
Navigating the MLOps tooling landscape (Part 2: The Ecosystem)
This is the second of a three-part series on the MLOps landscape. Here, I’ll discuss the ecosystem itself, and the frameworks and tools I encountered. I recommend reading Part One first, then Part Three last.
Previously, we tried to answer the question of who will benefit from MLOps. This brought us to our two personas, the ML researcher and the software engineer. Despite working closely together, there are often gaps in their dynamic as seen in their wants, needs, and frustrations.
Upon closer inspection, their interaction can be modeled similarly to the machine learning lifecycle, which consists of two loops interlocked together:

The ML lifecycle will serve as our lens in navigating the MLOps landscape. As we’ve mentioned in the previous post, a good MLOps tool should provide the needs, address the wants, and quell the frustrations of our researchers and engineers.
A good MLOps tool should provide [our researchers’ and engineers’] needs, address their wants, and quell their frustrations.
We will continue our analysis, this time diving deep into the MLOps landscape, while examining the tools and frameworks present in each area.
Contents
To recap, this is a three-part blogpost where I attempt to navigate the MLOps landscape. I’ll be focusing on the commercial side, i.e., the tools, startups, and frameworks that I’ve seen while I answer three key questions:
- Who/what will benefit?: we’ll set the stage by asking who will benefit by adopting these tools. Here, I’ll introduce my version of the ML lifecycle.
- What do you want?: I’ll describe a framework for categorizing MLOps tools, and outline a specific adoption strategy for each group.
- What do I recommend?: I’ll list down some decision frameworks I recommend based from experience and research.
What do you want?
In this section, we will survey the landscape of MLOps tools, and see how we can best navigate through it. We can map the terrain by defining some landmarks. Based on the ML lifecycle, we can determine if a tool is:
- Software-focused or model-focused: describes the type of artifact it helps produce. The former involves typical artifacts an engineer encounters even outside ML, whereas the latter is centered around a trained model most researchers care about.
- Piecemeal or all-in-one: describes the scope of a tool. Piecemeal only affects one or two processes in the ML lifecycle, whereas all-in-one attempts to cover it end-to-end.
Together, we can combine them into a graph like this:
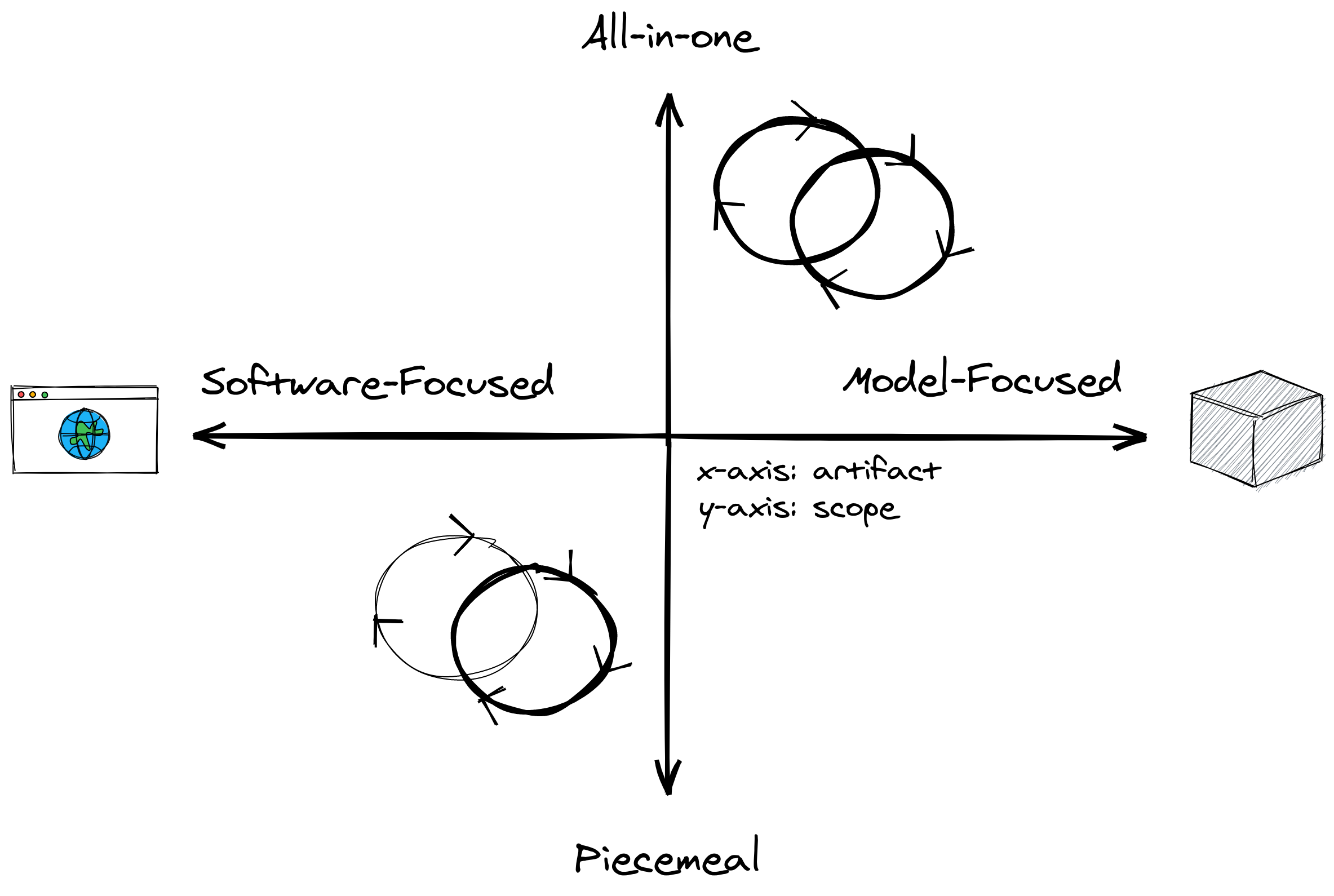
Notice that we “decomposed” the ML lifecycle into two axes. I’ll go ahead and name each quadrant based on which axis it falls into:
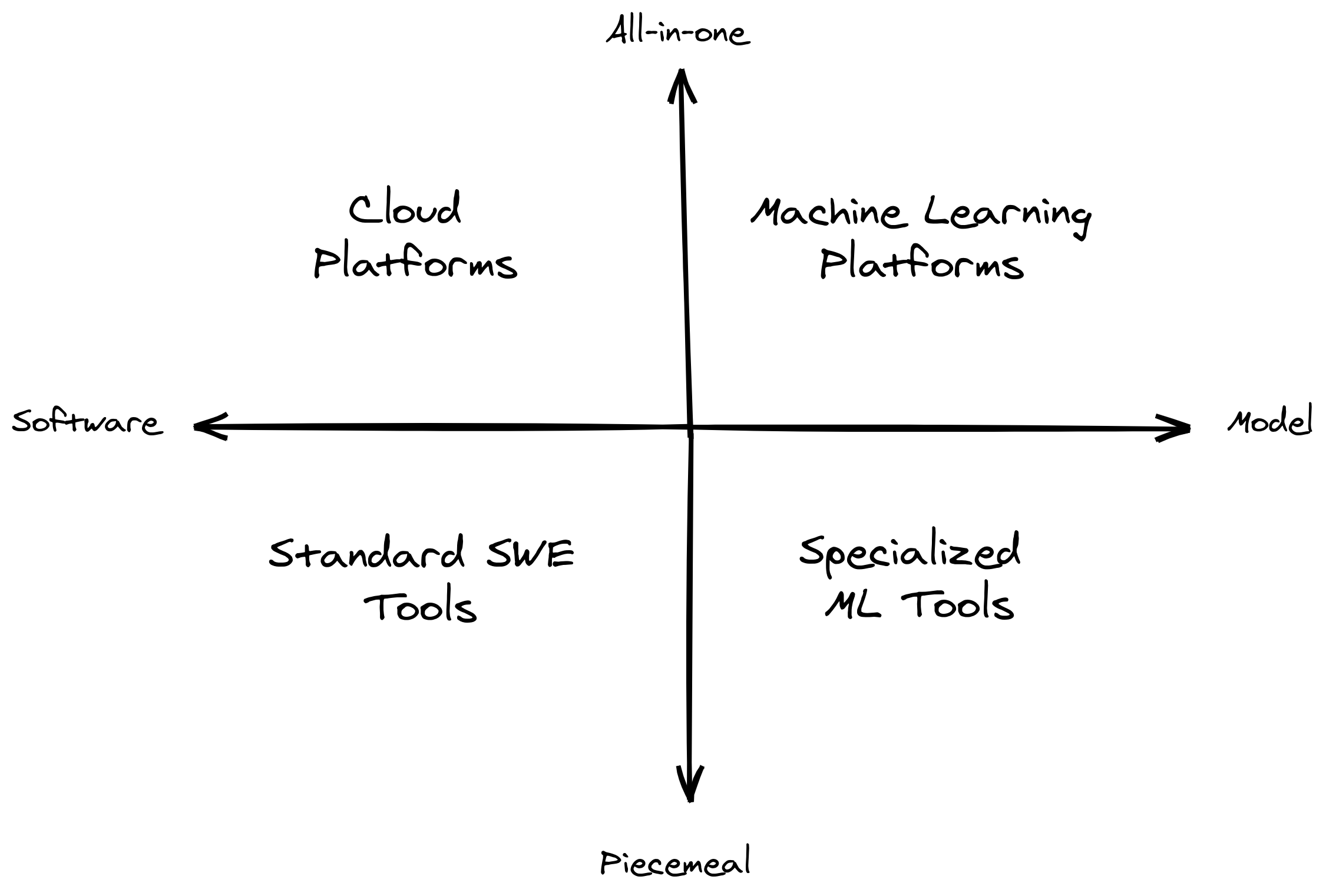
I describe the top quadrants as platforms1. They usually provide an integrated, all-in-one space that covers most of the developer experience. On the other hand, the bottom quadrants can be thought of as specialized tools. They consist of software that is modular enough to be integrated into any workflow.
For each quadrant, we have, in clockwise order:
- Cloud Platforms: at its core, a group of services that provides storage and compute capabilities in an Internet-based data center.
- Machine Learning Platforms: provides an end-to-end experience that affects the majority of a researcher’s machine learning workflow.
- Specialized ML Tools: includes a variety of custom tools that affect how a researcher performs a particular machine learning task.
- Standard SWE Tools: the standard software toolkit engineers use, even outside the context of machine learning.
Let’s closely examine and get representative samples for each quadrant. Note that the examples are highly-arbitrary— most of which I encountered in my day-job, or something that just piqued my interest from the news.
1. Cloud platforms
The first quadrant involves tools that serve the whole ML lifecycle, especially in the creation of data products such as web apps, dashboards, and more.

As we go left, the tools generalize to any kind of software artifact, and as we move right, they cater more to producing machine learning models.
| Category | Examples | My Field Notes |
|---|---|---|
| General Cloud Providers | AWS, GCP, Azure, etc. | A mainstay in any medium to large-sized company. Provides compute and storage for various applications. |
| Vendor AI Platform | Sagemaker, GCP AI, Azure ML | A subset of services from a cloud vendor that caters to various components of the ML lifecycle. |
| Big Data IaaS | Cloudera, Paperspace CORE, etc. | Provides a range of services geared towards big data. Application may not necessarily be about ML. |
| ML-focused IaaS | Paperspace Gradient, Floydhub, Domino | Provides infrastructure for ML experimentation and deployment |
Notice that most technologies found in this quadrant include IaaS (Infrastructure-as-a-Service) providers. Since compute and storage is generic enough, it can generalize to any type of application. An ML-focused IaaS may provision special requirements for machine learning applications, such as access to powerful GPUs, TPUs, and the like.
2. Machine learning platforms
This set of tools is one of the hardest to cluster because their features often overlap. Note that if the number of use-cases exceeds two to three, I tend to consider them as all-in-one platforms.
As you move right, the artifacts produced tend to specialize on ML models, and as you move up, the number of supported ML processes increases.

One common pattern is that these tools tend to think of the ML lifecycle as direct-acyclic graphs (DAGs). They take advantage of this structure for various lifecycle operations such as tracking, execution, and versioning to name a few.
| Category | Examples | My Field Notes |
|---|---|---|
| High-coverage SaaS | Valohai, DAGsHub, ClearML, Polyaxon | This includes platforms that supports multiple components of the ML lifecycle. They are almost a self-serve framework with minimal infrastructure requirements. |
| ML Project Frameworks | Kedro, MLFlow, Metaflow, Flyte | Provides a unifying API for data science teams to improve collaboration, and smoothen the experience from experimentation to production. |
| ML Task Orchestrators | Kubeflow, Metaflow, Flyte | Provides a framework for treating each ML process as a node in a graph that can be run in an underlying infrastructure. |
Another common pattern I found, funnily-enough, is the use of the word -flow. To clear it up, here’s the difference between Kubeflow, MLFlow, and Metaflow:
- Kubeflow is a collection of open-source tools that aims to run ML processes on top of Kubernetes. It has a tool for hyperparameter optimization (Katib), serving (Fairing, KFServing), and pipelining (Pipelines).
- MLFlow is a framework for doing ML experiments. Notable use-cases include logging and tracking . Lately it’s adopting more use-cases such as project and model organization. You can use MLFlow within Kubeflow—I don’t see them as competitors.
- Metaflow is a task-orchestration framework. You need to write Metaflow-specific code for it to run (think Airflow or Dagster). However, it’s built with ML experiments in mind as reflected in its API.
3. Specialized ML tools
This group caters to specific aspects of the ML lifecycle. I decided to just group all single-component tools together. For example, Deepnote impacts the notebook workflow, while Prodigy and Optuna affect data annotation and hyperparameter optimization respectively.

As we move right, the tools usually affect models, and as we move left, they affect data. This is why data labelling and versioning tools are on the left, and notebook & hyperparameter optimization tools are on the right.
| Category | Examples | My Field Notes |
|---|---|---|
| Experimentation Platforms | Comet AI, Weights and Biases | Provides a platform for experimentation and tracking model lineage. They often lack pipelining or orchestration, but make it up with a powerful experimentation platform. |
| Data version control | DVC, Pachyderm | Includes tools for data versioning, management, and tracking. Their impact is data-heavy, and are often offered in tandem with a pipelining tool. |
| Single-component ML tools | Optuna, Prodigy, Deepnote, etc. | These are highly-specialized ML tools that cover a variety of use-cases such as hyperparameter optimization, data labelling, or notebook services. |
What I like about this category is that they can usually serve as drop-in replacements for a specific workflow. Sure, its scope is smaller than all-in-one platforms, but they may be easier to integrate.
4. Standard SWE tools
This suite of tools can be found in almost any software engineer’s toolbox. They’re used even outside the context of ML, yet any ML pipeline that involves productization includes them. As you go left, the tools will cater more and more to producing software artifacts. As you go right, they become more data-centric.
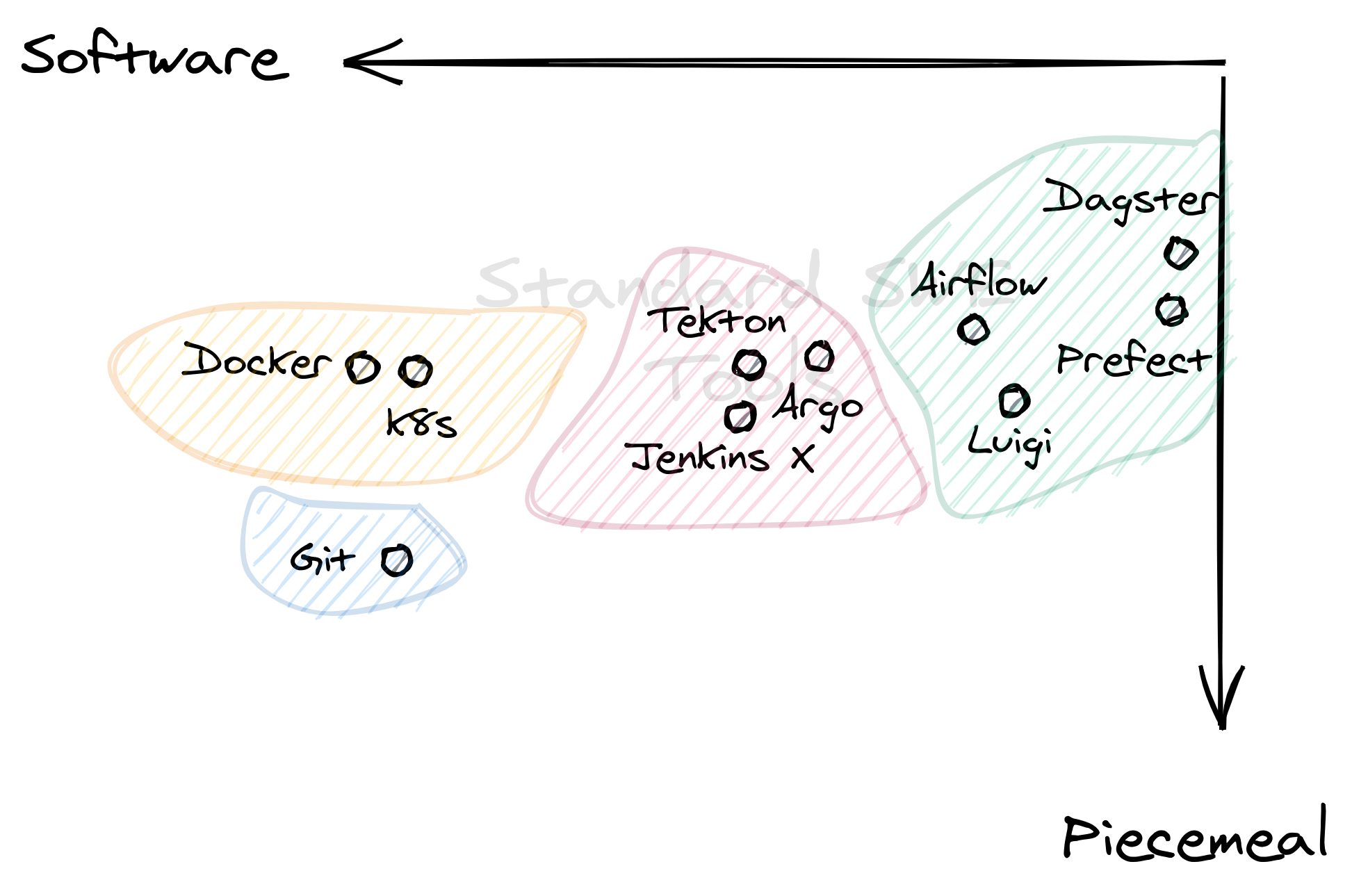
Git, Docker, and Kubernetes (k8s) are no-brainers in this space. However, I still included them because they’ve become an integral part of any ML workflow.2
| Category | Examples | My Field Notes |
|---|---|---|
| Data Orchestrators | Dagster, Airflow, Luigi, etc. | Contains a large category of tools for creating data pipelines, managing data lineages, and performing ETL processes |
| CI/CD Pipelines | Tekton, Argo, Jenkins X | Group of tools that use cloud-native continuous deployment pipelines. Each “task” often runs in a container and then managed by Kubernetes. |
| Common SWE Stack | Docker, Kubernetes, Git, etc. | The common software engineering stack, special mention to the three since you often see them in an ML productization workflow. |
Observations
Lastly, I’d like to share two interesting observations from our plot. They may be obvious due to our framework, but I see no reason not to point it out.
- From Any-task to ML-task orchestration: most of the tools found in this
diagonal can be thought of as orchestrators. They stitch multiple tasks
together into a coherent workflow. As we go right, the tasks evolve from
being generic to ML-specific.
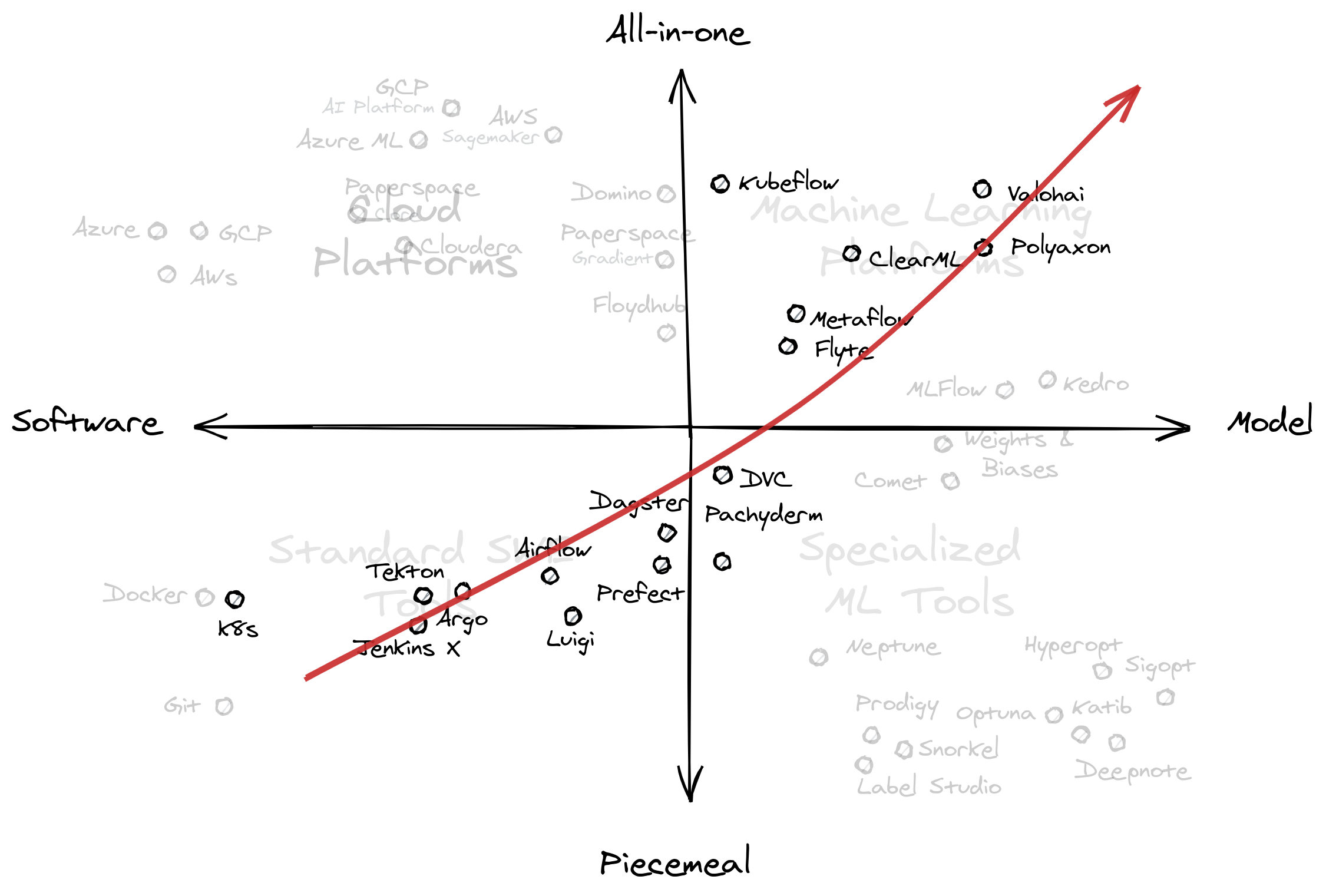
- From building software to building models: this is a bit obvious but as we
move downwards from left to right, the tools in the diagonal shift their
focus into producing an ML model. Most orgs stay at the left end, adopting
tools at the right to cater to their researchers.
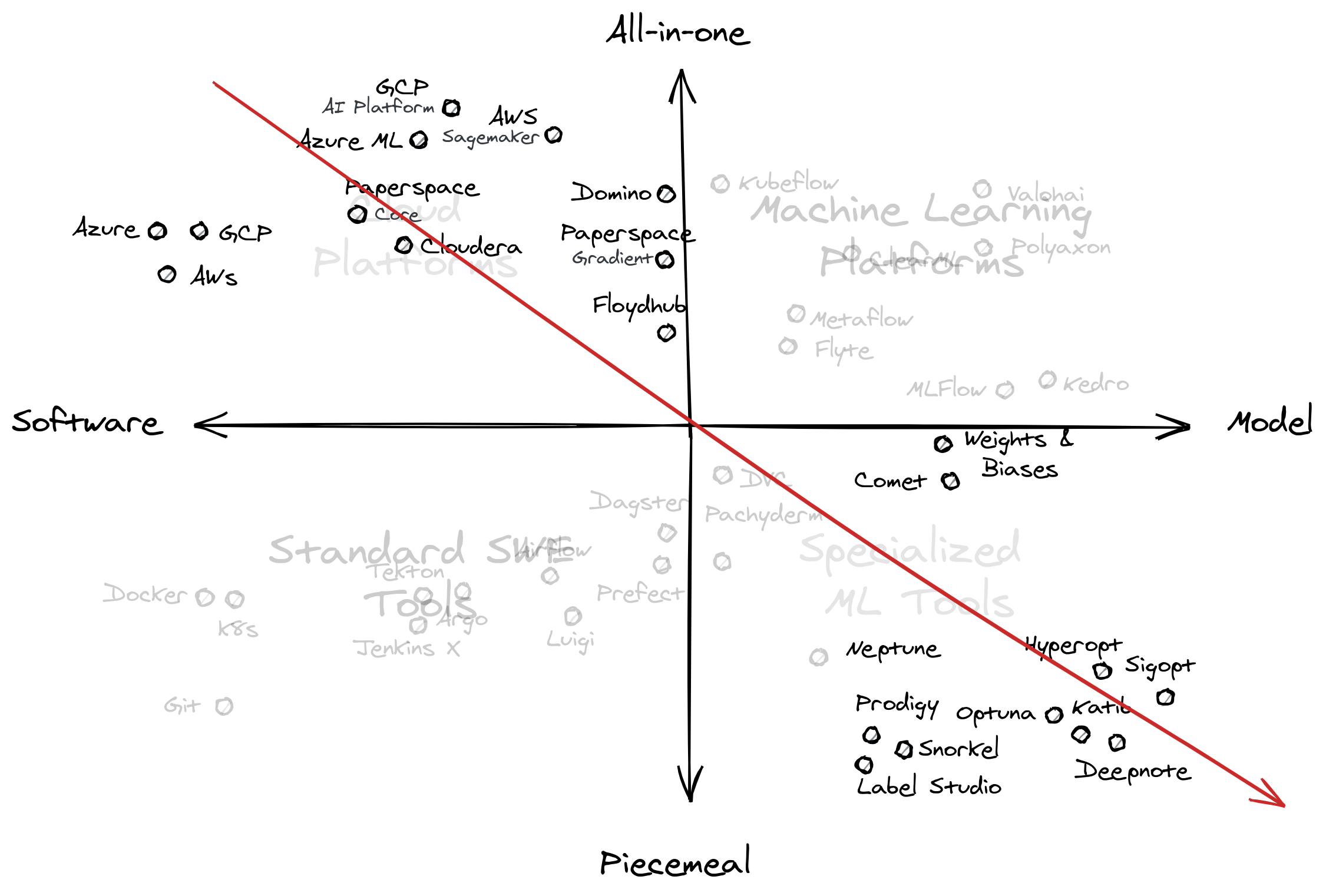
We’ll go back to this diagonal in the next section, but I can allude to the idea that you can also “plot” your organization’s capabilities in a similar fashion: are your engineers and researchers at opposite ends, making integration difficult? or do you stay at a particular region, frustrating one group for the benefit of another?
Conclusion
In this section, we examined the MLOps landscape by placing them on two axes: (1) if their artifacts are software or model focused, and (2) if they affect a part or the entire ML lifecycle. Given this framework, we got the graph as shown below:

We then categorized each quadrant as cloud platforms, ML platforms, standard SWE tools, and specialized ML tools. For each group, we examined clusters of tools that relate to one another.
Lastly, we surfaced two observations by looking at the main diagonals of the plot. We established the progression from any-task to ML-task orchestration, and from building software to building models.
In the next section, we will take this graph further, and look into some adoption strategies that we can apply for each quadrant. I will adapt Thoughtworks’ Technology Radar model as our main framework for analysis. See you!
Postscript
Of course, this is an opinionated guide, and I’m pretty sure that I’ve missed out on some tools and technologies in the MLOps space. I focused on those that I encountered in my day-to-day as representative samples for each group.
- If you’d like a tool or framework to be added in the graph, let me know. I’d also appreciate if you tell me where it falls under our graph.
- If you think that a particular tool should belong to a different group, let me know as well.
Changelog
- 06-01-2021: This blog series was featured in Issue 19 of the MLOps Roundup Newsletter!
- 05-28-2021: This blog series was featured in Analytics Vidhya!
- 05-22-2021: Fix some minor grammar and usage issues.
Next Sections
If you like this, you’ll enjoy:
- Navigating the MLOps Landscape (Part 1: The Lifecycle)
- How to use Jupyter Notebooks in 2020 (Part 2: Ecosystem growth)
- How to use Jupyter Notebooks in 2020 (Part 1: the data science landscape)
Resources
- Huyen, Chip (2020). “CS 329S: Machine Learning Systems Design”. In: stanford-css329s.github.io
- Zinkevich, Martin. (2017). “Rules of machine learning: best practices for ML Engineering”. Available: https://developers.google.com/machine-learning/guides/rules-of-ml
-
I’m using the term Platform loosely here. It’s not platform as Platform-as-a-Service, rather platform as a group of technologies. To avoid confusion, I’ll indicate PaaS when I meant PaaS. ↩
-
You might not always need k8s, a managed solution is often enough. I included this because it’s good to have representative sample from the non-ML software side. ↩