spaCy Internals: Rules-based rules!
One aspect of the spaCy library that I enjoy is its robust pattern-matching system. Yes, rules-based. Because sometimes, all you need is a hard and fast rule to cover relevant aspects of your problem. In this blog post, I’ll discuss a design pattern I learned while working on these components. I will focus on token and entity matching in the form of the Matcher.
How do we pattern-match in spaCy?
First things first, an overview of the spaCy
Matcher. You can define patterns as a list of
dictionaries, where each dictionary inscribes a rule to match a single token. A
rule is often in the form of {TOKEN_ATTRIBUTE: RULE}, which roughly translates
as: “match if this token attribute passes this rule.” There are multiple
attributes
to choose from, but let’s demonstrate a simple case.
Suppose I want to look for tokens with the form language. What I’ll do is
write this pattern:
pattern = [{"LOWER": "language"}]
This line translates as “match tokens where the lowercased form is equal to
language.” Using the LOWER attribute allows me to match instances like
Language or language, irrespective of the case. If I want to match in
verbatim, I might use TEXT or ORTH instead.
Now, if we want to match the term natural language processing, a common
mistake is to write a pattern like the one below. It won’t match anything in our
text:
# This is incorrect. The matcher works for each token.
pattern = [{"LOWER": "natural language processing"}]
Remember, each dictionary must match a single token. Instead, we’ll write them in separate dictionaries like so:
# This is correct. We match each token separately.
pattern = [
{"LOWER": "natural"},
{"LOWER": "language"},
{"LOWER": "processing"},
]
These are the basics for pattern-matching in spaCy. With multiple attributes, operators, and syntax, we have enough tools to express rules for matching almost any kind of text. I won’t be delving too much into it here since the documentation is comprehensive enough for that. Instead, I want to share a design pattern for writing and organizing rules.
Another way to organize patterns
One way to store patterns for the SpanRuler or
EntityRuler is through the patterns.jsonl
file. But if you find a JSONL file too unwieldy, then it’s also possible to
store patterns in a Python object then include them in the configuration
file. This approach makes your rules readable as you can annotate them however
you wish.
If you find a JSONL file too unwieldy, then it’s also possible to store patterns in a Python object then include them in the configuration file.
Store patterns in a Python object…
Suppose we’re extracting degree programs from some corpus. We start by creating a custom function that returns a set of rules as a list of dictionaries:
def my_patterns() -> List[Dict[str, Any]]:
rules = [
{"label": "Degree", "pattern": [{"LOWER": "bs", "OP": "?"}, {}, {"LOWER": "engineering"}]},
{"label": "Degree", "pattern": [{"LOWER": "bs"}, {}]}
]
return rules
We can then register the my_patterns function in the spaCy registry. The name
of the registry is arbitrary, but it’s good practice to store them in misc so that your
function is grouped together with similar ones:
from spacy.util import registry
@registry.misc("my_rules.v1")
def my_patterns() -> List[Dict[str, Any]]:
rules = [
{"label": "Degree", "pattern": [{"LOWER": "bs", "OP": "?"}, {}, {"LOWER": "engineering"}]},
{"label": "Degree", "pattern": [{"LOWER": "bs"}, {}]}
]
return rules
You can now organize your rules as you like. Personally, I write functions in the form of
rules_{entity}_{id} to differentiate between entities and the type of rule. I can then combine
these lists together by adding one over the other:
from spacy.util import registry
# Type alias
Rules = List[Dict[str, Any]]
@registry.misc("my_rules.v1")
def my_patterns() -> Rules:
rules = (
rules_degree_bs() +
rules_degree_phd() +
rules_course_engg()
)
def rules_degree_bs() -> Rules:
"""Define rules that extract BS degrees from a text"""
rules = [
{"label": "Degree", "pattern": [{"LOWER": "bs", "OP": "?"}, {}, {"LOWER": "engineering"}]},
{"label": "Degree", "pattern": [{"LOWER": "bs"}, {}]}
]
return rules
def rules_degree_phd() -> Rules:
"""Define rules that extract doctorate degrees from a text"""
rules = [
{"label": "Degree", "pattern": [{"LOWER": "phd"}, {"LOWER": "in"}, {}]},
{"label": "Degree", "pattern": [{"LOWER": "doctorate"}, {"LOWER": "in"}, {}]}
]
return rules
def rules_course_engg() -> Rules:
"""Define rules that extract courses from the engineering dept."""
rules = [
{"label": "Degree", "pattern": [{"LOWER": {"IN": ["elc", "engps"]}}, {"IS_DIGIT": True}]},
]
return rules
Writing our patterns this way allows us to organize and annotate them. If you’re using an IDE, then it’s also a good way to pre-validate our rules of any syntax or formatting errors. There are many times when a missing bracket or quotation cost me hours of debugging. Lastly, if you’re using a formatter like black, then you can improve your pattern’s readability.
…then include them in the configuration file
We can take advantage of spaCy’s assemble
command to include our patterns in a configuration file. Suppose we want to
improve the performance of a named-entity recognizer model using the patterns we
defined above (via the SpanRuler), then the
process looks like this:
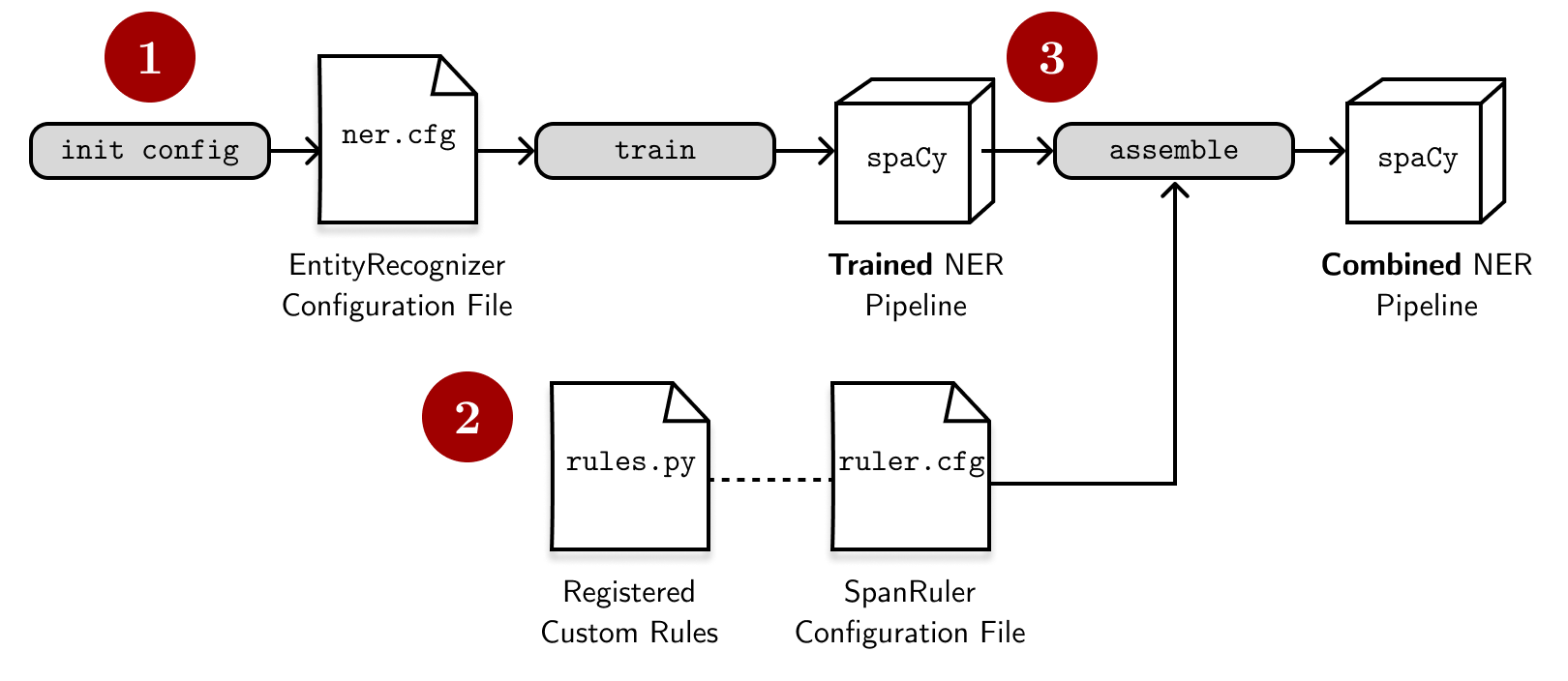
- We have the base configuration
ner.cfgthat trains anerpipeline and stores the model in thetraining/model-bestdirectory. We can create this configuration through theinit configcommand. -
We also write another configuration for the SpanRuler,
ruler.cfg, that defines how it will behave. Here, we reference the name of the registered function (my_rules.v1) and other parameters for the component. The configuration file looks like this:# ruler.cfg [nlp] pipeline = ["tok2vec","ner", "span_ruler"] [components] [components.tok2vec] source = training/model-best [components.ner] source = training/model-best [components.span_ruler] factory = "span_ruler" spans_key = null annotate_ents = true ents_filter = {"@misc": "spacy.prioritize_new_ents_filter.v1"} validate = true overwrite = false [initialize.components] [initialize.components.span_ruler] patterns = {"@misc": "my_rules.v1"} -
We use the
assemblecommand to combine the trained model and the SpanRuler. This translates into a new model,model/spanruler, that has the rules added on top of the trained model. Note that we have to include the filepath of our registered function in the--codeparameter so that spaCy can see it:python -m spacy assemble \ configs/ruler.cfg \ models/ner_ruler \ --components.tok2vec.source training/ner/model-best \ --components.ner.source training/ner/model-best \ --code rules.pyNote that we also need to source the
tok2vecandnercomponents from the trained NER model.
It’s also possible to have a single configuration file that contains both
the ner and span_ruler components. The downside in this approach is that
if you’re still iterating on your patterns, then you have to train a new NER model
every time. With two separate configurations, we decouple the statistical model
from our rules.
With two separate configurations, we decouple the statistical model from our rules.
More on SpanRuler’s parameters
Let’s step back a bit and examine the ruler.cfg configuration file in detail.
Notice how the number of parameters present is small because we’ll use it as an
“extension” of the baseline config through the
assemble command.
First, the pipeline parameter declares the components present in the spaCy
pipeline with their order. We add the span_ruler after the ner component.
This process is similar to calling the command nlp.add_pipe("span_ruler", after="ner"):
[nlp]
pipeline = ["tok2vec","ner", "span_ruler"]
Then we source the tok2vec and ner pipelines from the trained NER model.
Here, we pass the path to model-best. We can also override these parameters in
the actual assemble command by passing
a value to --components.tok2vec.source and --components.ner.source:
[components.tok2vec]
source = training/model-best
[components.ner]
source = training/model-best
Then, we setup the parameters for the
SpanRuler. Here, we want it as an improvement
to our NER pipeline, so we set annotate_ents=True and spans_key=null (we’re
not interested in span categorization).
This setting enables the SpanRuler to assign
the detected entities in the Doc.ents attribute while ignoring Doc.spans. We
don’t want to erase the entities detected by the original NER model, so we set
overwrite to false.
[components.span_ruler]
factory = "span_ruler"
spans_key = null
annotate_ents = true
ents_filter = {"@misc": "spacy.prioritize_new_ents_filter.v1"}
validate = true
overwrite = false
Lastly, we initialize our SpanRuler by
passing it our custom registered function. Because we registered my_rules.v1
in the misc registry, we can access it using the dictionary format below:
[initialize.components.span_ruler]
patterns = {"@misc": "my_rules.v1"}
Final thoughts
In this blog post, I talked about a design pattern to better organize and
write rules. Here I introduced a “config-first” approach that stores our
rules as a registered function in a configuration file rather than in the
patterns.jsonl file. We also talked about using spaCy’s
assemble command to combine the ner and
span_ruler pipelines together. Also, huge thanks to Ákos
Kádár for helping me realize this
approach while I was working on the SpanRuler.
Lastly, you can find an example project for the
SpanRuler that uses this pattern in the
explosion/projects repository. Feel
free to clone and use it as a starting point!