Guest lecture @ DLSU Manila: Artisanal Filipino NLP Resources in the time of Large Language Models
I was invited to give a talk to a graduate-level NLP class about my work on Filipino resources. It was fun preparing and giving that talk because I was able to synthesize my thoughts and look back on my previous research. This blog post is my lecture in text format. You can find the slides in this link (and here’s the video). Finally, thank you to Dr. Charibeth Cheng for the invitation!
Given all the rage in LLMs today, is it still worth it to build artisanal Filipino NLP resources? Hopefully we can answer this question in the context of the work that I’ve done. I’ve worked on large models in the 7B-70B parameter range, but I’ve also done several things for low-resource languages and built models in the ~100M parameter range. Tonight, I want to juxtapose these two sides and call one as artisanal and the other as large-scale.
What is artisanal NLP?
In this talk, I want to contrast two types of ideas when building language technologies. You have artisanal on one end, as shown by this photo of a handmade pottery—carefully constructed by its creator. On the other hand, you have these “mass-produced” objects done in large-scale. I want to differentiate them in terms of three dimensions.

-
Effort: artisanal NLP resources often require specialized knowledge and effort. For example, it is important to know something about Filipino grammar and morphology when building task-specific models for Filipino. Large-scale models can get away with just providing large amounts of data (as we see in most web-scale datasets).
-
Size: currently, our definitions of what’s small or large change every month. But in general, artisanal models are relatively smaller in terms of parameter size. Large-scale models need to be bigger because they have to accommodate more tasks and domains.
-
Utility: artisanal models and datasets tend to be bespoke, i.e., built for a specific task or requirement. On the other hand, most large-scale models we see today were made for general-purpose applications.
Notice that I’m a bit vague whether I’m talking about models or datasets. I like to think of artisanal vs. large-scale as an attitude for building language technologies or NLP artifacts. Finally, this talk is not about one being better than the other. However, I want to focus more on the merits of these artisanal NLP resources by discussing parts of my research and my work.
You can see the outline of my lecture below. For the rest of this talk, I’ll fill the blanks and talk about the merits of artisanal NLP while discussing portions of my research.

Artisanal NLP resources are high-effort, but impactful for the language community
In this section, I want to talk about TLUnified-NER (link to SEALP ‘23 paper), a Named-Entity Recognition dataset that I’ve built. NER is a classical NLP problem: given a text, you want to look for named-entities such as names of persons, locations, or organizations.

This is already an easy task for English NER. However, NER resources for Tagalog are still lacking. We don’t have a lot of labeled data, and in consequence we don’t have a lot of models. There are many ways to get around this problem (e.g., cross-lingual transfer learning, zero-shot from an LLM), but we still lack reliable test sets for evaluation.

In my opinion, a good NER dataset should be open-access, high-quality, and standardized. Most of the NER datasets available for us only fills two of these three attributes: WikiANN has general-purpose tags that follow CoNLL and can be downloaded from HuggingFace, but the quality of annotations are pretty bad. LORELEI is a high-quality dataset, but has strict license restrictions and quite expensive! Finally, we have several hand-annotated datasets for Filipino, but most of them were made for highly-specific tasks. Back in 2022, there’s an obvious gap to fill for Tagalog NER.
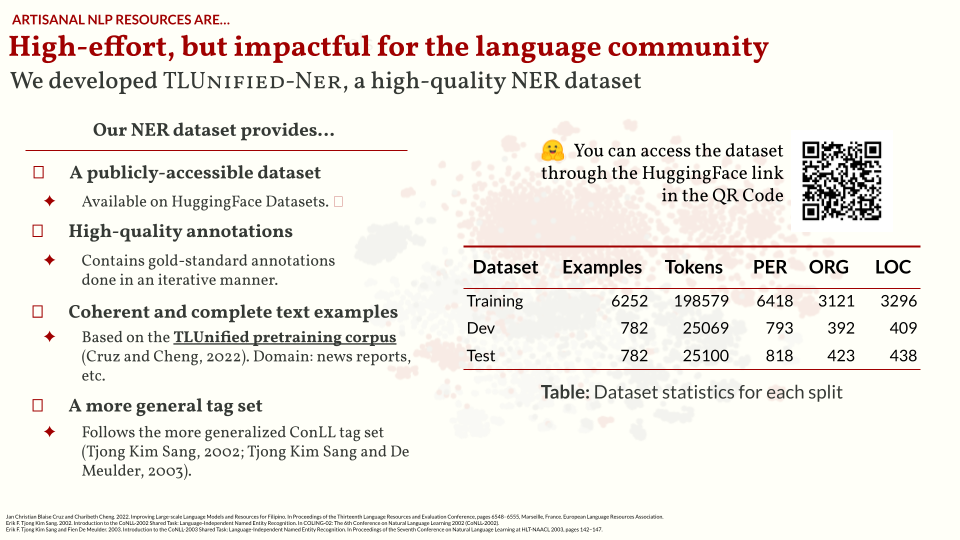
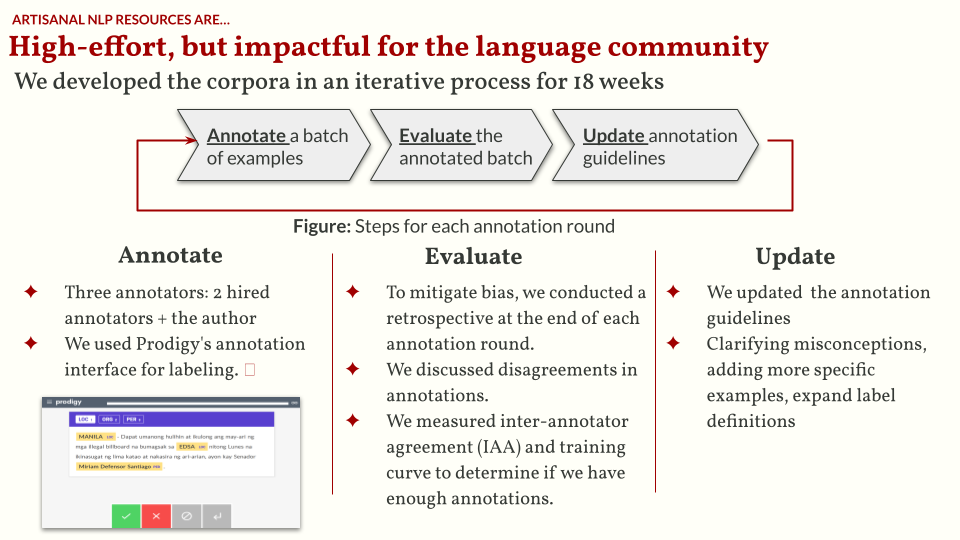
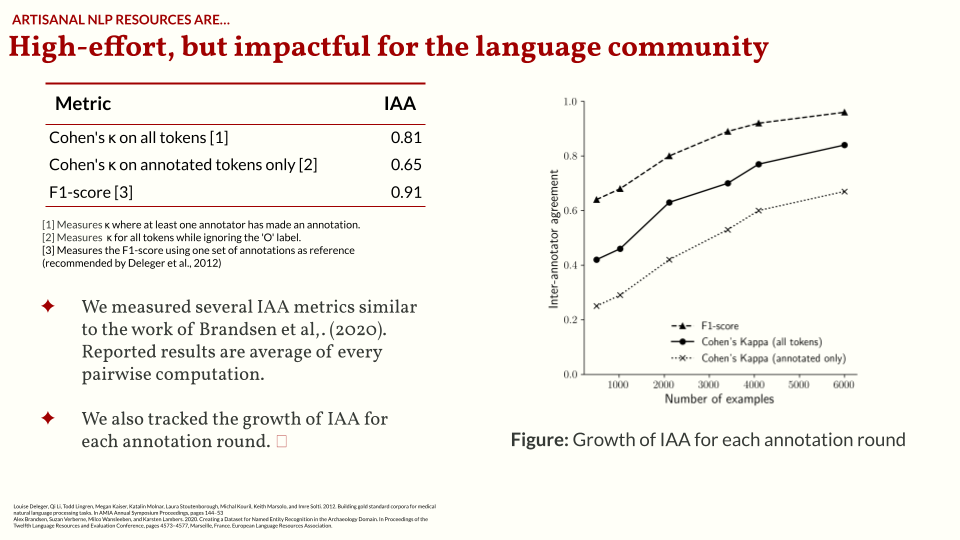

And so we built TLUnified-NER. It is publicly accessible, high-quality, and follows the CoNLL standard. I also curated the texts to ensure that it represents how we commonly write Tagalog. The annotation process is done through several rounds (or sprints). I hired two more annotators and then for each round we annotate a batch of examples, evaluate the annotated batch, and update the annotation guidelines to improve quality. You can learn more about this process in our paper. I also wrote some of my thoughts on the annotation process in a blogpost.
After building the dataset, there are two questions that I want to answer: first, is the NER task learnable from our annotations? Then, is it better than existing NER datasets? For the first one, I created baseline approaches using various mixes of word embeddings and language coverage. For all cases, we achieved decent performance. Then for the second question, we compared a model trained on WikiANN and a model trained from TLUnified-NER. In most cases, our model outperforms the WikiANN model, showing that it’s a better dataset to train models upon.

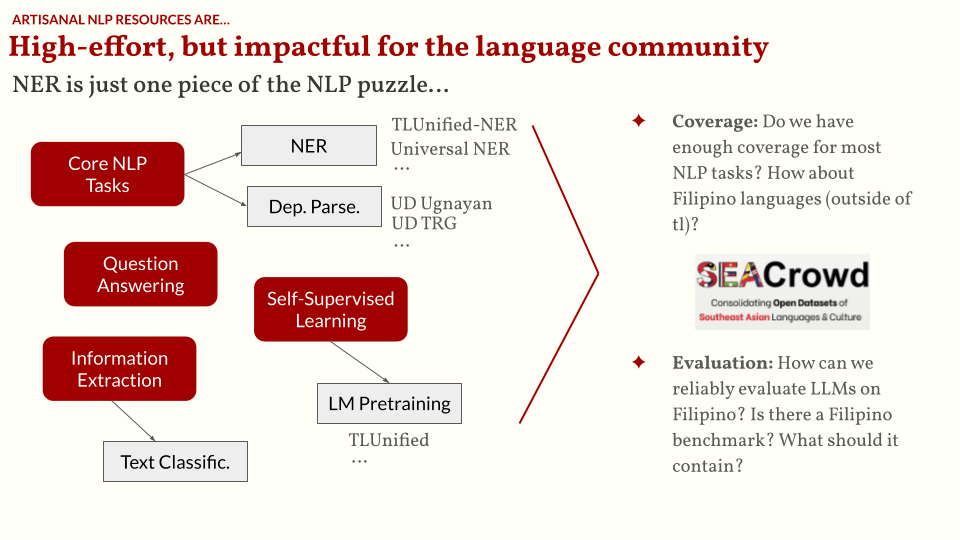
To end this part of the talk, I want to show that NER is just one piece of the NLP puzzle. There are still a lot of tasks to build resources on. I believe that increasing the coverage of Filipino resources allows us to not only train models, but create comprehensive evaluation benchmarks for existing LLMs today. Recently, we’ve seen a lot of claims that LLMs can “speak” Filipino, but most of these are cherry-picked examples and highly vibes-based. If we can create a systematic benchmark that allows us to confidently claim performance, then that would be a big contribution to the field.
Artisanal NLP resources are capable of doing a few things, but can do them well
In this section, I’ll talk about calamanCy, a spaCy-based toolkit that I built for Tagalog (NLP-OSS ‘23 paper). As you already know, spaCy is a toolkit for core linguistic tasks such as dependency parsing, tokenization, and NER. However, most of the models we provide in-house are focused on high-resource languages.
What most people do is they finetune spaCy pipelines on their own language or domain. So you’ll see libraries in the spaCy universe for all kinds of applications.
| Domain | Example libraries |
|---|---|
| Multilinguality | DaCy for Danish and HuSpaCy for Hungarian. |
| Scientific texts | scispaCy, and medspaCy for scientific and medical texts. |
| Old Languages | latinCy for Latin, greCy for Greek, and my work on SIGTYP ‘24 on several Ancient & Medieval languages. |
So this prompted me the question: why don’t we build a spaCy pipeline for Tagalog?

But what does it mean to build spaCy pipeline?
First, think of a spaCy pipeline as a series of functions that identifies key linguistic features in a text.
So a tokenizer is a function that looks for tokens, a tagger is a function for parts-of-speech (POS) tags, and so on.
Then at the end, you obtain a Doc object that contains all these linguistic features.
Building a spaCy pipeline means training these functions and composing them into a single package. In fact, we have a well-documented master thread on how to add pretrained language support for spaCy. Most of these functions are based on neural network architectures, and hence require some non-trivial amount of data to train.
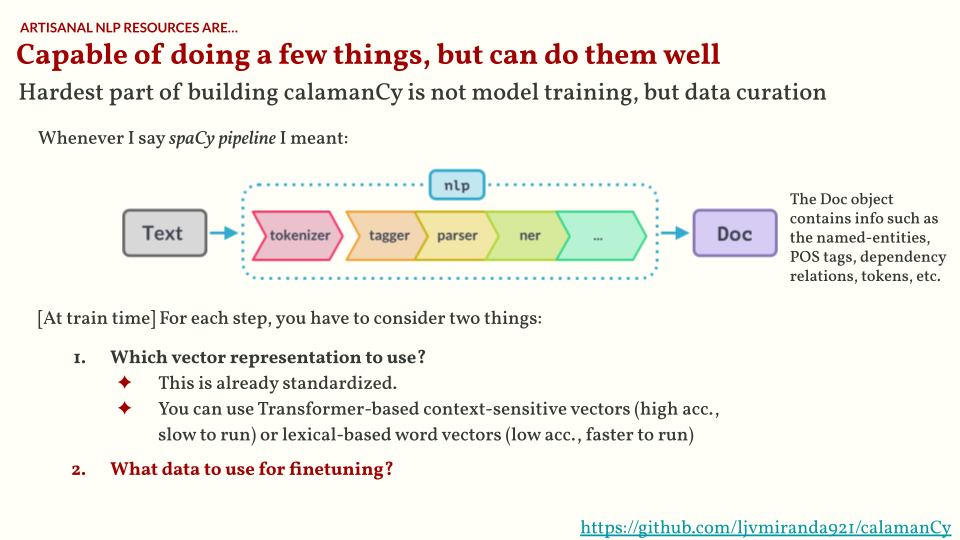
One of the hardest parts of building calamanCy is curating datasets to “train” these functions. For example, the current Tagalog treebanks are too small to train a reliable dependency parser and POS tagger. Also, TLUnified-NER doesn’t exist back then, so I still have to build it. You can read more about this curation process in the calamanCy paper.
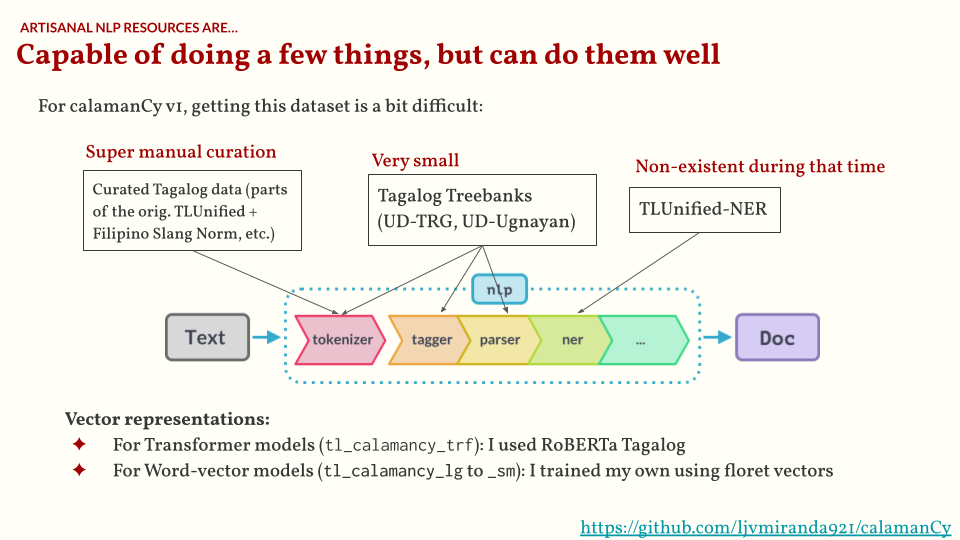
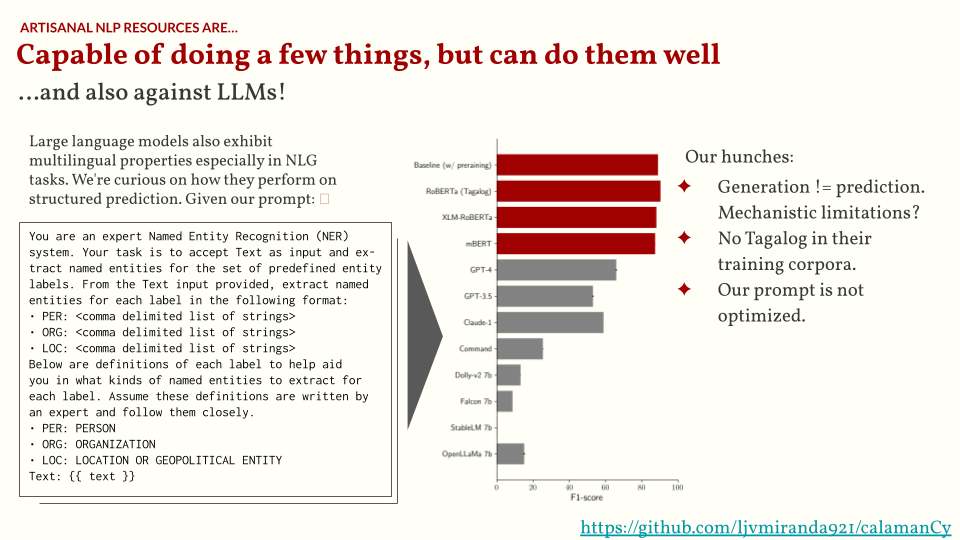
It was a long process, but the most important question is: was it worth it? To that I remember this figure from Matthew Honnibal’s blog post on LLM maximalism. I think there is value in curating these datasets and training these models as it helps me understand which parts of the linguistic pipeline really requires an LLM, and which could be done more reliably by a simple approach. In addition, we were also able to show empirically that models trained on calamanCy performs pretty well, even compared to commercial LLM APIs.

As shown in the charts below, we found that even commercial LLMs like GPT-4 and Claude don’t fare well on our test set in a zero-shot setting. There are many possible reasons, of course. One major reason is that these models aren’t optimized for multilinguality, and hence have a tiny amount of Tagalog texts in their corpora. I’d love to revisit this experiment soon, especially with the release of multilingual LLMs such as SeaLLM, Sea-LION, and Aya-101.
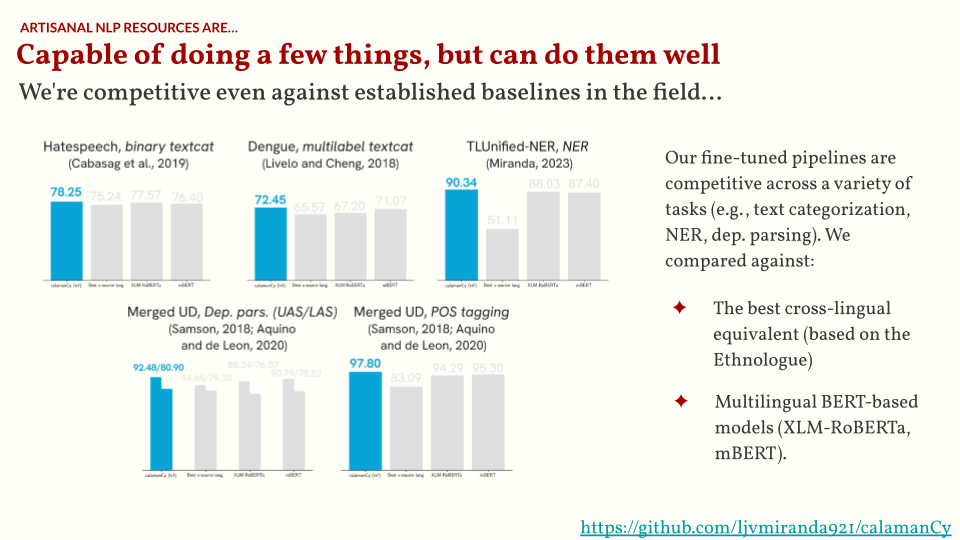
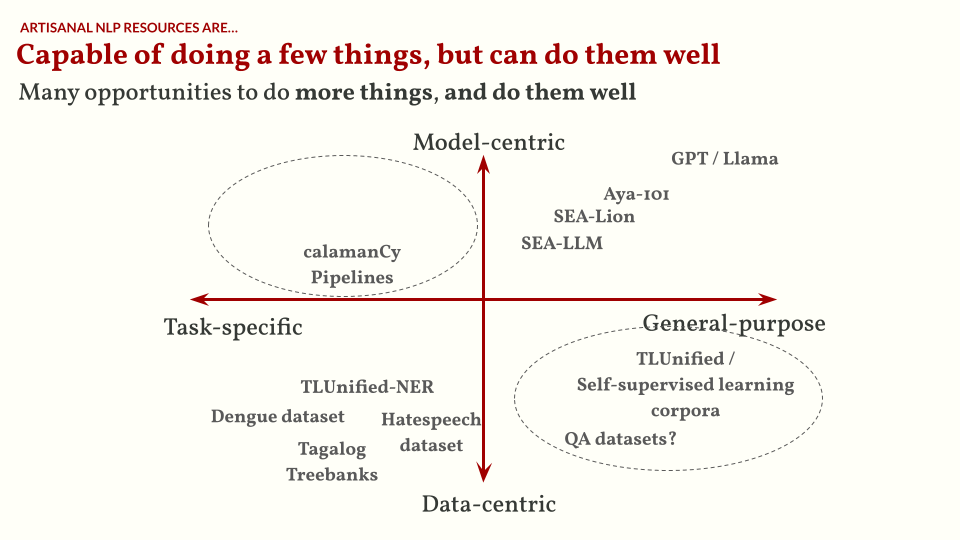
So…even if artisanal NLP models can do a few things (but do them well), I’m still optimistic that there are opportunities to do more things while doing them well. I want you to remember this chart below. There are a lot of opportunities to work on datasets used for training models with general-purpose capabilities and/or building task-specific models.
Artisanal NLP resources may not be the most mainstream, but fills vital research gaps
As we all know, LLMs are all the rage today. In the past two years, there has been an explosion of open LLMs, and way more soon! However, working on LLM research is costly— a high-spec consumer-grade machine might not be enough to finetune a 7B-parameter model. So how do you contribute to the field if you are GPU-poor?
I will answer this in the context of my collaborations and other works.
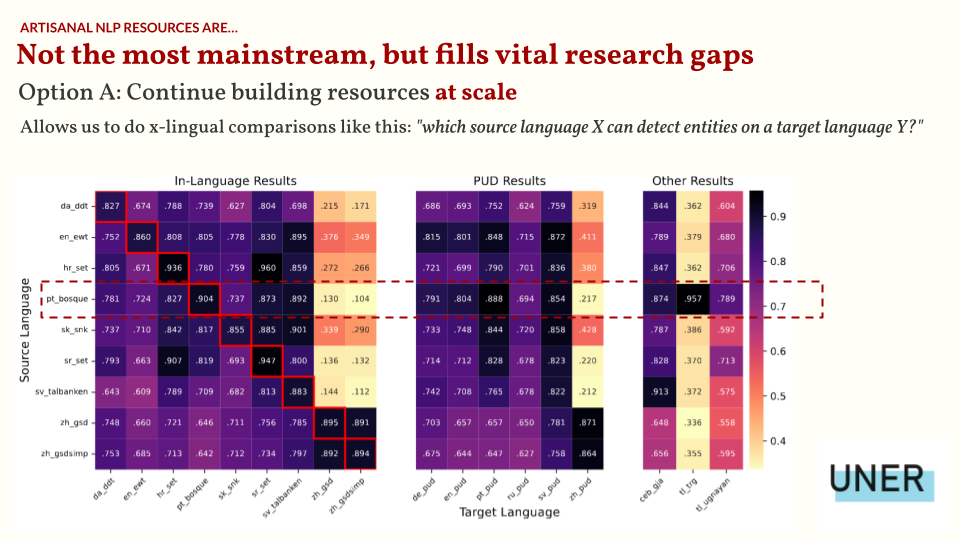
The first option is to continue building resources, but at scale. It’s quite common to see researchers first work on a single language (mostly that of their native tongue) and then move on to multilinguality, as the latter presents a different opportunity for creativity.
For Universal NER, we created a multilingual NER corpora for several languages, all based from treebanks in the Universal Dependencies (UD) framework. This effort allows us to create a consistent and standardized annotation for 13 diverse languages— very important for multilingual research.

As an illustration, we can do cross-lingual transfer learning as shown below, where we compare the performance of different models trained on a source language for different test set languages. We can even show that for low-resource languages like Tagalog, we can get by with training an NER model from a Portuguese treebank as an alternative.
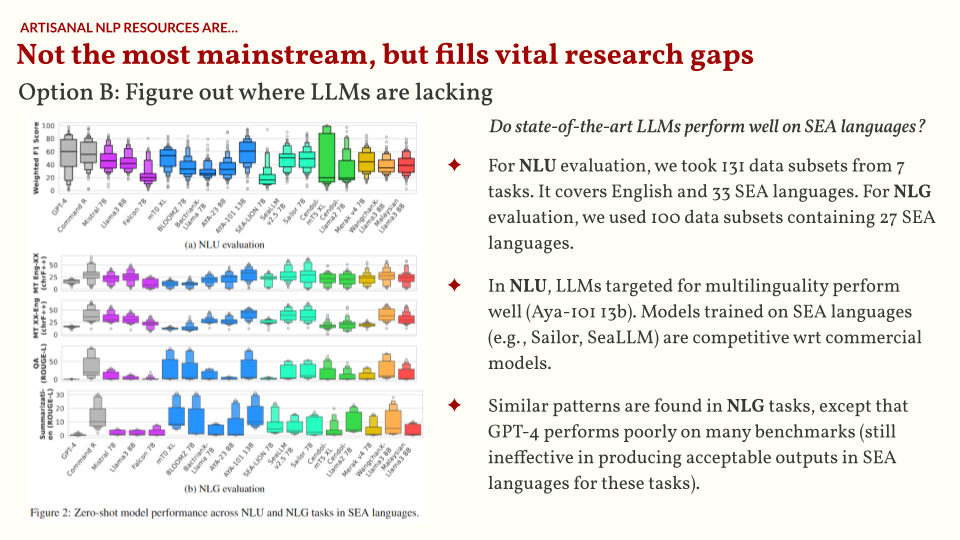
Another option is to figure out areas where LLMs are lacking. Most LLMs right now aren’t explicitly trained to be multilingual. They’re incidentally multilingual, probably because of some stray artifacts in their pretraining data. But for the past few months, we’ve seen the rise of multilingual LLMs such as Aya-101, Sea-LION, and more. Are they actually better for multilingual data?
That’s one of the questions we sought to answer in the SEACrowd project. First, we crowdsourced datasets all over Southeast Asia. This allows us to create a data hub for SEA-specific resources. The data hub, in itself, is already a big contribution. It also allowed me to see available datasets from the Philippines, and there’s actually quite a lot!
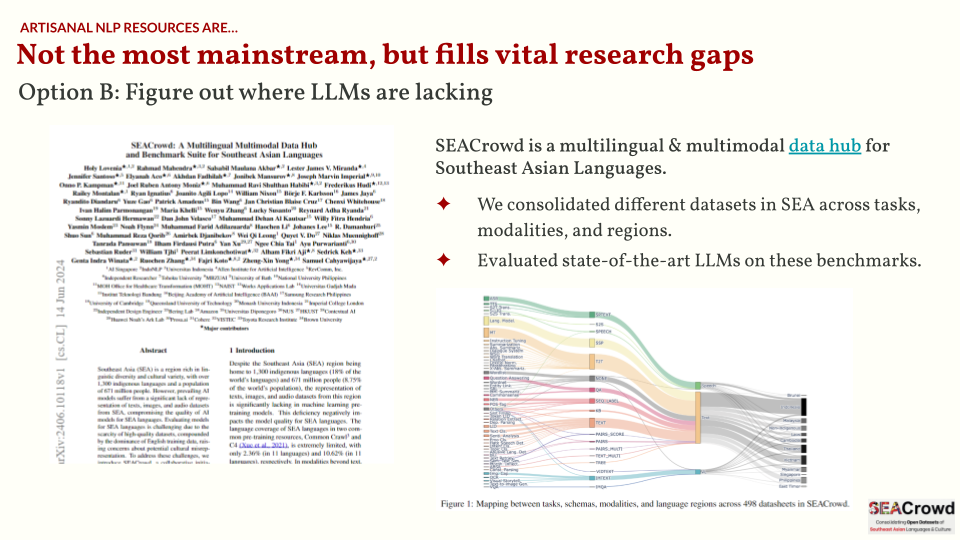
Then, we curated a multilingual SEA benchmark for both NLU (natural language understanding) and NLG (natural langauge generation) tasks. Upon testing, we found that LLMs trained for multilinguality actually perform quite well (e.g., Aya-101 13B). Even LLMs targeted for SEA languages are competitive with commercial APIs.
What I found very interesting is that when testing for generation “quality” (i.e., are the generated texts natural-sounding or translationese?), we found that even the best LLM is still 58% natural-sounding. There’s still a long way to go to improve the quality of generations. As of now, everything is still vibes-based, but having an empirical benchmark certainly helps!

Conclusion: what types of artisanal NLP contributions can you pursue?
I want to close this talk by showing you this chart. There are a lot of ways to improve Filipino NLP, it just depends on where you’re interested in:
- Model-centric or data-centric: what types of artifacts are you excited to build? Do you want to curate datasets or do you want to build models?
- General-purpose or specific: are you aiming to build towards generally-capable LLMs, or do you want to solve a specific task?
- Training or evals: what is the purpose of the artifact you’re creating? Is it for training models or for evaluating existing models?
There are opportunities for each quadrant of this chart. I myself am interested in data-centric approaches for both task-specific and generally-capable models. There’s still a lot of domains that need foundational NLP resources (think Universal Dependencies treebanks), and several questions can still be asked regarding the datasets we use for training state-of-the-art LLMs.
Hopefully this inspires you to figure out what your project would be!

Postscript
I really enjoyed preparing for this talk as it helped me synthesize my past work on Filipino NLP. Right now, I’m finding ways to marry my current research (preference / alignment-tuning for LLMS) and my previous work on low-resource and multilinguality. I’m quite inspired by works such as the PRISM Alignment Project, Cohere’s Aya-23 dataset, and the Multilingual Alignment prism. I think there are interesting questions at the intersection of multilinguality and preference data, but I don’t think our conclusions should be something like “Oh, people who speak language X prefers Y and Z” or “People from country A prefers B.” Still a long way to go, but I’m excited to pursue these topics in the future! If this caught your attention, feel free to reach out!