
How to stream Twitter using Python
Streaming tweets can be a fun exercise in data mining. With almost a million
tweets being published everyday, there is an enormous wealth of data that can
be gathered, and insights to be discovered. Today, we will utilize a powerful
Python library called tweepy to access tweets
from the web in real-time.
The main idea is that we will first (1) generate Twitter credentials online
by making a Twitter App, and then (2) use tweepy together with our
Twitter credentials to stream tweets depending on our settings. We can then
opt to (3) save these tweets in a database, so that we can perform our own
search queries or (4) export them later as .csv files for analysis.
In this tutorial, we will create two files, the Twitter scraper routine
scraper.py, and the .csv exporter dumper.py. Steps 1 to 3 correspond to
the scraper while the last step is for the dumper:
- Generate Twitter credentials
- Create the
StreamListenerclass usingtweepy - Save tweets into an
SQLdatabase - Convert database into a .csv file
Dependencies
I’ll be using Python 3 (3.5.2) in conjunction with the following libraries.
If you don’t have the following modules, you can simply install them using
Git Bash and then pip install <module>:
- Tweepy,
tweepy, for streaming Tweets. This is required, obviously. - dataset,
dataset, a lightweight database module where we can store our tweets. - SQL Alchemy,
SQLAlchemy, an object relational mapper (ORM) that can be used for Python.
Generate Twitter Credentials
If you don’t have a Twitter account, make one. Once you’re done, head over to https://apps.twitter.com/ and “Create a New App.” You will then see a similar form below:
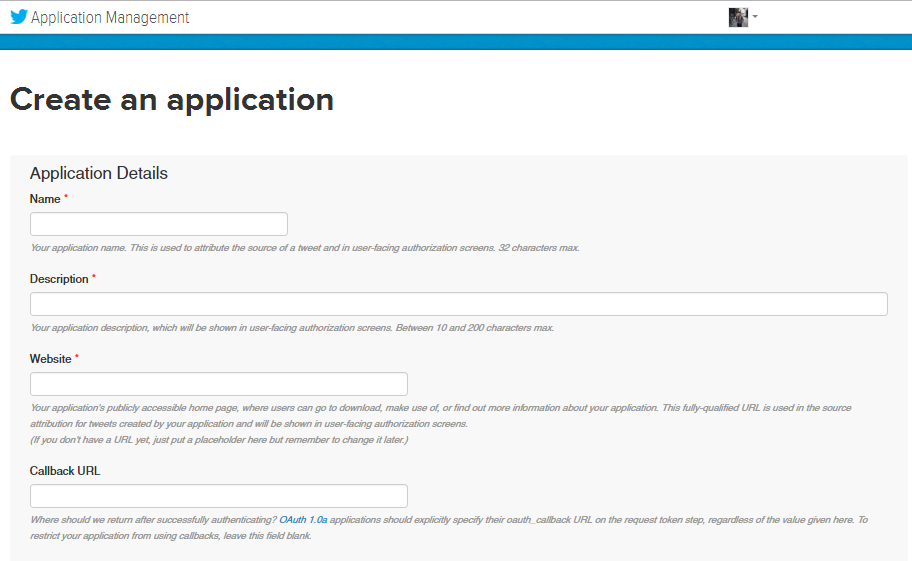
For the Name field, simply write a name for your application. It can be “MyApp” or anything. In the Description field, you can write something about your application so that you can be reminded later of what it does. Lastly, for the Website field, you can enter your own website, but if you don’t have any, https://www.site.com will suffice.
Note that we are not writing anything down in the Callback URL field. Leave that blank for now. Once you’re done, tick the agreement checkbox and click “Create your Twitter Application”
Once your application has already been created, a dashboard will appear in your browser. Go to “Keys and Access Tokens” tab and generate your consumer keys and access tokens if they’re not yet available. By the end of this process, we now have the following keys, and we’ll refer to them as the following:
- Consumer Key (API Key),
consumer_key - Consumer Secret (API Secret),
consumer_secret - Access Token,
access_token - Access Token Secret,
access_token_secret
Take note of these variables for we’ll use them later on.
Create the StreamListener class using tweepy
We wil create the listener class that will inherit from the StreamListener
object in tweepy. We’ll create a wrapper, and then define methods that will
be activated depending on what the listener is hearing. In our case, we’ll
build the on_status and on_error methods inside the StdOutListener
class. The structure of our listener class is very short and easy. In its
entirety, this is what it looks like:
class StdOutListener(StreamListener):
""" A listener handles tweets that are received from the stream.
This is a basic listener that just prints received tweets to stdout.
"""
def on_status(self, status):
print(status.text)
return True
def on_error(self, status_code):
if status_code == 420:
return False
- The method
on_statusis activated whenever a tweet has been heard. Its input is the variablestatus, which is the actual Tweet it heard plus the metadata. Here,statuscan be seen as an object with different parameters. For example,status.textis the actual tweet in UTF-8 encoding,status.favorite_countis the number of favorites the tweet has and so on. You can look for the different parameters here. - The method
on_errorserves as an error handler for our listener. Sometimes, Error 420 are being sent in our listener because of Twitter’s rate limit policy. Whenever this kind of error arrives, it will prompt our listener to disconnect.
As you can see, it is in the on_status method where we’ll put all the
manipulations required. This can include storing Tweets into the database and
other things. As long as we hear something through the listener, on_status
is executed and it does all the things we put into it.
Our listener class, StdOutListener(), can then be used in order to stream
tweets. In the same file (scraper.py), we write the following:
from __future__ import absolute_import, print_function
# Import modules
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
import dataset
from sqlalchemy.exc import ProgrammingError
# Your credentials go here
consumer_key = " "
consumer_secret = " "
access_token = " "
access_token_secret = " "
"""
The code for our listener class above goes here!
"""
if __name__ == '__main__':
l = StdOutListener()
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
stream = Stream(auth, l)
stream.filter(track=['github', 'tweepy'])
We simply import all our modules, and then plug in the credentials we
obtained in the earlier step. Remember to put the code for our listener
class right after (see comment). In our main function, we simply invoke
an instance of our listener, and then use the tweepy methods in order to
connect to our application.
Normally, it’s a good practice that you store your Twitter credentials, or anything that is private in a separate file away from your source code. I suggest storing them in a config.ini file, then accessing them using the ConfigParser module in Python.
We can then add filters in the way we stream using the stream.filter()
method. The track parameter is an array of keywords that will be listened
into. This means that as our listener is running, it will only listen to
tweets that contain the keywords below (logical OR).
You can actually try this one out right now. Just copy the code below, supply
your credentials, and then type python scraper.py in your cmd!
Take note! Depending on your machine, sometimes there are errors that will appear such as: <pre>charmap can’t encode character</pre> One very fast workaround that I don’t recommend, but you’ll find in most StackOverflow threads is to type <pre>chcp 65001</pre> in your console before running the scraper. The error often comes in the console and this solution is quite hack-ish and not much of a good practice. I suggest Dirk Stocker’s answer for this. Using a wrapper is much more scalable and gives you good practice early on. But if you think his solution is quite difficult, I won’t stop you from using chcp.
Save tweets into an SQL database
We will now extend our on_status method to include database storage. In
this case, it will look like this:
def on_status(self, status):
print(status.text)
if status.retweeted:
return
id_str = status.id_str
created = status.created_at
text = status.text
fav = status.favorite_count
name = status.user.screen_name
description = status.user.description
loc = status.user.location
user_created = status.user.created_at
followers = status.user.followers_count
table = db['myTable']
try:
table.insert(dict(
id_str=id_str,
created=created,
text=text,
fav_count=fav,
user_name=name,
user_description=description,
user_location=loc,
user_created=user_created,
user_followers=followers,
))
except ProgrammingError as err:
print(err)
As you can see, we’re accessing different parameters of the Tweet such as the
user ID of the one who created the Tweet, the number of favorites, the
location, and even the time it was created. We simply store them in different
variables so that we can access them easily. Next, we create a table named
myTable, and this is where we’ll store our Tweets. Using the dataset
library, we can simply do this by invoking the table.insert command and
supplying it with the dictionary made up of our Tweet parameters.
Lastly, don’t forget that we need to connect to our database, we do that by
adding another line in our main routine like below:
if __name__ == '__main__':
db = dataset.connect("sqlite:///tweets.db")
l = StdOutListener()
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
stream = Stream(auth, l)
stream.filter(track=['github', 'tweepy'])
We are then connecting to the database called tweets.db, and we’re doing
that in just a single line! As you can see, this is quite easy! We can now
start scraping our Twitter data! Again, just hit the console and type:
$ python scraper.py
If we want to end the stream, just press CTRL + C.
Convert database into a .csv file
In this section, we will then create another file, dumper.py. It is made up
of just four lines so here we go:
import dataset
db = dataset.connect("sqlite:///tweets.db")
result = db['myTable'].all()
dataset.freeze(result, format='csv', filename='tweets.csv')
Here, we are connecting again to the tweets database. We then retrieve the
values that can be found in our table myTable and store it in the variable
result. Afterwhich, we invoke the freeze command in order to “convert”
our database into a .csv file with the filename tweets.csv.
Thus, after scraping, we can then run this dumper using the following command:
$ python dumper.py
This will then generate a file in the same directory as this code.
I hope that you were able to use this little tutorial in streaming your Tweets! Data scraping is one of the most useful tools in data science and getting sentiments from Twitter can prove to be valuable with its wide-range of applications. The final code for the scraper can be seen in this gist.