
Navigating the MLOps tooling landscape (Part 3: The Strategies)
This is the last of a three-part series on the MLOps landscape. Here, I’ll discuss some adoption strategies based on the ecosystem we’ve defined. I highly recommend reading Part One and Part Two before reading this post.
In the last section, we examined the MLOps landscape by clustering them into four quadrants, each based on the nature of their artifacts and scope in the ML lifecycle. By doing so, we arrived at the following graph:

Here, I’ll talk about strategies for integrating these tools into our organization. I’ll be using my own interpretation of the Thoughtworks’ Technology Radar and borrow familiar terms such as Adopt, Trial, Assess, and Hold. Note that this will be a bit opinionated, and your mileage may vary!
Contents
To recap, this is a three-part blogpost where I attempt to navigate the MLOps landscape. I’ll be focusing on the commercial side, i.e., the tools, startups, and frameworks that I’ve seen while I answer three key questions:
- Who/what will benefit?: we’ll set the stage by asking who will benefit by adopting these tools. Here, I’ll introduce my version of the ML lifecycle.
- What do you want?: I’ll describe a framework for categorizing MLOps tools, and outline a specific adoption strategy for each group.
- What do I recommend?: I’ll list down some decision frameworks I recommend based from experience and research.
What do I recommend?
Thoughtworks’ Technology Radar
Before we jump in, I want to introduce Thoughtworks’ Technology Radar. I first saw it from Neal Ford’s blogpost, where he shared his organization’s way of “being proactive in their technology choices,” and “objectively assessing technology uses in the wild.” I encourage you to read it, especially if you’re a senior engineer or an IT lead.
He breaks the radar down into four rings— Adopt, Trial, Assess, Hold:
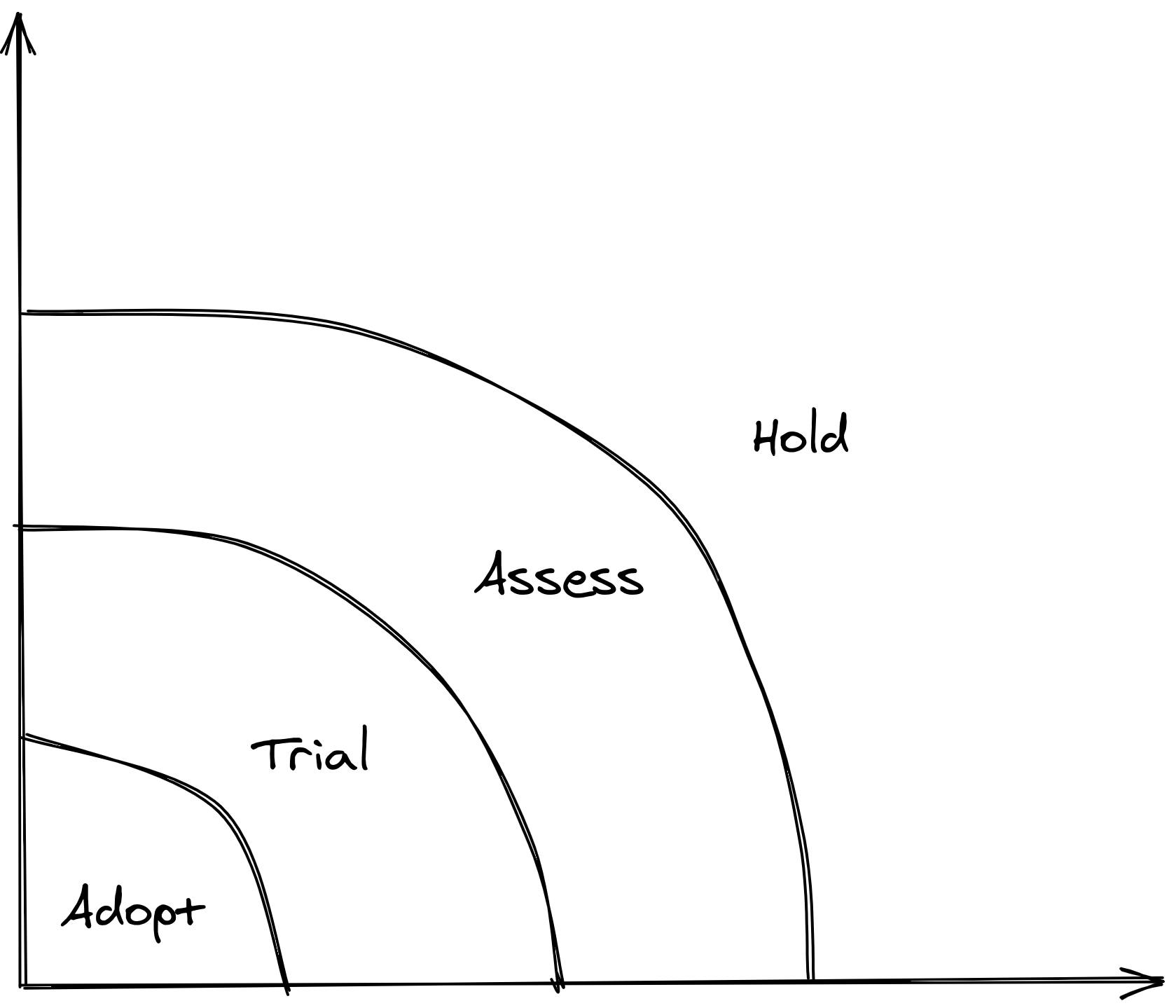
Below is a table that describes the appropriate strategy for each ring, and example initiatives that can be done:
| Rings | Strategy | Example Actions |
|---|---|---|
| Adopt | Use this tech if you don’t want to get left behind. No-brainer | Org-wide training, enforcement, adoption strategy |
| Trial | Pursue in a low-risk project or environment | Internal greenfield projects, small-scale work |
| Assess | Explore and understand how it will affect you and your team | Research projects, non client-facing work, dev spikes |
| Hold | Don’t bother for now, they are too new to reasonably assess yet | Lunchtime brownbags, attending conference sessions |
Some observations:
- Similar to the Gartner Hype Cycle, tools usually move from Hold to Adopt as engineers start to use it for real-world problems and uncover its limitations past the marketing fluff.
- A good litmus test for a tool to move from Assess to Trial is to use it in a fairly-sized project.
- For tech that falls into the Hold category, Neal Ford mentions that “there’s no harm in using it on existing projects,” but think twice when using it for new ones.
Personally, I like writing a tech radar because it grounds me from being too distracted by the shiny new object. In addition, it makes me aware of the technology bubbles I’m in. We’ll be using the same framework for the MLOps landscape.
Technology Radar for MLOps
To cut to the case, here’s my opinion on how to best adopt the MLOps landscape:
In the figure above, I partitioned the ML landscape from Part Two into their corresponding adoption strategy. Treat the four regions as fuzzy, they only serve as rough guides on what best to do depending on where the tool falls under.
Adopt
| Strategy | Type of Tools | Description |
|---|---|---|
| Adopt | General Cloud Providers, Common SWE Stack, CI/CD Pipelines, Data Orchestrators | No-brainer. Build or plan capabilities on them as early as possible. |
This category includes tools I highly-recommend integrating into your org. Note that decisions for adoption still depends on a variety of factors such as price, team size, type of projects, and more. Nevertheless, it’s still a good option to consider them in your tech roadmap.
We see most software-engineering tools in the Adopt region. The usual suspects like Git, Docker, and Kubernetes1 can be considered as “no-brainers.” They’re almost the bread-and-butter of sofware development, that building capabilities on them becomes paramount.
The same goes for CI/CD and ETL tools. If you’re reading an MLOps article, chances are you’re dealing with data. Pipelining tools such as Airflow and Dagster should help structure the ingress and egress of data from various sources. On the other hand, CI/CD tools improve your overall development workflow.
Lastly, you’ll find the top Cloud platforms under this category. Sure, you might just need a Heroku instance or a DigitalOcean droplet, but as your needs grow, investing in a solid cloud platform is a viable strategy for future-proofing your analytics toolkit. AWS, Azure, and GCP are sustainable choices because it opens up a wide range of capabilities that you’ll probably need.
Trial
| Strategy | Type of Tools | Description |
|---|---|---|
| Trial | Vendor AI Platform, ML IaaS, Experiment Platforms | Benefits outweigh risks. Be wary of limitations and non-breaking changes |
| Trial | Data Version Control, Single Component ML tools | Since scope is low, easy to plug-in and remove from your project if it doesn’t suit your needs. |
This category of tools can be used in a mid-sized project while being mindful of its risks. Most of the tools are new (2-3 years old), so they change their APIs quite frequently. Nevertheless, they offer more advanced capabilities in the ML and Engineering domains, that it’s too good to pass up. My advice is to test them out first in low-risk projects before adopting them as your daily driver.
Vendor-based data science platforms such as Sagemaker, Google AI (now Vertex), and Azure ML are viable choices if you’re already subscribed to a cloud platform. Key benefit is less friction—you can just think of these as additional services to your cloud stack. Their offerings change too frequently (looking at you, Google), so just be careful with that.
If you wish to separate your data science workloads, then a Big Data or ML-focused IaaS may be another option. In my opinion, most of these niche platforms are more attuned to user pains than your cloud vendor. There are tradeoffs, of course. If you rely on specialized cloud services like BigQuery, Fargate, or Cloud Run, then it may be difficult to integrate, security notwithstanding.
Lastly, specialized ML tools are a must-try. Since their scope is “low” in the ML lifecycle, it’s less risky to replace them if it didn’t work out. Moreover, because they solve a single problem in your ML lifecycle (DVC for versioning data, Deepnote for notebooks, Prodigy for labelling), the benefits are always clearer and more apparent.
Assess
| Strategy | Type of Tools | Description |
|---|---|---|
| Assess | High-coverage SaaS, ML Project Frameworks, ML Task Orchestrators | Check feasibility on internal research projects. Assess age and community before trying them out. |
Most of the all-in-one machine learning platforms fall under this category. My recommendation is to try them out in internal research projects, assessing how it can affect your organization. The main difficulty for adopting these tools is that they are a hard-commit: you need to follow their way of doing things to reap long-term benefits.
Sometimes, it helps to follow the crowd. What I do to keep myself level-headed with these technologies is to check-in with interest-groups such as MLOps Community, The Sequence, and Kubernetes SIG. Having a strong community behind the tech is beneficial.
Another signal I look for is age. Since MLOps is quite new, platforms that are more than two years old is on top of my list. Moreso if a platform is already being used by a large company and they’re just open-sourcing it. A “well-aged” tech ensures that it was battle-tested, and common bugs and kinks have been ironed-out.
With that said, MLFlow, Kubeflow, and WandB are my top choices. All are backed by a strong community, as they’ve already been used by alot of companies and startups. Age also checks-out, with all of them hitting the 2-year old mark.
Hold
| Strategy | Type of Tools | Description |
|---|---|---|
| Hold | No-code ML Platforms, Custom ML Platforms | Still in speculation. Don’t bother for now, but useful to gather knowledge on what they do. |
If you have noticed from the graph, there are no tools left at this point. However, the region where you need to hold-off adoption falls into the extremes of all-in-one ML platforms. What kind of tools are in this edge? We can only speculate:
- No-code ML Platforms: although I like the abstraction low-code platforms can bring, it’s still too early to use them in production use-cases. I haven’t seen alot of products in this space, but I can imagine something similar to Google Teachables.2 Perhaps, this set of tools cater to a new kind of persona.
- Custom ML Platforms: this set of tools can be industry specific, and has advanced capabilities for a particular application. Unfortunately, these may often be bespoke solutions that fail to generalize to your use-case.
So far, all of these things are still in speculation. Most of the newer MLOps tools are often in the Assess or Trial stage, so it’s still safe to try them out.
Build vs Buy
By the looks of it, it seems that I advocate for buying— and rightly so. “Buy by default” is still my current stance. In this section, I’ll outline cases when you should or should not build.
- Don’t build if MLOps isn’t your core business. If you’re in a large organization or consulting shop, then investing on build is useless. You’ll be competing with startups that dedicate 100% of their resources on improving their MLOps product. It’s way easier to just use what is available.
- Given that, build integrators and connectors. Although I advise against building your own tool, I advocate for creating connectors between tools. Don’t build your own ETL or annotation tool, but write a framework for connecting the two. It will be more fit to your business use-case.
- Buy specialized ML tools first. As mentioned in the Trial section, they are easier to plug in and out of your system. It also gives you a lot of opportunity to mix and match products that suit your organization’s existing workflow.
These assertions are still falsifiable by counterexample. Kedro, an ML project framework, was built inside QuantumBlack, a consulting shop. However, you can also see that it’s an integrator for Argo, Prefect, Kubeflow, and more. Again, treat these statements as a rule-of-thumb, not gospel truth.
Conclusion
In the final part of this series, we applied Thoughtworks’ Technology Radar to our MLOps landscape. We categorized tools under Adopt, Trial, Assess, and Hold. Most of the tools mentioned in Part Two fell under the first three categories, while we speculated on the final one.
Then, we looked into various cases of building and buying. In a few words, it’s better to buy by default if your core business is not about MLOps. However, there’s still value in creating integrators to glue all these products together. With that said, I highly-recommend buying or trying specialized ML tools first.
That ends my three-part series no the MLOps landscape. Thank you again, reader, for accompanying me in this journey! As I always say, I hope you enjoyed your time here and learned something new. Feel free to drop a comment below if you think that I misrepresented some of the tools above. There’s too much, and honestly it’s really hard to keep up. Until next time!

Changelog
- 06-01-2021: This blog series was featured in Issue 19 of the MLOps Roundup Newsletter!
- 05-28-2021: This blog series was featured in Analytics Vidhya!
Previous Sections
- Part I: Navigating the MLOps Landscape—The Lifecycle
- Part II: Navigating the MLOps Landscape—The Ecosystem
If you like this, you’ll enjoy:
-
I don’t advocate using Kubernetes on every project. Sometimes you can do away with serverless options provided by your cloud provider (less debt). However, it may be important to build capabilities on this tech as you grow. ↩
-
Of course, Teachables isn’t a machine learning platform. However, I imagine that the user-experience can be as seamless as this one in the future. At that point, it will even go beyond the standard lifecycle researchers and software engineers experience. ↩