. So I wondered: could I incorporate LLMs into my workflow?
In this blog post, I tested LLMs with tool-calling capabilities on the following tasks:
- Task 1: Draw a swordsman: an easy task that generates a static image.
Draw me a pixel art of a swordsman.
- Task 2: Draw a swordsman performing a slashing sequence: a harder task.
Draw a 4-frame spritesheet showing a swordsman performing a sword slash attack sequence, with each frame capturing a different stage of the slashing motion from windup to follow-through.
The characters in Task 1 and Task 2 don’t have to be the same. Task 2 is particularly interesting because creating sprite sheets is a common use-case in game development. It’s also challenging for LLMs since it requires sequential understanding: each frame must logically follow the previous one to create believable animation. Unlike generating a single image, sprite sheets demand consistency in character design, progression, and timing.
Here’s a human baseline from a game I made a few years ago:
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
 |
I evaluated each LLM’s output using two criteria, each scored from 0 to 3:
- Correctness: Did the LLM follow the instructions accurately?
- Creativity: How original or artistic was the LLM’s approach?
To get a single representative score, I compute the average of correctness and creativity for each task, then average those two task scores together—a benchmark I’ll now dub as SwordsBench score!
You can find the full code on GitHub
Setting up the Agent-Environment Interaction
This project also helped me understand the development workflow for MCPs and LLM agents. I like framing this setup similar to reinforcement learning: we instruct an Agent (an LLM) to interact with the Environment (standardized via MCP) to accomplish a task, as shown in the diagram below:

In the tool-calling paradigm, we instruct an Agent to interact with the Environment in order to accomplish a task. The Agent can be implemented via the OpenAI Agents SDK or natively in Claude Desktop, while the Environment is an MCP server that calls Aseprite commands.
MCP Server Environment
The Environment receives commands from the Agent, executes them, and provides feedback that the agent can use for its next action. Recently, Anthropic released the Model Context Protocol (MCP), which provides a common interface for how agents can interact with any given environment. I think of MCP as a standardized set of affordances for the Agent.
For this project, I used the Aseprite MCP implementation from divii/aseprite-mcp with some slight modifications and bug fixes. The Aseprite MCP server exposes the following tools:
| Tool Name | Description |
|---|---|
| create_canvas | Create a new Aseprite canvas with specific dimensions |
| add_layer | Add a new layer to an existing Aseprite file with a specified layer name |
| add_frame | Add a new frame to an existing Aseprite file for animation purposes |
| draw_pixels | Draw individual pixels on the canvas with coordinates and hex colors |
| draw_line | Draw a line between two points with customizable color and thickness |
| draw_rectangle | Draw a rectangle with specified position, dimensions, color, and fill |
| fill_area | Fill an area with color using a paint bucket tool from a starting coordinate |
| draw_circle | Draw a circle with specified center point, radius, color, and optional fill |
| export_sprite | Export the Aseprite file to other formats like PNG, GIF, JPG, etc. |
| preview_image | Read and display an image file as base64 data for preview purposes |
Under the hood, these tools are Lua commands that are sent to the aseprite executable.
For example, the draw_pixels tool call is simply a series of img:putPixel commands for drawing pixels:
@mcp.tool()
async def draw_pixels(filename: Path, pixels: list[dict[str, Any]]) -> str:
...
for pixel in pixels:
x, y = pixel.get("x", 0), pixel.get("y", 0)
color = pixel.get("color", "#000000")
# Convert hex to RGB
color = color.lstrip("#")
r, g, b = int(color[0:2], 16), int(color[2:4], 16), int(color[4:6], 16)
script += f"""
img:putPixel({x}, {y}, Color({r}, {g}, {b}, 255))
"""
# Submit the script to Aseprite
execute_lua_command(script)
...
Then, the function execute_lua_command calls the aseprite executable and passes the Lua script to the --script argument.
You can find the full implementation of the Aseprite MCP server in this repository.
Large Language Model Agent
The Agent has access to tools that interact with the execution environment to accomplish a task. We use language models like GPT-4.1 or Claude Sonnet 4—some of which were trained for tool-use—as agents. Models with tool-use capabilities can output function calls based on the tools in their system prompt. These function calls are parsed by an intermediary layer (such as an MCP server) and passed to the execution environment.
I used the OpenAI Agents SDK to build the Aseprite agent.
The implementation is quite straightforward: I just need to create an instance of an Agent class and let it interact with the execution environment (mcp_servers=[server]).
For open-weight models, I host them as an OpenAI-compatible vLLM server and pass the server URL to a LiteLLM proxy when instantiating the Agent class.
async with mcp_server as server:
with trace(workflow_name=workflow_name):
model = get_model(model_name)
agent = Agent(
name="Assistant",
instructions=system_prompt,
model=model,
mcp_servers=[server],
)
result = await Runner.run(
starting_agent=agent,
input=request,
)
When an Agent is instantiated, it contains information about the model it’s using, its system_prompt, and the mcp_servers it’s connected to.
I experimented with different system prompts—the one below gave me the best results:
You are a creative and artistic function-calling agent that can use pixel art tools to perform a drawing task. You have a good knowledge of color, form, and movement. Your output must always be saved as an image file in the PNG format. If you encounter an error, find a way to resolve it using other available tools.
To initiate an interaction between the Agent and the MCP server, we simply pass the agent to a Runner class with our actual request as input.
Results
Below are the results of several models on the simple swordsman and spritesheet tasks. The figures below show the best of three agent-environment interactions, selected based on correctness and creativity criteria.
Qwen 3 32B (SwordsBench: 0.25)
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
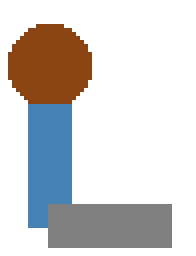 |
Qwen3 performed poorly on both tasks. I can see the attempt to draw a swordsman in Task 1: the brown circle is the head, the cyan rectangle is the body, and the grey rectangle is the sword. However, the Task 2 drawing is poor and doesn’t produce anything recognizable. I actually ran Qwen 3 with both reasoning turned on and off. Generally, using tools with reasoning resulted in better-looking figures, though it took much longer to complete.
Funny enough, when I read the reasoning trajectories, it seems that Qwen 3 likes blaming the tools.
It will say something akin to: “the draw_line tool doesn’t work, so I have no way to perform this task” (it actually works).
I’m sorry Qwen, but this is a skill issue (minus points for the attitude too).
Task 1 - Creativity (0/3), Correctness (1/3)
Task 2 - Creativity (0/3), Correctness (0/3)
GPT-4o (SwordsBench: 0.75)
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
 |
GPT-4o’s intent is clearer than Qwen3’s output. The Task 1 drawing can definitely be a swordsman if I squint hard enough. There’s a recognizable sword shape, but the body is either missing or unclear. The Task 2 spritesheet shows promise: there’s clear movement from one sprite to another, and the blue “swordsman” maintains consistency across frames. However, it seems like GPT-4o has taken a lot of creative liberties in designing the swordsman, as the blue blob is hard to identify by itself. This is a good and earnest try.
Task 1 - Creativity (1/3), Correctness (1/3)
Task 2 - Creativity (0/3), Correctness (1/3)
GPT-4.1 (SwordsBench: 1.25)
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
 |
GPT-4.1 shows a marked improvement over GPT-4o. The Task 1 swordsman is much more recognizable—there’s a clear humanoid figure with distinct head, body, and limbs, but no well-defined sword. The proportions are reasonable and it actually looks like a character you might find in a classic pixel art game. For Task 2, while the character design remains consistent across frames, the animation sequence doesn’t quite work. The “sword” ends up looking more like a gun being held horizontally, and there’s no clear slashing motion or arc. It’s a decent attempt at maintaining character consistency, but fails to capture the essence of a sword attack.
Task 1 - Creativity (2/3), Correctness (1/3)
Task 2 - Creativity (1/3), Correctness (1/3)
Claude Sonnet 4 (SwordsBench: 2.0)
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
 |
Claude Sonnet 4 is getting there but isn’t quite the most polished. The Task 1 swordsman does look like a proper pixel art character—you can make out the basic humanoid form and it has that classic retro game aesthetic. It’s recognizable as a swordsman even if the details aren’t super crisp.
Task 2 is where things get weird: while there’s definitely a slash motion happening across the frames, the character completely loses all sense of body proportions. The figure becomes distorted and inconsistent, though you can still trace the sword movement from windup to strike. It’s like the model understood the motion but forgot about maintaining the character’s form.
Task 1 - Creativity (2/3), Correctness (3/3)
Task 2 - Creativity (1/3), Correctness (2/3)
Claude Opus 4 (SwordsBench: 2.5)
| Task 1: Swordsman | Task 2: Draw a 4-frame spritesheet of a sword slash attack |
|---|---|
 |
Claude Opus 4 produces solid results across both tasks. The Task 1 swordsman shows good creativity with a distinctive character design—clear head, body, and sword, though the sword shape could be more refined. What’s particularly interesting is that Opus seems to have developed a consistent character concept: even across different prompts, it drew essentially the same swordsman design.
Task 2 delivers a proper slash sequence where you can follow the sword’s motion from windup to strike, and the character maintains its form throughout the animation. It’s a competent spritesheet that demonstrates understanding of both animation principles and character consistency.
Task 1 - Creativity (3/3), Correctness (2/3)
Task 2 - Creativity (2/3), Correctness (3/3)
Discussion
Recently, I’ve been conducting research on endowing models with tool-use capabilities. I’ve been deep in the modeling side, so it’s interesting to see and address some knowledge gaps from a developer’s perspective. Here are some of my learnings:
Models are constrained by the tools available to them
“Give me a lever long enough and a fulcrum on which to place it, and I shall move the world.”
The Aseprite MCP server exposes basic primitives—from drawing a single pixel to basic shapes. In reality, pixel artists use many other Aseprite features: color pickers, multiple onion frames for animations, and more. This might explain why the resulting artworks look blocky and basic compared to human-created art.
From a developer’s perspective, choosing which tools to expose and their granularity (e.g., drawing pixels → drawing shapes) is crucial for MCP server design. Most models work within the constraints of provided tools, so determining which tools to build gives you the right leverage from a “very-smart-assistant.” From a researcher’s perspective, it would be interesting to endow models with the capability to create their own tools or assess tool quality. I’ve seen this in Claude Code, where it writes Python scripts to perform complex tasks. There are many long-horizon tasks that make this area exciting!
Not all tasks or use-cases require a tool-calling LLM
When I started this project, I was excited about having a language model interact with a program I’ve been using. Now I realize that drawing pixel art might not be the best use-case for a tool-calling LLM. Creating an MCP server requires significant time investment—I could have just drawn inspiration from an image generation model or Pinterest and created the swordsman myself. Better Aseprite MCP use-cases might include asking an AI assistant to export drawings into Godot-compatible spritesheets, recolor artwork with different palettes, or correct pixel dimensions for isometric art. There are many possibilities for augmenting human workflows with tool-use LLMs.
From a researcher’s perspective, it’s worth assessing whether domains and use-cases in famous benchmarks like BFCL truly reflect how tool-calling LLMs are used.
Many of these were scraped from GitHub or API repositories, but these APIs’ affordances differ greatly from actual tool usage.
For example, the draw_pixel function from my MCP server might be a valid test case, but it doesn’t reflect the complexity and sequential nature of real tool-calling tasks.
Perhaps this explains why Claude Code has worked so well and gained traction in the developer community.
Instead of going broad, it went deep into a particular use-case—software development—and optimized for that.1
Final thoughts
In this blog post, I learned about developer tooling for agents by having function-calling LLMs interact with Aseprite. The results were mixed: Claude Opus 4 generated the most creative pixel art while following instructions. I was surprised that models like GPT-4 weren’t very creative. This exercise revealed interesting avenues for future work. I’m curious about endowing LLMs with the capability to create their own tools when necessary. I’m also interested in evaluation, especially for complex and domain-specific tasks. Finally, I’m starting to understand why MCP—or a general protocol for LLM interaction—is important. Writing an MCP server feels more convenient than building REST endpoints. It’s still early, but I hope MCP becomes more prevalent in the future.
-
Maybe instead of focusing on a domain (e.g. coding, general chat, graphic design) when developing and evaluating models, we focus on a certain profession or occupation (i.e., software developer, executive assistant, designer). ↩